 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Resolution End-to-End Deep Neural Network for Optimizing Latency-Accuracy Tradeoff in Autonomous Driving
May 27, 2026Latency-accuracy tradeoffs are fundamental in real-time applications of deep neural networks (DNNs) for cyber-physical systems. In autonomous driving, in particular, safety depends on both prediction quality and the end-to-end delay from sensing to actuation. We observe that (1) when latency is accounted for, the latency-optimal network configuration varies with scene context and compute availability; and (2) a single fixed-resolution model becomes suboptimal as conditions change. We present a multi-resolution, end-to-end deep neural network for the CARLA urban driving challenge using monocular camera input. Our approach employs a convolutional neural network (CNN) that supports multiple input resolutions through per-resolution batch normalization, enabling runtime selection of an ideal input scale under a latency budget, as well as resolution retargeting, which allows multi-resolution training without access to the original training dataset. We implement and evaluate our multi-resolution end-to-end CNN in CARLA to explore the latency-safety frontier. Results show consistent improvements in per-route safety metrics - lane invasions, red-light infractions, and collisions - relative to fixed-resolution baselines.
TinyLidarNet: 2D LiDAR-based End-to-End Deep Learning Model for F1TENTH Autonomous Racing
Oct 09, 2024



Prior research has demonstrated the effectiveness of end-to-end deep learning for robotic navigation, where the control signals are directly derived from raw sensory data. However, the majority of existing end-to-end navigation solutions are predominantly camera-based. In this paper, we introduce TinyLidarNet, a lightweight 2D LiDAR-based end-to-end deep learning model for autonomous racing. An F1TENTH vehicle using TinyLidarNet won 3rd place in the 12th F1TENTH Autonomous Grand Prix competition, demonstrating its competitive performance. We systematically analyze its performance on untrained tracks and computing requirements for real-time processing. We find that TinyLidarNet's 1D Convolutional Neural Network (CNN) based architecture significantly outperforms widely used Multi-Layer Perceptron (MLP) based architecture. In addition, we show that it can be processed in real-time on low-end micro-controller units (MCUs).
