 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDP-CROWN: Efficient Bound Propagation for Neural Network Verification with Tightness of Semidefinite Programming
Jun 07, 2025Neural network verifiers based on linear bound propagation scale impressively to massive models but can be surprisingly loose when neuron coupling is crucial. Conversely, semidefinite programming (SDP) verifiers capture inter-neuron coupling naturally, but their cubic complexity restricts them to only small models. In this paper, we propose SDP-CROWN, a novel hybrid verification framework that combines the tightness of SDP relaxations with the scalability of bound-propagation verifiers. At the core of SDP-CROWN is a new linear bound, derived via SDP principles, that explicitly captures $\ell_{2}$-norm-based inter-neuron coupling while adding only one extra parameter per layer. This bound can be integrated seamlessly into any linear bound-propagation pipeline, preserving the inherent scalability of such methods yet significantly improving tightness. In theory, we prove that our inter-neuron bound can be up to a factor of $\sqrt{n}$ tighter than traditional per-neuron bounds. In practice, when incorporated into the state-of-the-art $\alpha$-CROWN verifier, we observe markedly improved verification performance on large models with up to 65 thousand neurons and 2.47 million parameters, achieving tightness that approaches that of costly SDP-based methods.
Fast and Minimax Optimal Estimation of Low-Rank Matrices via Non-Convex Gradient Descent
May 26, 2023We study the problem of estimating a low-rank matrix from noisy measurements, with the specific goal of achieving minimax optimal error. In practice, the problem is commonly solved using non-convex gradient descent, due to its ability to scale to large-scale real-world datasets. In theory, non-convex gradient descent is capable of achieving minimax error. But in practice, it often converges extremely slowly, such that it cannot even deliver estimations of modest accuracy within reasonable time. On the other hand, methods that improve the convergence of non-convex gradient descent, through rescaling or preconditioning, also greatly amplify the measurement noise, resulting in estimations that are orders of magnitude less accurate than what is theoretically achievable with minimax optimal error. In this paper, we propose a slight modification to the usual non-convex gradient descent method that remedies the issue of slow convergence, while provably preserving its minimax optimality. Our proposed algorithm has essentially the same per-iteration cost as non-convex gradient descent, but is guaranteed to converge to minimax error at a linear rate that is immune to ill-conditioning. Using our proposed algorithm, we reconstruct a 60 megapixel dataset for a medical imaging application, and observe significantly decreased reconstruction error compared to previous approaches.
Overcoming the Convex Relaxation Barrier for Neural Network Verification via Nonconvex Low-Rank Semidefinite Relaxations
Nov 30, 2022To rigorously certify the robustness of neural networks to adversarial perturbations, most state-of-the-art techniques rely on a triangle-shaped linear programming (LP) relaxation of the ReLU activation. While the LP relaxation is exact for a single neuron, recent results suggest that it faces an inherent "convex relaxation barrier" as additional activations are added, and as the attack budget is increased. In this paper, we propose a nonconvex relaxation for the ReLU relaxation, based on a low-rank restriction of a semidefinite programming (SDP) relaxation. We show that the nonconvex relaxation has a similar complexity to the LP relaxation, but enjoys improved tightness that is comparable to the much more expensive SDP relaxation. Despite nonconvexity, we prove that the verification problem satisfies constraint qualification, and therefore a Riemannian staircase approach is guaranteed to compute a near-globally optimal solution in polynomial time. Our experiments provide evidence that our nonconvex relaxation almost completely overcome the "convex relaxation barrier" faced by the LP relaxation.
Accelerating SGD for Highly Ill-Conditioned Huge-Scale Online Matrix Completion
Aug 24, 2022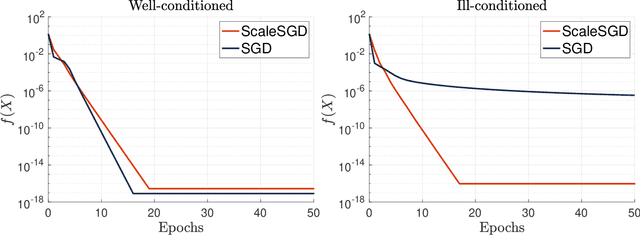
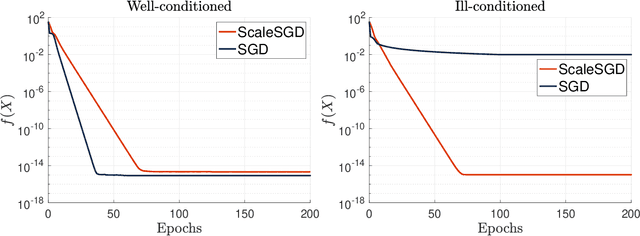
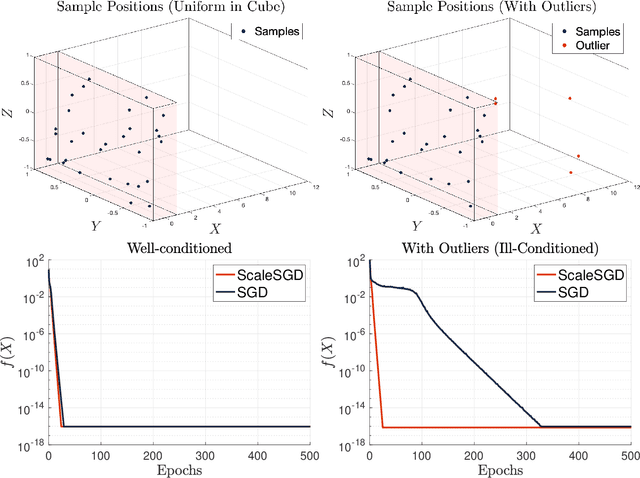
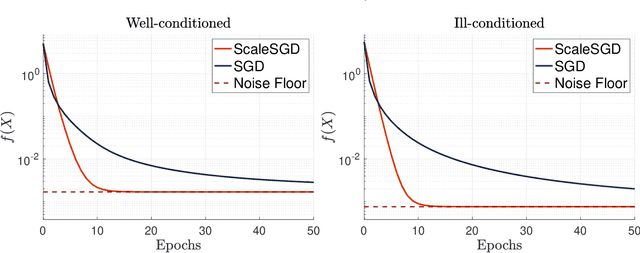
The matrix completion problem seeks to recover a $d\times d$ ground truth matrix of low rank $r\ll d$ from observations of its individual elements. Real-world matrix completion is often a huge-scale optimization problem, with $d$ so large that even the simplest full-dimension vector operations with $O(d)$ time complexity become prohibitively expensive. Stochastic gradient descent (SGD) is one of the few algorithms capable of solving matrix completion on a huge scale, and can also naturally handle streaming data over an evolving ground truth. Unfortunately, SGD experiences a dramatic slow-down when the underlying ground truth is ill-conditioned; it requires at least $O(\kappa\log(1/\epsilon))$ iterations to get $\epsilon$-close to ground truth matrix with condition number $\kappa$. In this paper, we propose a preconditioned version of SGD that preserves all the favorable practical qualities of SGD for huge-scale online optimization while also making it agnostic to $\kappa$. For a symmetric ground truth and the Root Mean Square Error (RMSE) loss, we prove that the preconditioned SGD converges to $\epsilon$-accuracy in $O(\log(1/\epsilon))$ iterations, with a rapid linear convergence rate as if the ground truth were perfectly conditioned with $\kappa=1$. In our numerical experiments, we observe a similar acceleration for ill-conditioned matrix completion under the 1-bit cross-entropy loss, as well as pairwise losses such as the Bayesian Personalized Ranking (BPR) loss.