 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Adaptation for Language and Dialect Identification of Text
Paper and Code
Mar 26, 2019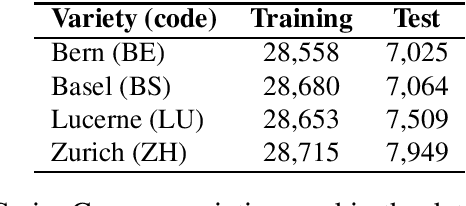
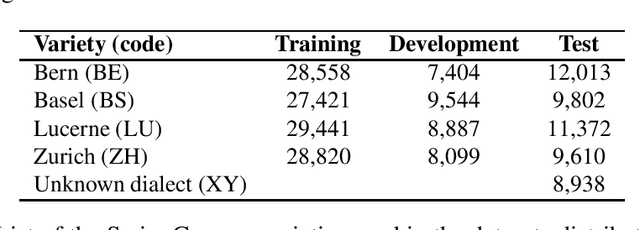
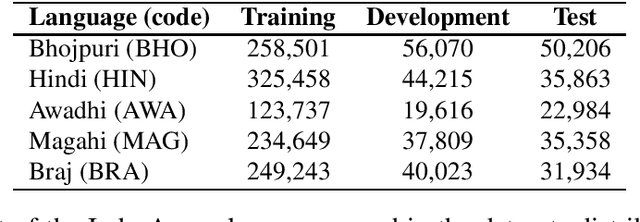
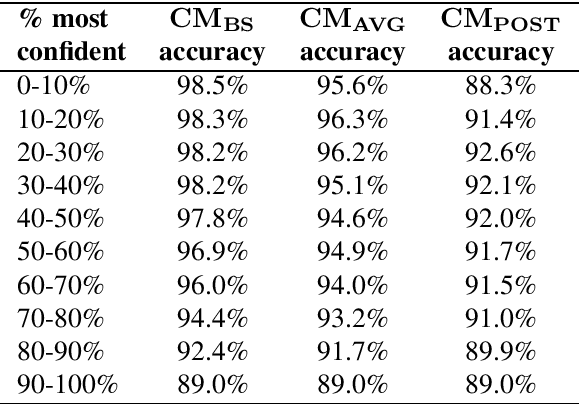
This article describes an unsupervised language model adaptation approach that can be used to enhance the performance of language identification methods. The approach is applied to a current version of the HeLI language identification method, which is now called HeLI 2.0. We describe the HeLI 2.0 method in detail. The resulting system is evaluated using the datasets from the German dialect identification and Indo-Aryan language identification shared tasks of the VarDial workshops 2017 and 2018. The new approach with language identification provides considerably higher F1-scores than the previous HeLI method or the other systems which participated in the shared tasks. The results indicate that unsupervised language model adaptation should be considered as an option in all language identification tasks, especially in those where encountering out-of-domain data is likely.