 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspecting Explainability of Transformer Models with Additional Statistical Information
Nov 19, 2023
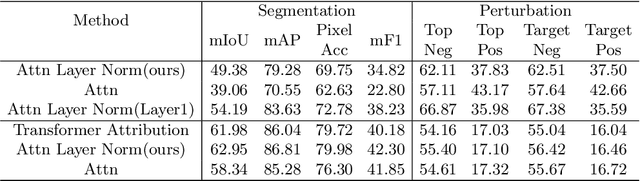
Transformer becomes more popular in the vision domain in recent years so there is a need for finding an effective way to interpret the Transformer model by visualizing it. In recent work, Chefer et al. can visualize the Transformer on vision and multi-modal tasks effectively by combining attention layers to show the importance of each image patch. However, when applying to other variants of Transformer such as the Swin Transformer, this method can not focus on the predicted object. Our method, by considering the statistics of tokens in layer normalization layers, shows a great ability to interpret the explainability of Swin Transformer and ViT.
TransReg: Cross-transformer as auto-registration module for multi-view mammogram mass detection
Nov 09, 2023

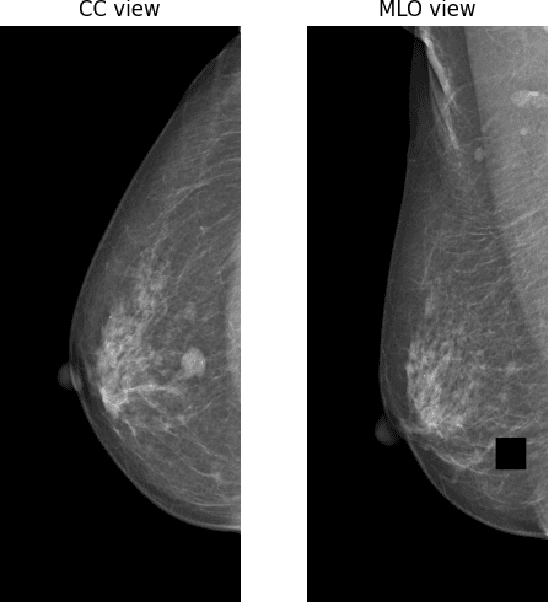

Screening mammography is the most widely used method for early breast cancer detection, significantly reducing mortality rates. The integration of information from multi-view mammograms enhances radiologists' confidence and diminishes false-positive rates since they can examine on dual-view of the same breast to cross-reference the existence and location of the lesion. Inspired by this, we present TransReg, a Computer-Aided Detection (CAD) system designed to exploit the relationship between craniocaudal (CC), and mediolateral oblique (MLO) views. The system includes cross-transformer to model the relationship between the region of interest (RoIs) extracted by siamese Faster RCNN network for mass detection problems. Our work is the first time cross-transformer has been integrated into an object detection framework to model the relation between ipsilateral views. Our experimental evaluation on DDSM and VinDr-Mammo datasets shows that our TransReg, equipped with SwinT as a feature extractor achieves state-of-the-art performance. Specifically, at the false positive rate per image at 0.5, TransReg using SwinT gets a recall at 83.3% for DDSM dataset and 79.7% for VinDr-Mammo dataset. Furthermore, we conduct a comprehensive analysis to demonstrate that cross-transformer can function as an auto-registration module, aligning the masses in dual-view and utilizing this information to inform final predictions. It is a replication diagnostic workflow of expert radiologists
VinDr-RibCXR: A Benchmark Dataset for Automatic Segmentation and Labeling of Individual Ribs on Chest X-rays
Jul 03, 2021
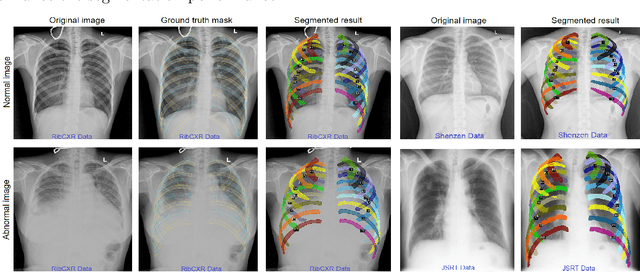
We introduce a new benchmark dataset, namely VinDr-RibCXR, for automatic segmentation and labeling of individual ribs from chest X-ray (CXR) scans. The VinDr-RibCXR contains 245 CXRs with corresponding ground truth annotations provided by human experts. A set of state-of-the-art segmentation models are trained on 196 images from the VinDr-RibCXR to segment and label 20 individual ribs. Our best performing model obtains a Dice score of 0.834 (95% CI, 0.810--0.853) on an independent test set of 49 images. Our study, therefore, serves as a proof of concept and baseline performance for future research.