 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA SARS-CoV-2 Interaction Dataset and VHH Sequence Corpus for Antibody Language Models
May 29, 2024

Antibodies are crucial proteins produced by the immune system to eliminate harmful foreign substances and have become pivotal therapeutic agents for treating human diseases. To accelerate the discovery of antibody therapeutics, there is growing interest in constructing language models using antibody sequences. However, the applicability of pre-trained language models for antibody discovery has not been thoroughly evaluated due to the scarcity of labeled datasets. To overcome these limitations, we introduce AVIDa-SARS-CoV-2, a dataset featuring the antigen-variable domain of heavy chain of heavy chain antibody (VHH) interactions obtained from two alpacas immunized with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) spike proteins. AVIDa-SARS-CoV-2 includes binary labels indicating the binding or non-binding of diverse VHH sequences to 12 SARS-CoV-2 mutants, such as the Delta and Omicron variants. Furthermore, we release VHHCorpus-2M, a pre-training dataset for antibody language models, containing over two million VHH sequences. We report benchmark results for predicting SARS-CoV-2-VHH binding using VHHBERT pre-trained on VHHCorpus-2M and existing general protein and antibody-specific pre-trained language models. These results confirm that AVIDa-SARS-CoV-2 provides valuable benchmarks for evaluating the representation capabilities of antibody language models for binding prediction, thereby facilitating the development of AI-driven antibody discovery. The datasets are available at https://datasets.cognanous.com.
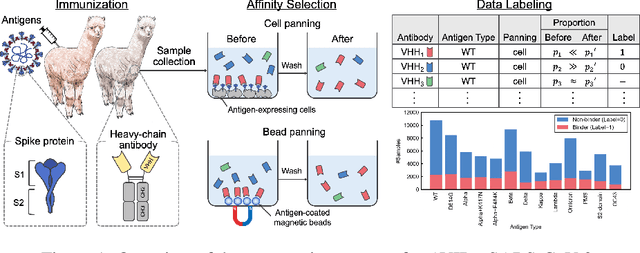
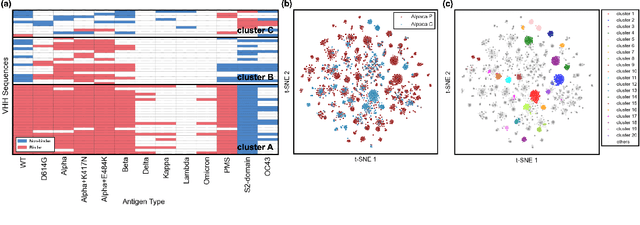
AVIDa-hIL6: A Large-Scale VHH Dataset Produced from an Immunized Alpaca for Predicting Antigen-Antibody Interactions
Jun 06, 2023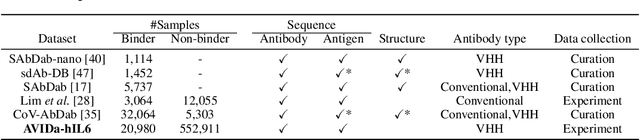
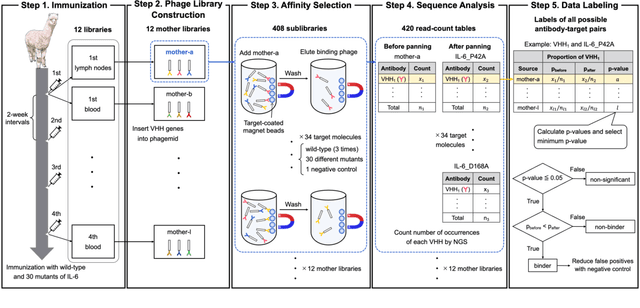
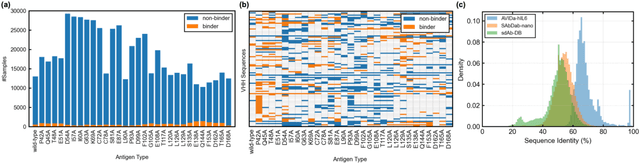

Antibodies have become an important class of therapeutic agents to treat human diseases. To accelerate therapeutic antibody discovery, computational methods, especially machine learning, have attracted considerable interest for predicting specific interactions between antibody candidates and target antigens such as viruses and bacteria. However, the publicly available datasets in existing works have notable limitations, such as small sizes and the lack of non-binding samples and exact amino acid sequences. To overcome these limitations, we have developed AVIDa-hIL6, a large-scale dataset for predicting antigen-antibody interactions in the variable domain of heavy chain of heavy chain antibodies (VHHs), produced from an alpaca immunized with the human interleukin-6 (IL-6) protein, as antigens. By leveraging the simple structure of VHHs, which facilitates identification of full-length amino acid sequences by DNA sequencing technology, AVIDa-hIL6 contains 573,891 antigen-VHH pairs with amino acid sequences. All the antigen-VHH pairs have reliable labels for binding or non-binding, as generated by a novel labeling method. Furthermore, via introduction of artificial mutations, AVIDa-hIL6 contains 30 different mutants in addition to wild-type IL-6 protein. This characteristic provides opportunities to develop machine learning models for predicting changes in antibody binding by antigen mutations. We report experimental benchmark results on AVIDa-hIL6 by using neural network-based baseline models. The results indicate that the existing models have potential, but further research is needed to generalize them to predict effective antibodies against unknown mutants. The dataset is available at https://avida-hil6.cognanous.com.