VALO: A Versatile Anytime Framework for LiDAR-based Object Detection Deep Neural Networks
Sep 17, 2024
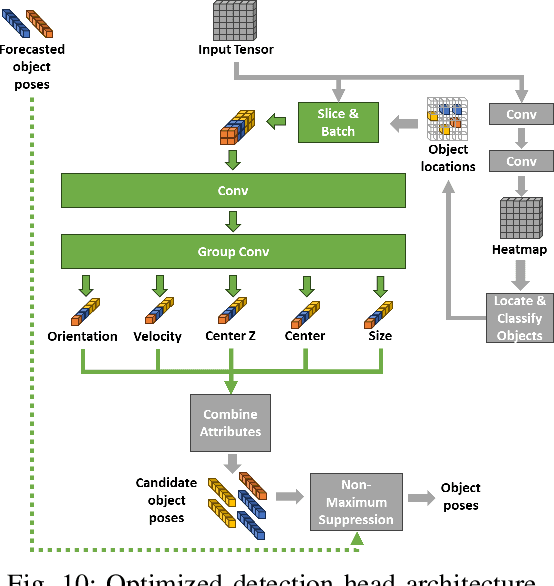
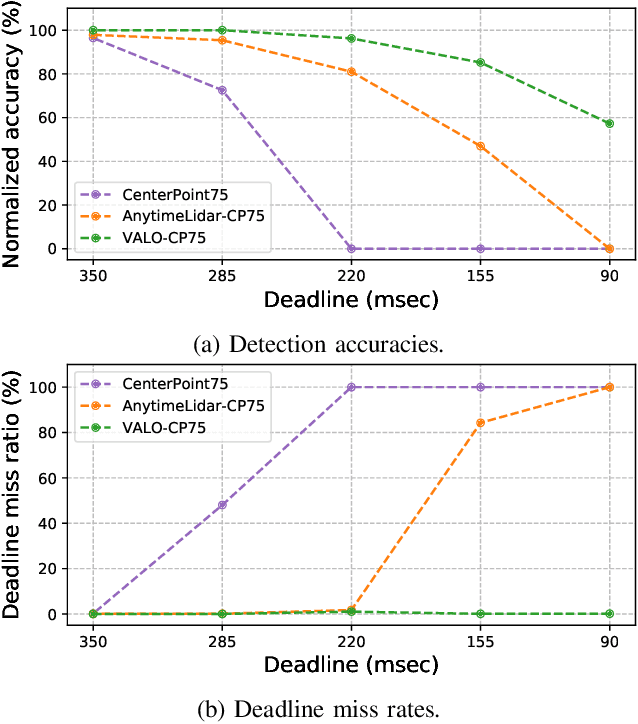
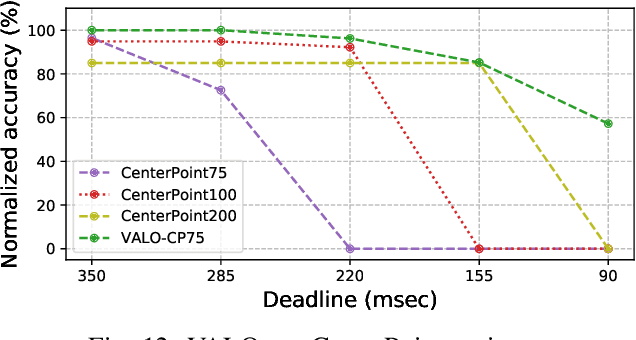
This work addresses the challenge of adapting dynamic deadline requirements for LiDAR object detection deep neural networks (DNNs). The computing latency of object detection is critically important to ensure safe and efficient navigation. However, state-of-the-art LiDAR object detection DNNs often exhibit significant latency, hindering their real-time performance on resource-constrained edge platforms. Therefore, a tradeoff between detection accuracy and latency should be dynamically managed at runtime to achieve optimum results. In this paper, we introduce VALO (Versatile Anytime algorithm for LiDAR Object detection), a novel data-centric approach that enables anytime computing of 3D LiDAR object detection DNNs. VALO employs a deadline-aware scheduler to selectively process input regions, making execution time and accuracy tradeoffs without architectural modifications. Additionally, it leverages efficient forecasting of past detection results to mitigate possible loss of accuracy due to partial processing of input. Finally, it utilizes a novel input reduction technique within its detection heads to significantly accelerate execution without sacrificing accuracy. We implement VALO on state-of-the-art 3D LiDAR object detection networks, namely CenterPoint and VoxelNext, and demonstrate its dynamic adaptability to a wide range of time constraints while achieving higher accuracy than the prior state-of-the-art. Code is available athttps://github.com/CSL-KU/VALO}{github.com/CSL-KU/VALO.
Anytime-Lidar: Deadline-aware 3D Object Detection
Aug 25, 2022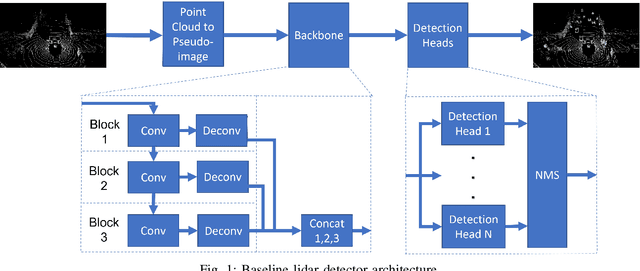
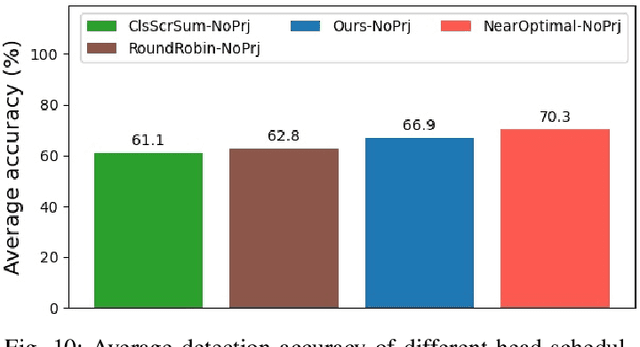
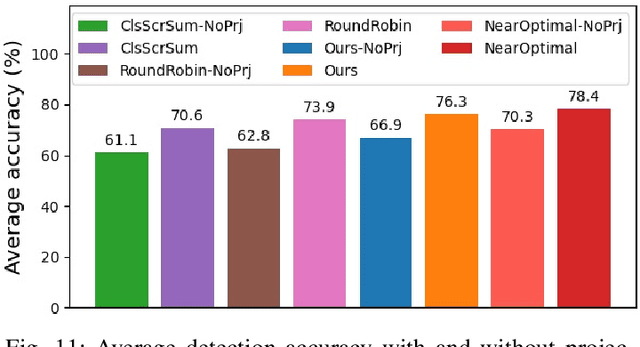
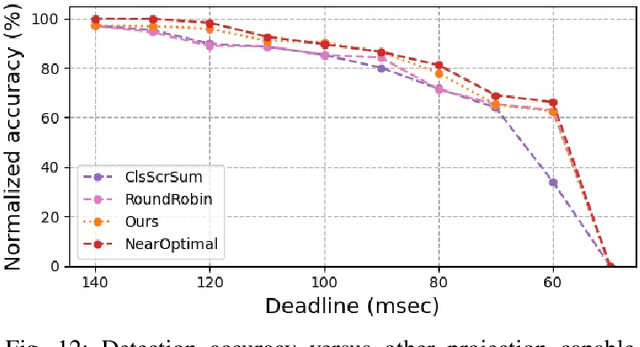
