Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspecting Explainability of Transformer Models with Additional Statistical Information
Paper and Code
Nov 19, 2023
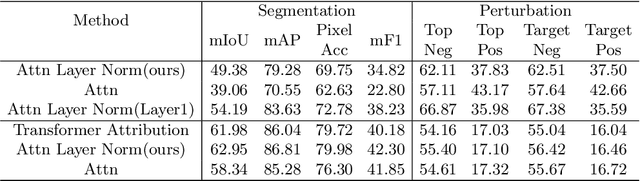
Transformer becomes more popular in the vision domain in recent years so there is a need for finding an effective way to interpret the Transformer model by visualizing it. In recent work, Chefer et al. can visualize the Transformer on vision and multi-modal tasks effectively by combining attention layers to show the importance of each image patch. However, when applying to other variants of Transformer such as the Swin Transformer, this method can not focus on the predicted object. Our method, by considering the statistics of tokens in layer normalization layers, shows a great ability to interpret the explainability of Swin Transformer and ViT.
View paper on