 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClickSAM: Fine-tuning Segment Anything Model using click prompts for ultrasound image segmentation
Feb 25, 2024The newly released Segment Anything Model (SAM) is a popular tool used in image processing due to its superior segmentation accuracy, variety of input prompts, training capabilities, and efficient model design. However, its current model is trained on a diverse dataset not tailored to medical images, particularly ultrasound images. Ultrasound images tend to have a lot of noise, making it difficult to segment out important structures. In this project, we developed ClickSAM, which fine-tunes the Segment Anything Model using click prompts for ultrasound images. ClickSAM has two stages of training: the first stage is trained on single-click prompts centered in the ground-truth contours, and the second stage focuses on improving the model performance through additional positive and negative click prompts. By comparing the first stage predictions to the ground-truth masks, true positive, false positive, and false negative segments are calculated. Positive clicks are generated using the true positive and false negative segments, and negative clicks are generated using the false positive segments. The Centroidal Voronoi Tessellation algorithm is then employed to collect positive and negative click prompts in each segment that are used to enhance the model performance during the second stage of training. With click-train methods, ClickSAM exhibits superior performance compared to other existing models for ultrasound image segmentation.
Unsupervised Image to Image Translation for Multiple Retinal Pathology Synthesis in Optical Coherence Tomography Scans
Dec 11, 2021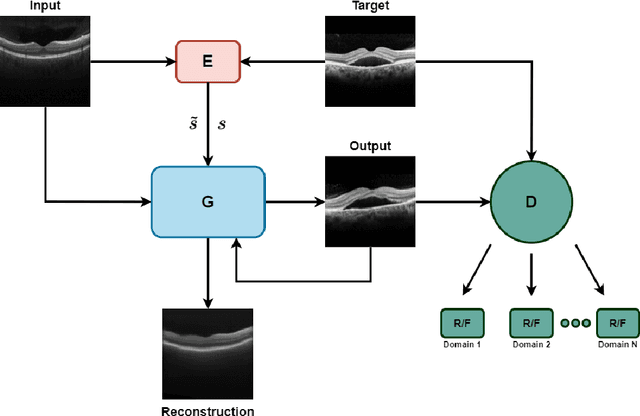
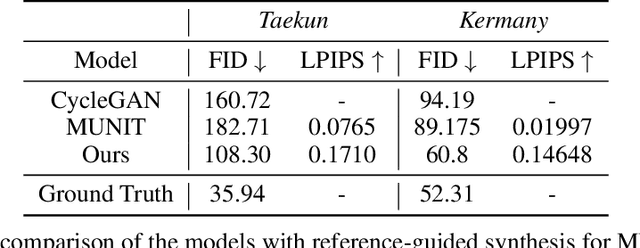
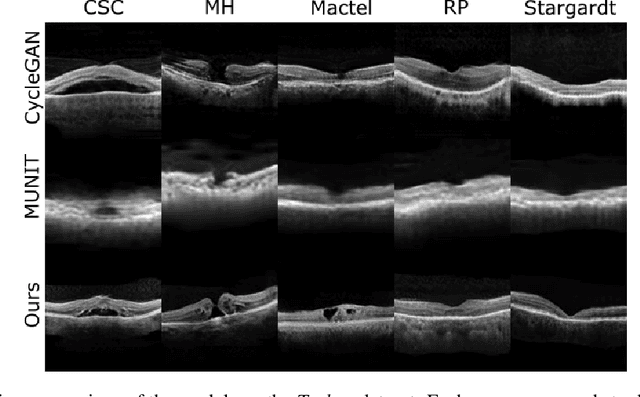
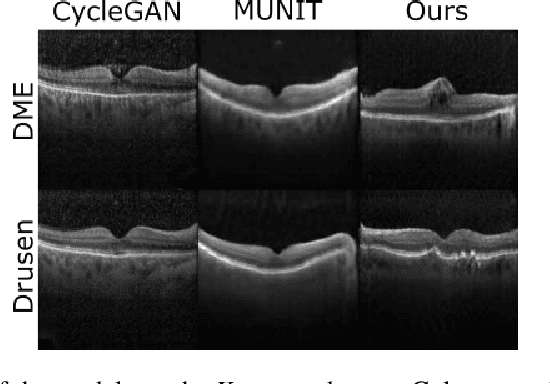
Image to Image Translation (I2I) is a challenging computer vision problem used in numerous domains for multiple tasks. Recently, ophthalmology became one of the major fields where the application of I2I is increasing rapidly. One such application is the generation of synthetic retinal optical coherence tomographic (OCT) scans. Existing I2I methods require training of multiple models to translate images from normal scans to a specific pathology: limiting the use of these models due to their complexity. To address this issue, we propose an unsupervised multi-domain I2I network with pre-trained style encoder that translates retinal OCT images in one domain to multiple domains. We assume that the image splits into domain-invariant content and domain-specific style codes, and pre-train these style codes. The performed experiments show that the proposed model outperforms state-of-the-art models like MUNIT and CycleGAN synthesizing diverse pathological scans.
