 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating SGD for Highly Ill-Conditioned Huge-Scale Online Matrix Completion
Paper and Code
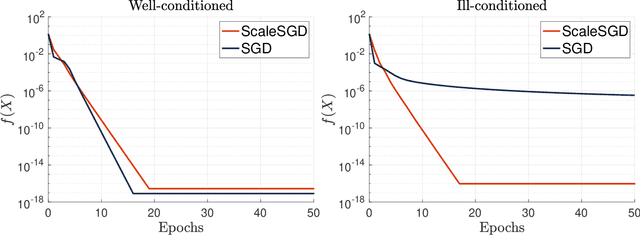
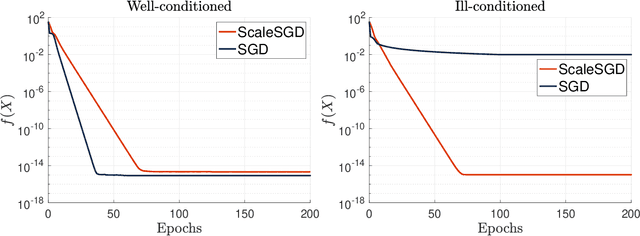
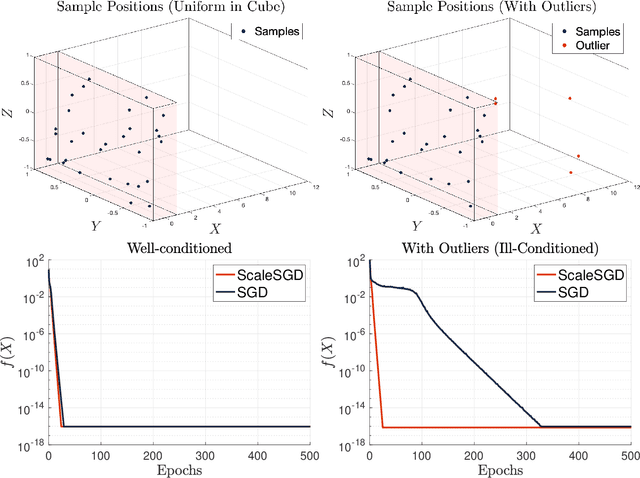
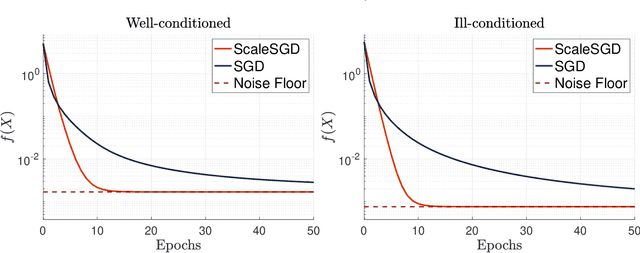
The matrix completion problem seeks to recover a $d\times d$ ground truth matrix of low rank $r\ll d$ from observations of its individual elements. Real-world matrix completion is often a huge-scale optimization problem, with $d$ so large that even the simplest full-dimension vector operations with $O(d)$ time complexity become prohibitively expensive. Stochastic gradient descent (SGD) is one of the few algorithms capable of solving matrix completion on a huge scale, and can also naturally handle streaming data over an evolving ground truth. Unfortunately, SGD experiences a dramatic slow-down when the underlying ground truth is ill-conditioned; it requires at least $O(\kappa\log(1/\epsilon))$ iterations to get $\epsilon$-close to ground truth matrix with condition number $\kappa$. In this paper, we propose a preconditioned version of SGD that preserves all the favorable practical qualities of SGD for huge-scale online optimization while also making it agnostic to $\kappa$. For a symmetric ground truth and the Root Mean Square Error (RMSE) loss, we prove that the preconditioned SGD converges to $\epsilon$-accuracy in $O(\log(1/\epsilon))$ iterations, with a rapid linear convergence rate as if the ground truth were perfectly conditioned with $\kappa=1$. In our numerical experiments, we observe a similar acceleration for ill-conditioned matrix completion under the 1-bit cross-entropy loss, as well as pairwise losses such as the Bayesian Personalized Ranking (BPR) loss.