 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUralic Language Identification (ULI) 2020 shared task dataset and the Wanca 2017 corpus
Aug 27, 2020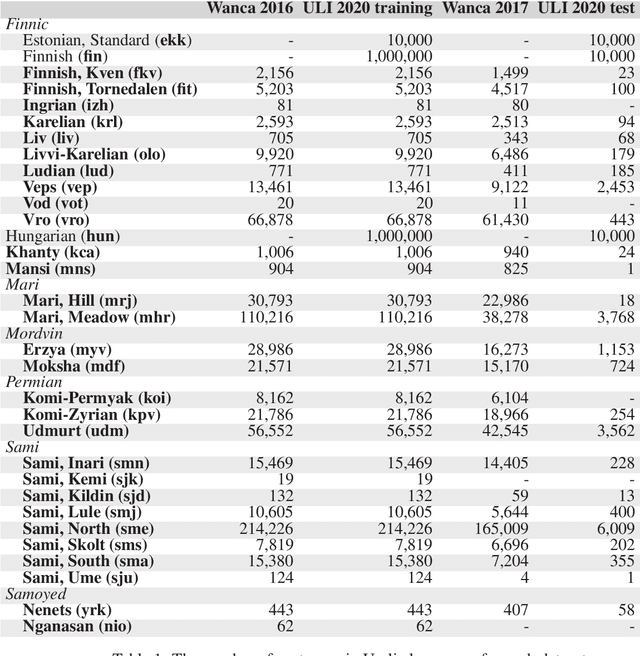

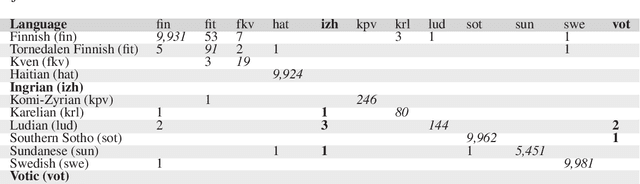
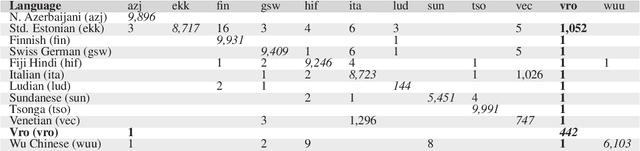
This article introduces the Wanca 2017 corpus of texts crawled from the internet from which the sentences in rare Uralic languages for the use of the Uralic Language Identification (ULI) 2020 shared task were collected. We describe the ULI dataset and how it was constructed using the Wanca 2017 corpus and texts in different languages from the Leipzig corpora collection. We also provide baseline language identification experiments conducted using the ULI 2020 dataset.
Language Model Adaptation for Language and Dialect Identification of Text
Mar 26, 2019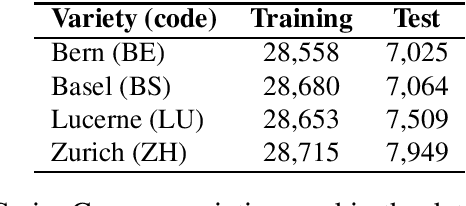
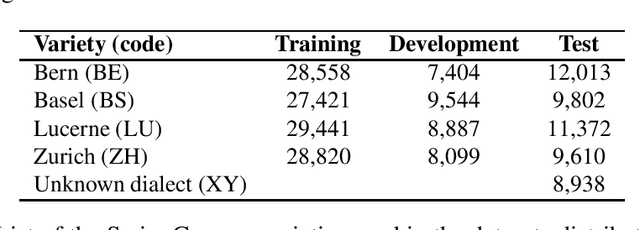
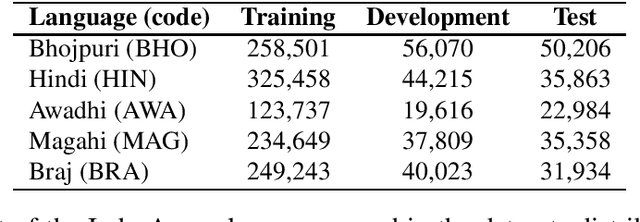
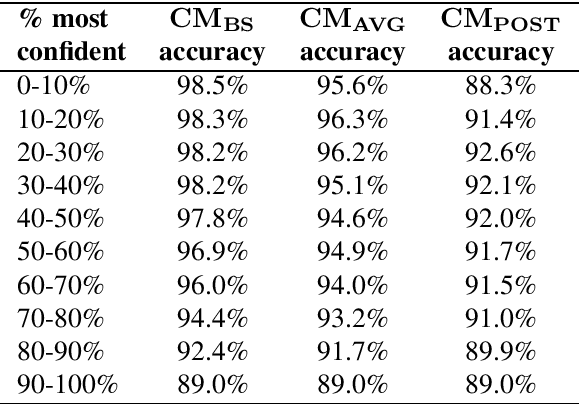
This article describes an unsupervised language model adaptation approach that can be used to enhance the performance of language identification methods. The approach is applied to a current version of the HeLI language identification method, which is now called HeLI 2.0. We describe the HeLI 2.0 method in detail. The