 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Evaluation of Generative Adversarial Networks for Time Series Data
Dec 23, 2019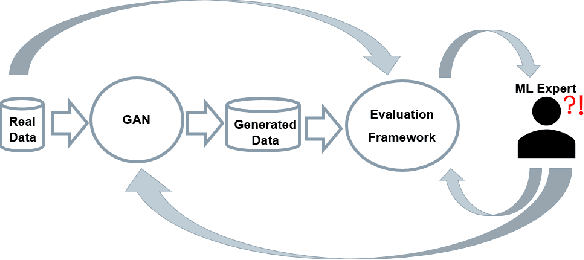
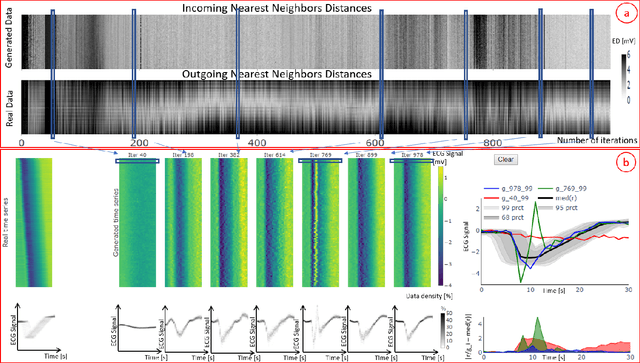
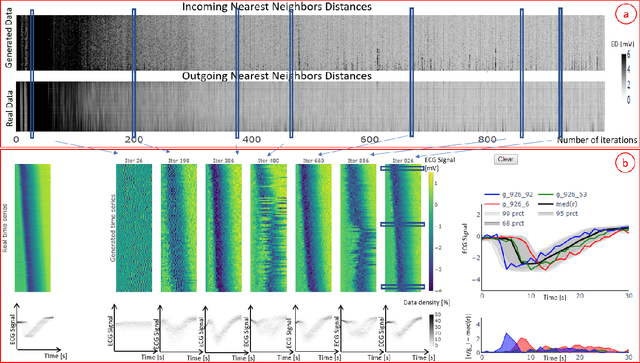
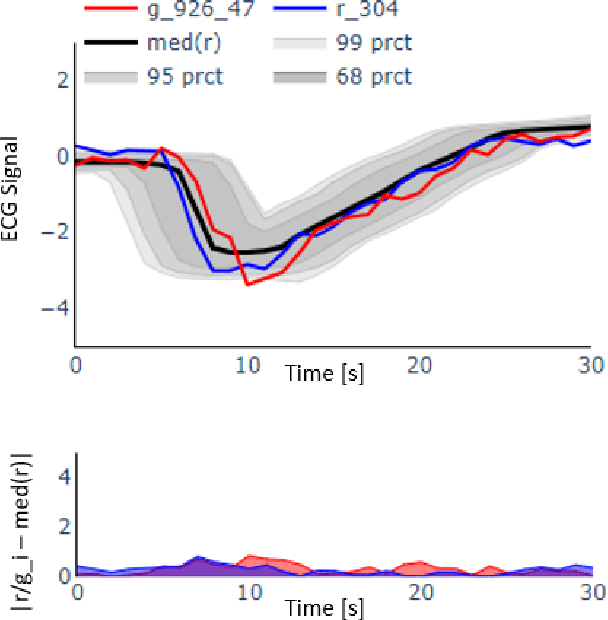
A crucial factor to trust Machine Learning (ML) algorithm decisions is a good representation of its application field by the training dataset. This is particularly true when parts of the training data have been artificially generated to overcome common training problems such as lack of data or imbalanced dataset. Over the last few years, Generative Adversarial Networks (GANs) have shown remarkable results in generating realistic data. However, this ML approach lacks an objective function to evaluate the quality of the generated data. Numerous GAN applications focus on generating image data mostly because they can be easily evaluated by a human eye. Less efforts have been made to generate time series data. Assessing their quality is more complicated, particularly for technical data. In this paper, we propose a human-centered approach supporting a ML or domain expert to accomplish this task using Visual Analytics (VA) techniques. The presented approach consists of two views, namely a GAN Iteration View showing similarity metrics between real and generated data over the iterations of the generation process and a Detailed Comparative View equipped with different time series visualizations such as TimeHistograms, to compare the generated data at different iteration steps. Starting from the GAN Iteration View, the user can choose suitable iteration steps for detailed inspection. We evaluate our approach with a usage scenario that enabled an efficient comparison of two different GAN models.
Towards a Rigorous Evaluation of XAI Methods on Time Series
Sep 17, 2019

Explainable Artificial Intelligence (XAI) methods are typically deployed to explain and debug black-box machine learning models. However, most proposed XAI methods are black-boxes themselves and designed for images. Thus, they rely on visual interpretability to evaluate and prove explanations. In this work, we apply XAI methods previously used in the image and text-domain on time series. We present a methodology to test and evaluate various XAI methods on time series by introducing new verification techniques to incorporate the temporal dimension. We further conduct preliminary experiments to assess the quality of selected XAI method explanations with various verification methods on a range of datasets and inspecting quality metrics on it. We demonstrate that in our initial experiments, SHAP works robust for all models, but others like DeepLIFT, LRP, and Saliency Maps work better with specific architectures.
* 5 Pages 1 Figure 1 Table 1 Page Reference - 2019 ICCV Workshop on Interpreting and Explaining Visual Artificial Intelligence Models