 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Diffusion-Flow models for generating 3D cosmic density fields: applications to f(R) cosmologies
Feb 24, 2025Next-generation galaxy surveys promise unprecedented precision in testing gravity at cosmological scales. However, realising this potential requires accurately modelling the non-linear cosmic web. We address this challenge by exploring conditional generative modelling to create 3D dark matter density fields via score-based (diffusion) and flow-based methods. Our results demonstrate the power of diffusion models to accurately reproduce the matter power spectra and bispectra, even for unseen configurations. They also offer a significant speed-up with slightly reduced accuracy, when flow-based reconstructing the probability distribution function, but they struggle with higher-order statistics. To improve conditional generation, we introduce a novel multi-output model to develop feature representations of the cosmological parameters. Our findings offer a powerful tool for exploring deviations from standard gravity, combining high precision with reduced computational cost, thus paving the way for more comprehensive and efficient cosmological analyses
Enhancing Diagnostic in 3D COVID-19 Pneumonia CT-scans through Explainable Uncertainty Bayesian Quantification
Jan 18, 2025Accurately classifying COVID-19 pneumonia in 3D CT scans remains a significant challenge in the field of medical image analysis. Although deterministic neural networks have shown promising results in this area, they provide only point estimates outputs yielding poor diagnostic in clinical decision-making. In this paper, we explore the use of Bayesian neural networks for classifying COVID-19 pneumonia in 3D CT scans providing uncertainties in their predictions. We compare deterministic networks and their Bayesian counterpart, enhancing the decision-making accuracy under uncertainty information. Remarkably, our findings reveal that lightweight architectures achieve the highest accuracy of 96\% after developing extensive hyperparameter tuning. Furthermore, the Bayesian counterpart of these architectures via Multiplied Normalizing Flow technique kept a similar performance along with calibrated uncertainty estimates. Finally, we have developed a 3D-visualization approach to explain the neural network outcomes based on SHAP values. We conclude that explainability along with uncertainty quantification will offer better clinical decisions in medical image analysis, contributing to ongoing efforts for improving the diagnosis and treatment of COVID-19 pneumonia.
Deep Bayesian segmentation for colon polyps: Well-calibrated predictions in medical imaging
Jul 23, 2024Colorectal polyps are generally benign alterations that, if not identified promptly and managed successfully, can progress to cancer and cause affectations on the colon mucosa, known as adenocarcinoma. Today advances in Deep Learning have demonstrated the ability to achieve significant performance in image classification and detection in medical diagnosis applications. Nevertheless, these models are prone to overfitting, and making decisions based only on point estimations may provide incorrect predictions. Thus, to obtain a more informed decision, we must consider point estimations along with their reliable uncertainty quantification. In this paper, we built different Bayesian neural network approaches based on the flexibility of posterior distribution to develop semantic segmentation of colorectal polyp images. We found that these models not only provide state-of-the-art performance on the segmentation of this medical dataset but also, yield accurate uncertainty estimates. We applied multiplicative normalized flows(MNF) and reparameterization trick on the UNET, FPN, and LINKNET architectures tested with multiple backbones in deterministic and Bayesian versions. We report that the FPN + EfficientnetB7 architecture with MNF is the most promising option given its IOU of 0.94 and Expected Calibration Error (ECE) of 0.004, combined with its superiority in identifying difficult-to-detect colorectal polyps, which is effective in clinical areas where early detection prevents the development of colon cancer.