In this work, we present a novel scheduling framework enabling anytime perception for deep neural network (DNN) based 3D object detection pipelines. We focus on computationally expensive region proposal network (RPN) and per-category multi-head detector components, which are common in 3D object detection pipelines, and make them deadline-aware. We propose a scheduling algorithm, which intelligently selects the subset of the components to make effective time and accuracy trade-off on the fly. We minimize accuracy loss of skipping some of the neural network sub-components by projecting previously detected objects onto the current scene through estimations. We apply our approach to a state-of-art 3D object detection network, PointPillars, and evaluate its performance on Jetson Xavier AGX using nuScenes dataset. Compared to the baselines, our approach significantly improve the network's accuracy under various deadline constraints.
DeepPicarMicro: Applying TinyML to Autonomous Cyber Physical Systems
Aug 23, 2022

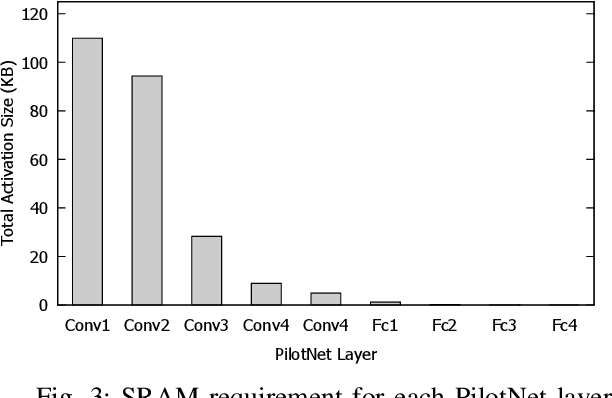
Running deep neural networks (DNNs) on tiny Micro-controller Units (MCUs) is challenging due to their limitations in computing, memory, and storage capacity. Fortunately, recent advances in both MCU hardware and machine learning software frameworks make it possible to run fairly complex neural networks on modern MCUs, resulting in a new field of study widely known as TinyML. However, there have been few studies to show the potential for TinyML applications in cyber physical systems (CPS). In this paper, we present DeepPicarMicro, a small self-driving RC car testbed, which runs a convolutional neural network (CNN) on a Raspberry Pi Pico MCU. We apply a state-of-the-art DNN optimization to successfully fit the well-known PilotNet CNN architecture, which was used to drive NVIDIA's real self-driving car, on the MCU. We apply a state-of-art network architecture search (NAS) approach to find further optimized networks that can effectively control the car in real-time in an end-to-end manner. From an extensive systematic experimental evaluation study, we observe an interesting relationship between the accuracy, latency, and control performance of a system. From this, we propose a joint optimization strategy that takes both accuracy and latency of a model in the network architecture search process for AI enabled CPS.