A Deep Learning Approach for Masking Fetal Gender in Ultrasound Images
Sep 14, 2021
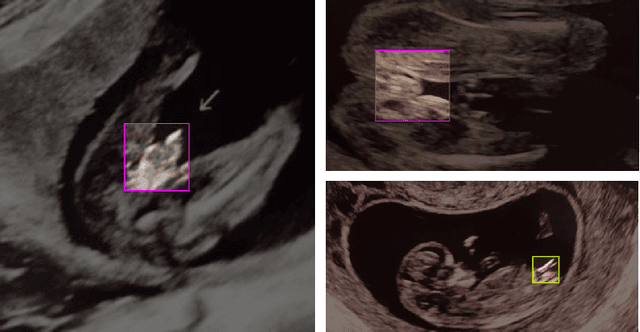
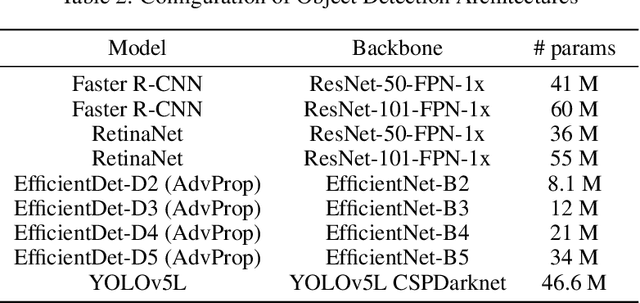
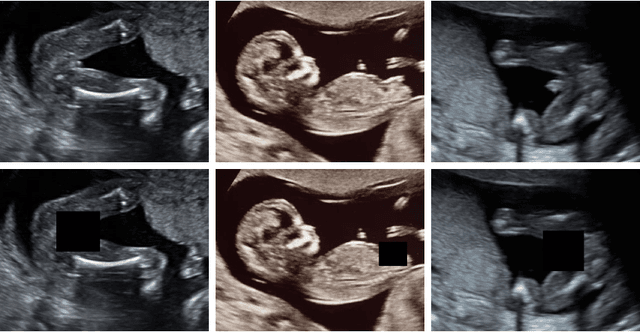
Ultrasound (US) imaging is highly effective with regards to both cost and versatility in real-time diagnosis; however, determination of fetal gender by US scan in the early stages of pregnancy is also a cause of sex-selective abortion. This work proposes a deep learning object detection approach to accurately mask fetal gender in US images in order to increase the accessibility of the technology. We demonstrate how the YOLOv5L architecture exhibits superior performance relative to other object detection models on this task. Our model achieves 45.8% AP[0.5:0.95], 92% F1-score and 0.006 False Positive Per Image rate on our test set. Furthermore, we introduce a bounding box delay rule based on frame-to-frame structural similarity to reduce the false negative rate by 85%, further improving masking reliability.