Constraining cosmological parameters from N-body simulations with Bayesian Neural Networks
Dec 22, 2021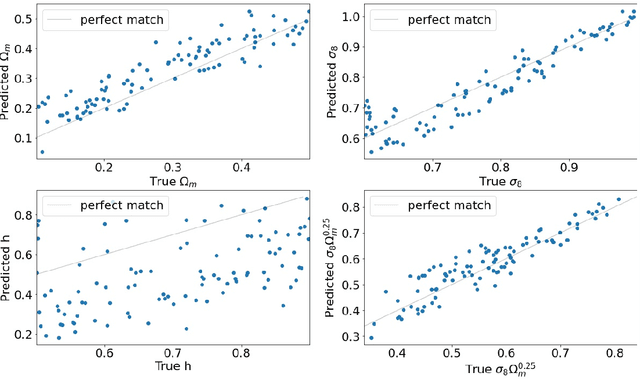
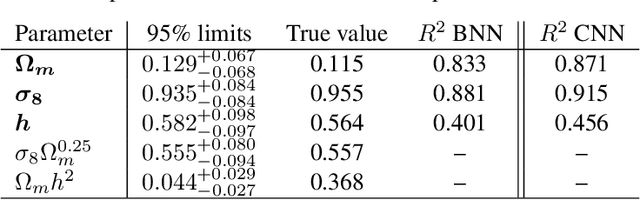
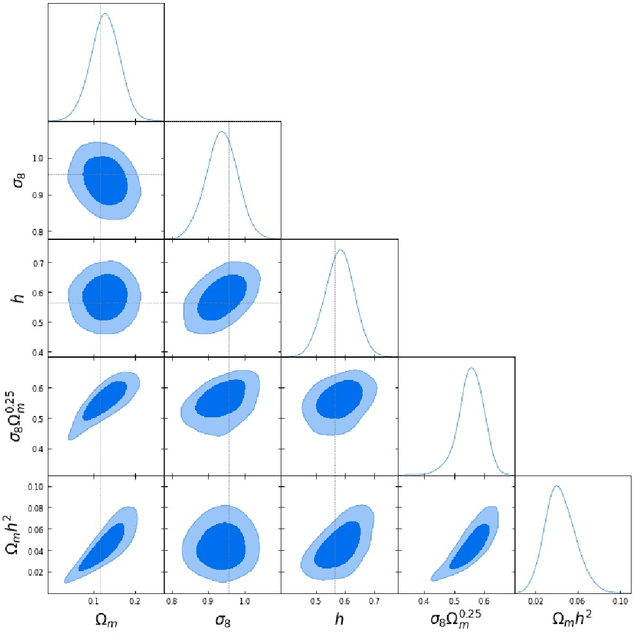
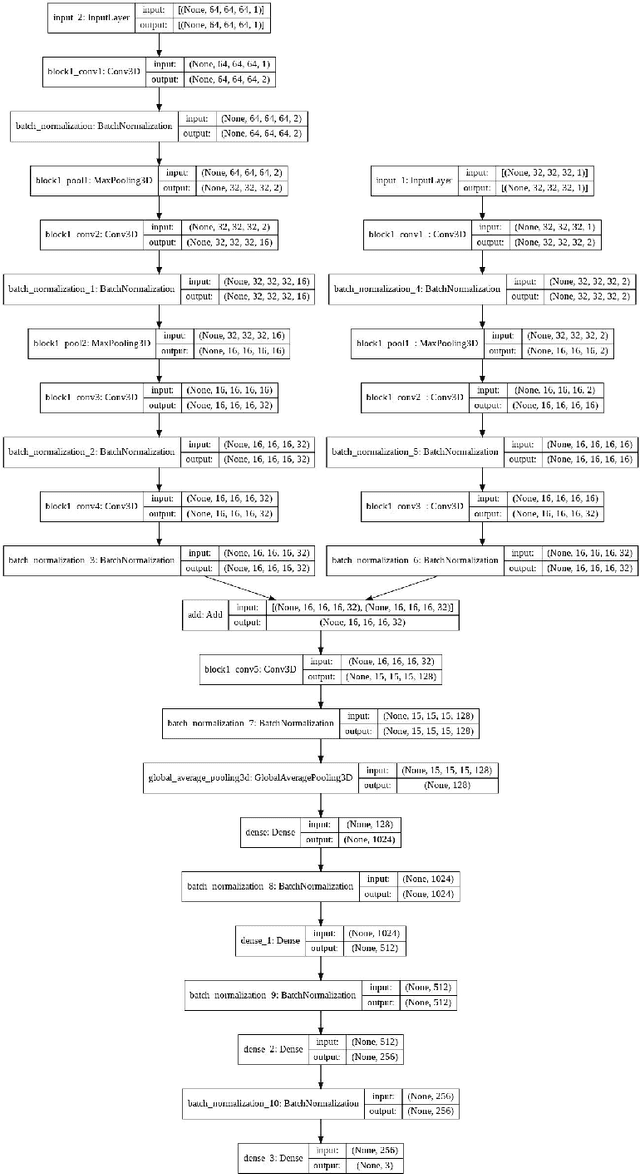
In this paper, we use The Quijote simulations in order to extract the cosmological parameters through Bayesian Neural Networks. This kind of model has a remarkable ability to estimate the associated uncertainty, which is one of the ultimate goals in the precision cosmology era. We demonstrate the advantages of BNNs for extracting more complex output distributions and non-Gaussianities information from the simulations.
