 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating NVIDIA Deep Learning Accelerator (NVDLA) with RISC-V SoC on FireSim
Mar 05, 2019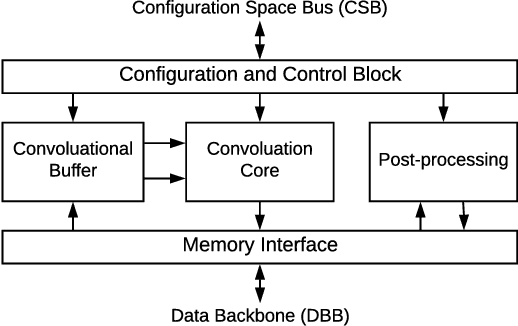

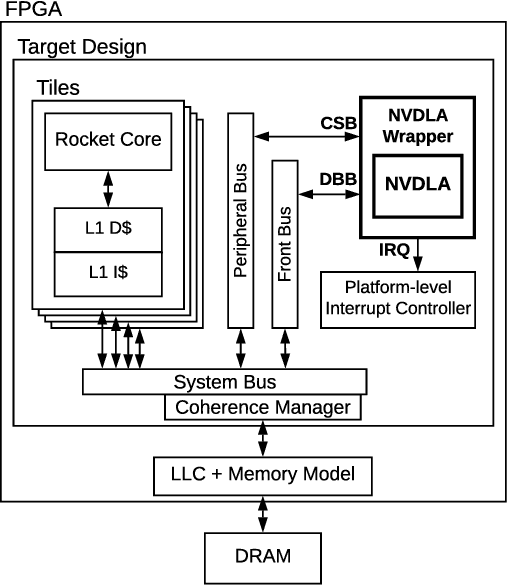
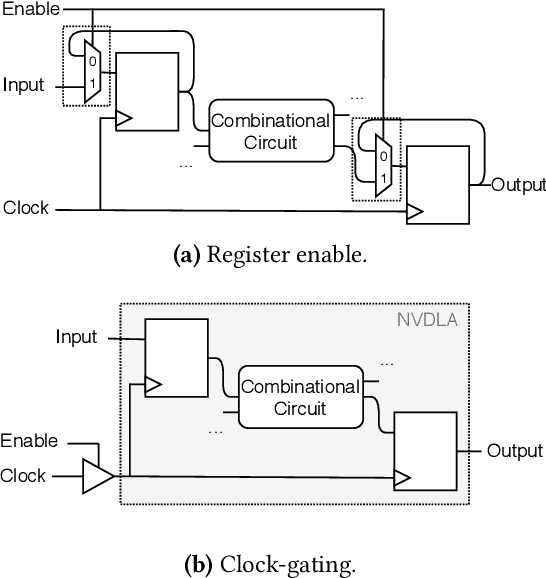
NVDLA is an open-source deep neural network (DNN) accelerator which has received a lot of attention by the community since its introduction by Nvidia. It is a full-featured hardware IP and can serve as a good reference for conducting research and development of SoCs with integrated accelerators. However, an expensive FPGA board is required to do experiments with this IP in a real SoC. Moreover, since NVDLA is clocked at a lower frequency on an FPGA, it would be hard to do accurate performance analysis with such a setup. To overcome these limitations, we integrate NVDLA into a real RISC-V SoC on the Amazon could FPGA using FireSim, a cycle-exact FPGA-accelerated simulator. We then evaluate the performance of NVDLA by running YOLOv3 object-detection algorithm. Our results show that NVDLA can sustain 7.5 fps when running YOLOv3. We further analyze the performance by showing that sharing the last-level cache with NVDLA can result in up to 1.56x speedup. We then identify that sharing the memory system with the accelerator can result in unpredictable execution time for the real-time tasks running on this platform. We believe this is an important issue that must be addressed in order for on-chip DNN accelerators to be incorporated in real-time embedded systems.