Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUralic Language Identification (ULI) 2020 shared task dataset and the Wanca 2017 corpus
Paper and Code
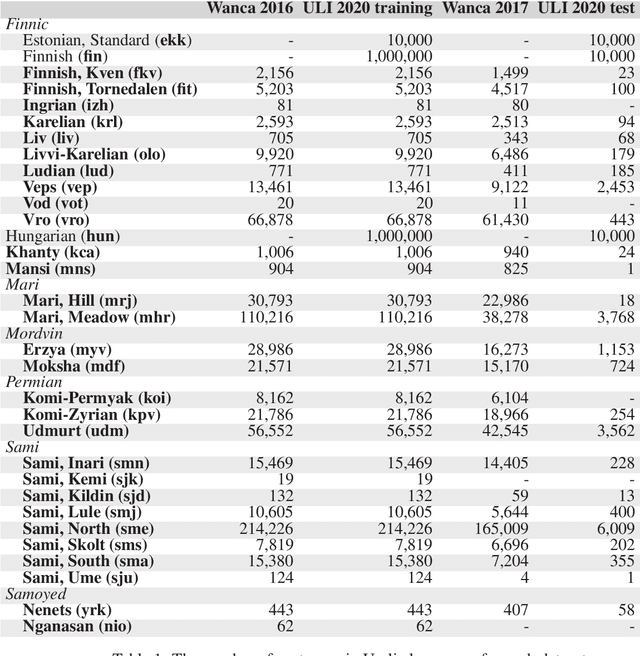

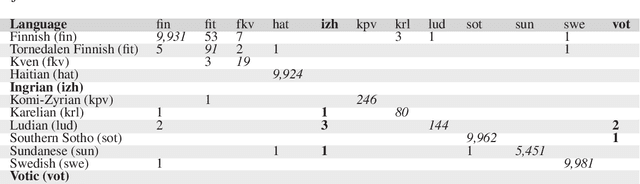
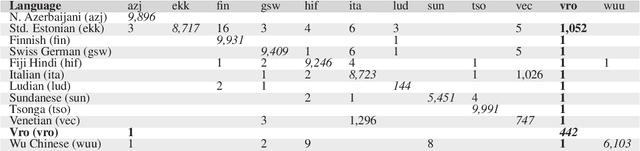
This article introduces the Wanca 2017 corpus of texts crawled from the internet from which the sentences in rare Uralic languages for the use of the Uralic Language Identification (ULI) 2020 shared task were collected. We describe the ULI dataset and how it was constructed using the Wanca 2017 corpus and texts in different languages from the Leipzig corpora collection. We also provide baseline language identification experiments conducted using the ULI 2020 dataset.
View paper on