Integrating NVIDIA Deep Learning Accelerator (NVDLA) with RISC-V SoC on FireSim
Mar 05, 2019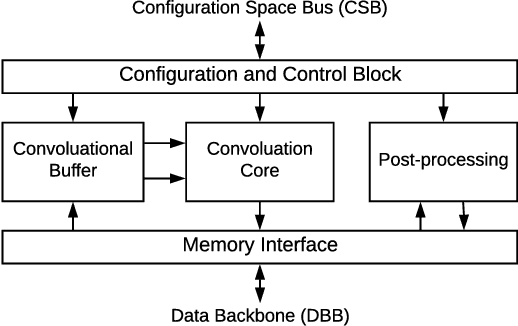

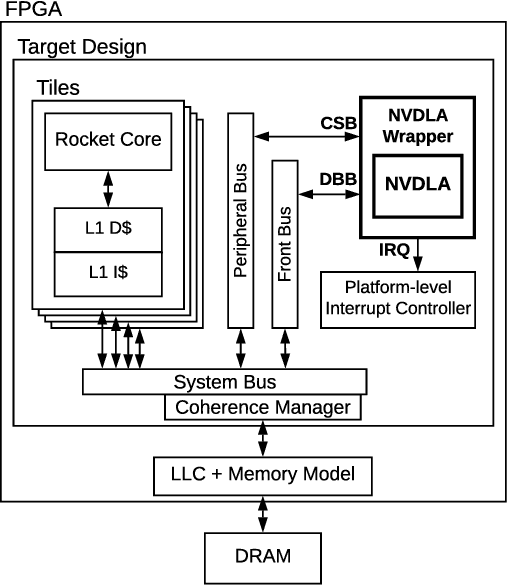
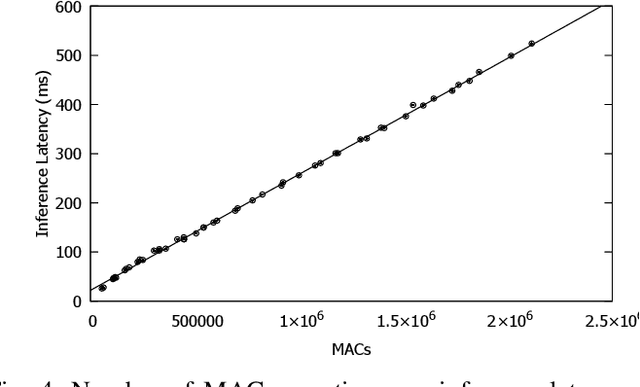
NVDLA is an open-source deep neural network (DNN) accelerator which has received a lot of attention by the community since its introduction by Nvidia. It is a full-featured hardware IP and can serve as a good reference for conducting research and development of SoCs with integrated accelerators. However, an expensive FPGA board is required to do experiments with this IP in a real SoC. Moreover, since NVDLA is clocked at a lower frequency on an FPGA, it would be hard to do accurate performance analysis with such a setup. To overcome these limitations, we integrate NVDLA into a real RISC-V SoC on the Amazon could FPGA using FireSim, a cycle-exact FPGA-accelerated simulator. We then evaluate the performance of NVDLA by running YOLOv3 object-detection algorithm. Our results show that NVDLA can sustain 7.5 fps when running YOLOv3. We further analyze the performance by showing that sharing the last-level cache with NVDLA can result in up to 1.56x speedup. We then identify that sharing the memory system with the accelerator can result in unpredictable execution time for the real-time tasks running on this platform. We believe this is an important issue that must be addressed in order for on-chip DNN accelerators to be incorporated in real-time embedded systems.
