 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXPATS: A Toolkit for Explainable Automated Text Scoring
Apr 07, 2021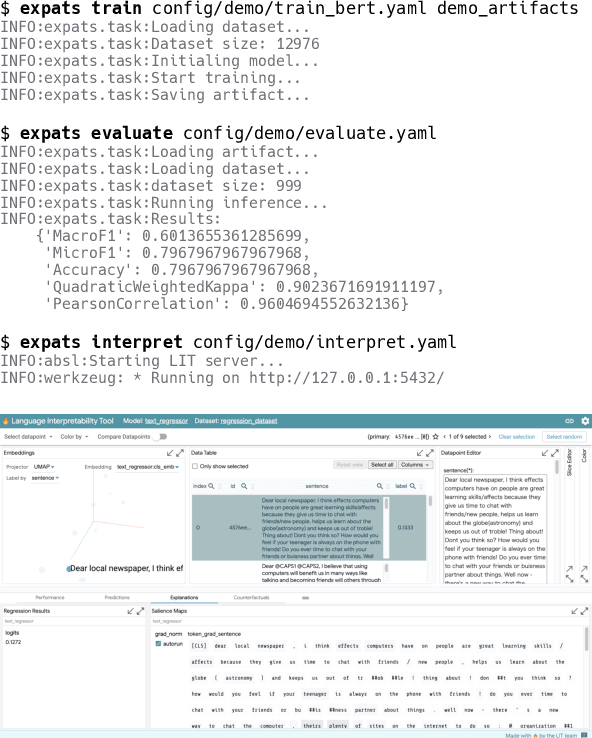

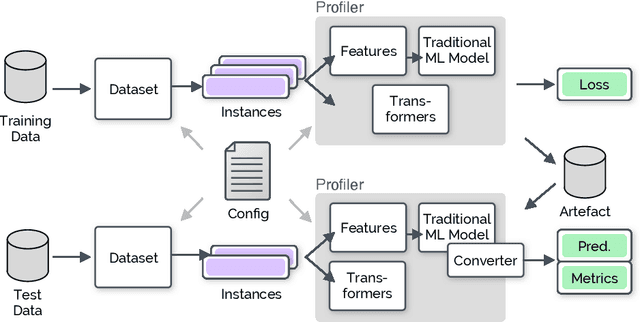
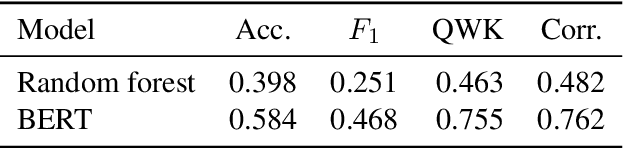
Automated text scoring (ATS) tasks, such as automated essay scoring and readability assessment, are important educational applications of natural language processing. Due to their interpretability of models and predictions, traditional machine learning (ML) algorithms based on handcrafted features are still in wide use for ATS tasks. Practitioners often need to experiment with a variety of models (including deep and traditional ML ones), features, and training objectives (regression and classification), although modern deep learning frameworks such as PyTorch require deep ML expertise to fully utilize. In this paper, we present EXPATS, an open-source framework to allow its users to develop and experiment with different ATS models quickly by offering flexible components, an easy-to-use configuration system, and the command-line interface. The toolkit also provides seamless integration with the Language Interpretability Tool (LIT) so that one can interpret and visualize models and their predictions. We also describe two case studies where we build ATS models quickly with minimal engineering efforts. The toolkit is available at \url{https://github.com/octanove/expats}.
Reduction of Parameter Redundancy in Biaffine Classifiers with Symmetric and Circulant Weight Matrices
Oct 18, 2018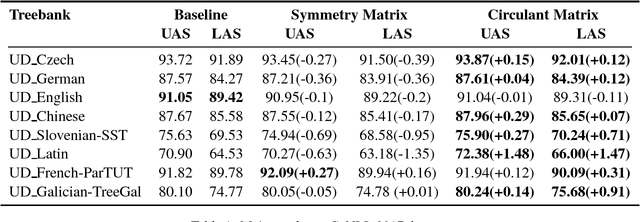

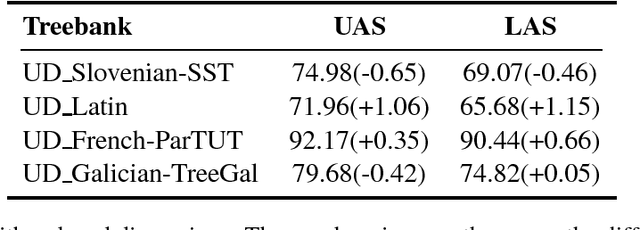

Currently, the biaffine classifier has been attracting attention as a method to introduce an attention mechanism into the modeling of binary relations. For instance, in the field of dependency parsing, the Deep Biaffine Parser by Dozat and Manning has achieved state-of-the-art performance as a graph-based dependency parser on the English Penn Treebank and CoNLL 2017 shared task. On the other hand, it is reported that parameter redundancy in the weight matrix in biaffine classifiers, which has O(n^2) parameters, results in overfitting (n is the number of dimensions). In this paper, we attempted to reduce the parameter redundancy by assuming either symmetry or circularity of weight matrices. In our experiments on the CoNLL 2017 shared task dataset, our model achieved better or comparable accuracy on most of the treebanks with more than 16% parameter reduction.
Data-dependent Learning of Symmetric/Antisymmetric Relations for Knowledge Base Completion
Aug 25, 2018


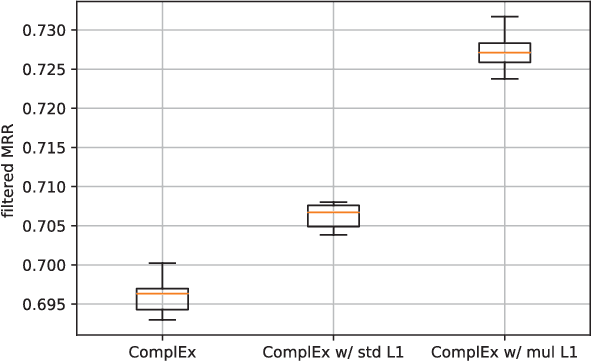
Embedding-based methods for knowledge base completion (KBC) learn representations of entities and relations in a vector space, along with the scoring function to estimate the likelihood of relations between entities. The learnable class of scoring functions is designed to be expressive enough to cover a variety of real-world relations, but this expressive comes at the cost of an increased number of parameters. In particular, parameters in these methods are superfluous for relations that are either symmetric or antisymmetric. To mitigate this problem, we propose a new L1 regularizer for Complex Embeddings, which is one of the state-of-the-art embedding-based methods for KBC. This regularizer promotes symmetry or antisymmetry of the scoring function on a relation-by-relation basis, in accordance with the observed data. Our empirical evaluation shows that the proposed method outperforms the original Complex Embeddings and other baseline methods on the FB15k dataset.