 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Image to Image Translation for Multiple Retinal Pathology Synthesis in Optical Coherence Tomography Scans
Paper and Code
Dec 11, 2021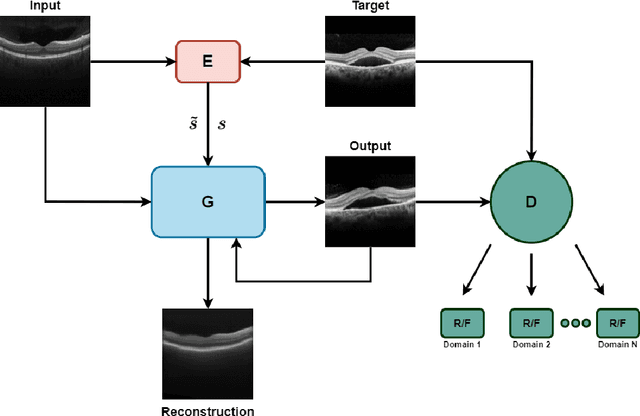
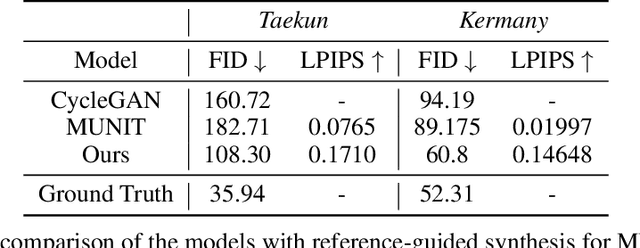
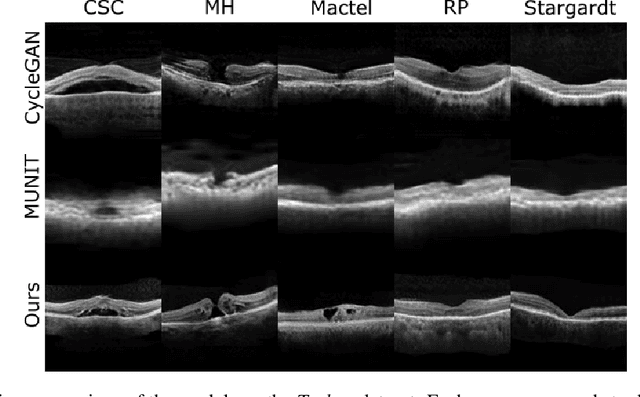
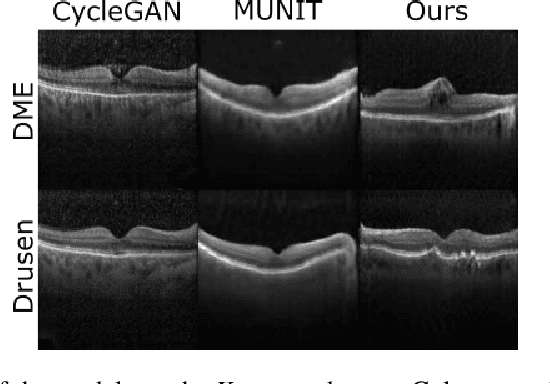
Image to Image Translation (I2I) is a challenging computer vision problem used in numerous domains for multiple tasks. Recently, ophthalmology became one of the major fields where the application of I2I is increasing rapidly. One such application is the generation of synthetic retinal optical coherence tomographic (OCT) scans. Existing I2I methods require training of multiple models to translate images from normal scans to a specific pathology: limiting the use of these models due to their complexity. To address this issue, we propose an unsupervised multi-domain I2I network with pre-trained style encoder that translates retinal OCT images in one domain to multiple domains. We assume that the image splits into domain-invariant content and domain-specific style codes, and pre-train these style codes. The performed experiments show that the proposed model outperforms state-of-the-art models like MUNIT and CycleGAN synthesizing diverse pathological scans.