DeepPicar: A Low-cost Deep Neural Network-based Autonomous Car
Jul 30, 2018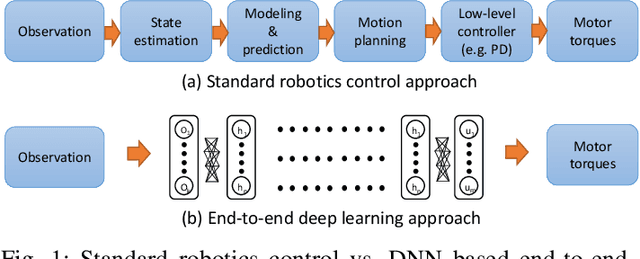
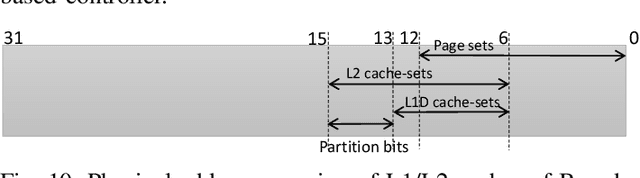
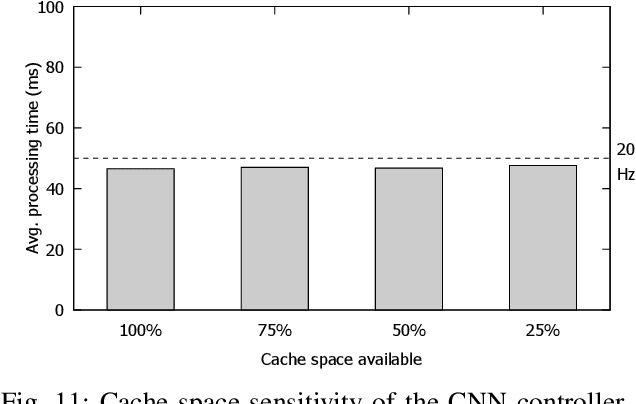
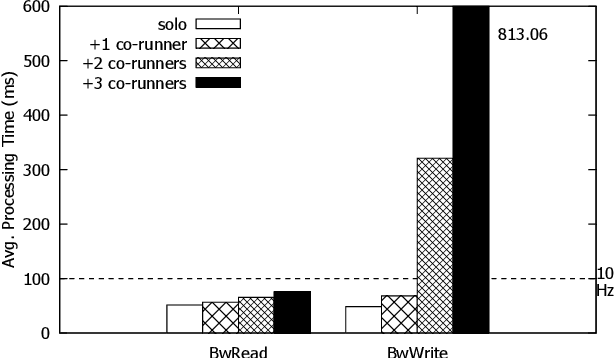
We present DeepPicar, a low-cost deep neural network based autonomous car platform. DeepPicar is a small scale replication of a real self-driving car called DAVE-2 by NVIDIA. DAVE-2 uses a deep convolutional neural network (CNN), which takes images from a front-facing camera as input and produces car steering angles as output. DeepPicar uses the same network architecture---9 layers, 27 million connections and 250K parameters---and can drive itself in real-time using a web camera and a Raspberry Pi 3 quad-core platform. Using DeepPicar, we analyze the Pi 3's computing capabilities to support end-to-end deep learning based real-time control of autonomous vehicles. We also systematically compare other contemporary embedded computing platforms using the DeepPicar's CNN-based real-time control workload. We find that all tested platforms, including the Pi 3, are capable of supporting the CNN-based real-time control, from 20 Hz up to 100 Hz, depending on hardware platform. However, we find that shared resource contention remains an important issue that must be considered in applying CNN models on shared memory based embedded computing platforms; we observe up to 11.6X execution time increase in the CNN based control loop due to shared resource contention. To protect the CNN workload, we also evaluate state-of-the-art cache partitioning and memory bandwidth throttling techniques on the Pi 3. We find that cache partitioning is ineffective, while memory bandwidth throttling is an effective solution.