resulting system is evaluated using the datasets from the German dialect identification and Indo-Aryan language identification shared tasks of the VarDial workshops 2017 and 2018. The new approach with language identification provides considerably higher F1-scores than the previous HeLI method or the other systems which participated in the shared tasks. The results indicate that unsupervised language model adaptation should be considered as an option in all language identification tasks, especially in those where encountering out-of-domain data is likely.
Language and Dialect Identification of Cuneiform Texts
Mar 13, 2019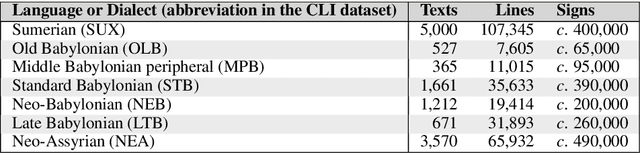
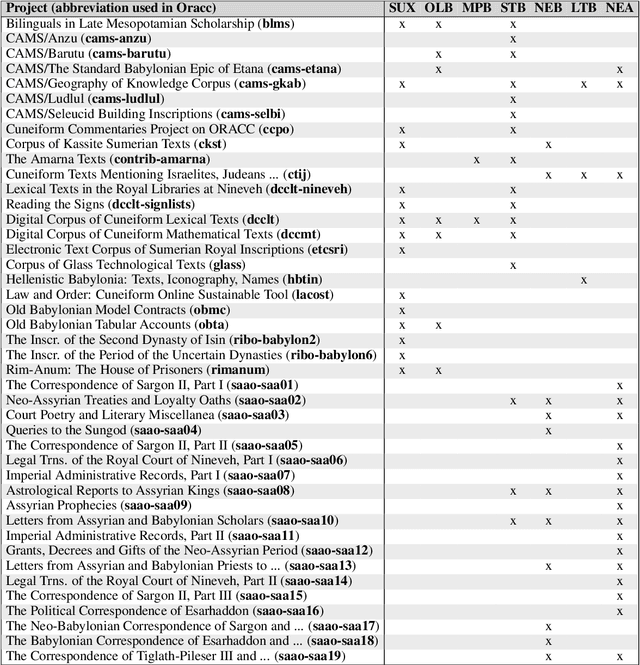

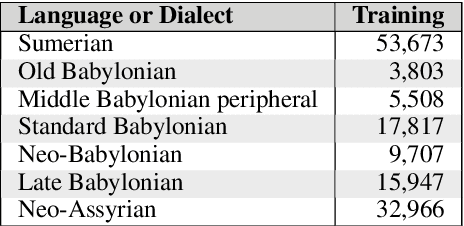
This article introduces a corpus of cuneiform texts from which the dataset for the use of the Cuneiform Language Identification (CLI) 2019 shared task was derived as well as some preliminary language identification experiments conducted using that corpus. We also describe the CLI dataset and how it was derived from the corpus. In addition, we provide some baseline language identification results using the CLI dataset. To the best of our knowledge, the experiments detailed here are the first time automatic language identification methods have been used on cuneiform data.