Accelerating MCMC algorithms through Bayesian Deep Networks
Nov 29, 2020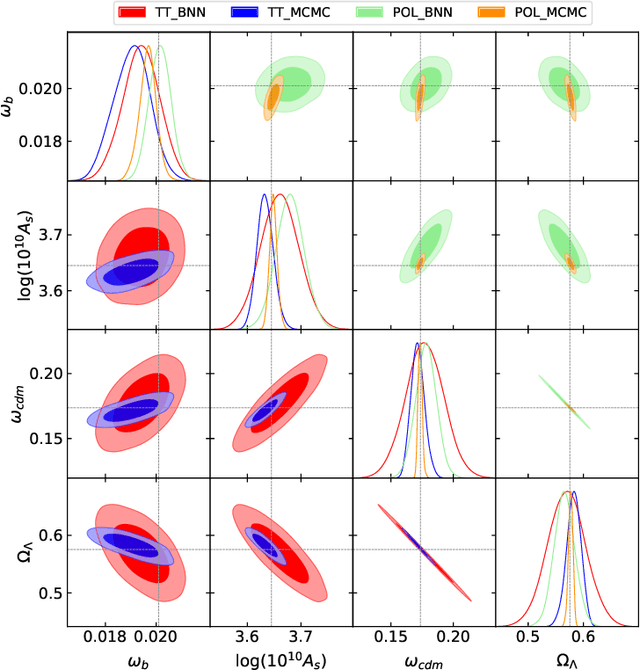
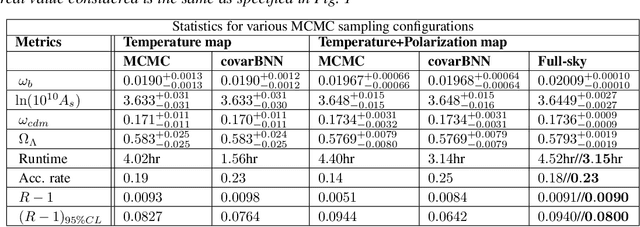
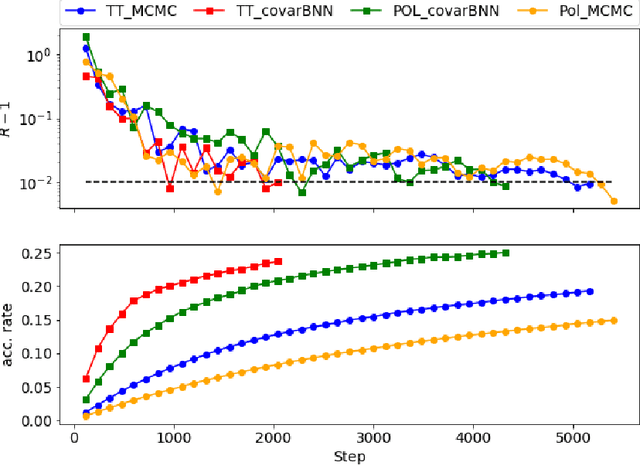
Markov Chain Monte Carlo (MCMC) algorithms are commonly used for their versatility in sampling from complicated probability distributions. However, as the dimension of the distribution gets larger, the computational costs for a satisfactory exploration of the sampling space become challenging. Adaptive MCMC methods employing a choice of proposal distribution can address this issue speeding up the convergence. In this paper we show an alternative way of performing adaptive MCMC, by using the outcome of Bayesian Neural Networks as the initial proposal for the Markov Chain. This combined approach increases the acceptance rate in the Metropolis-Hasting algorithm and accelerate the convergence of the MCMC while reaching the same final accuracy. Finally, we demonstrate the main advantages of this approach by constraining the cosmological parameters directly from Cosmic Microwave Background maps.
Reliable Uncertainties for Bayesian Neural Networks using Alpha-divergences
Aug 15, 2020Bayesian Neural Networks (BNNs) often result uncalibrated after training, usually tending towards overconfidence. Devising effective calibration methods with low impact in terms of computational complexity is thus of central interest. In this paper we present calibration methods for BNNs based on the alpha divergences from Information Geometry. We compare the use of alpha divergence in training and in calibration, and we show how the use in calibration provides better calibrated uncertainty estimates for specific choices of alpha and is more efficient especially for complex network architectures. We empirically demonstrate the advantages of alpha calibration in regression problems involving parameter estimation and inferred correlations between output uncertainties.
Parameters Estimation for the Cosmic Microwave Background with Bayesian Neural Networks
Dec 23, 2019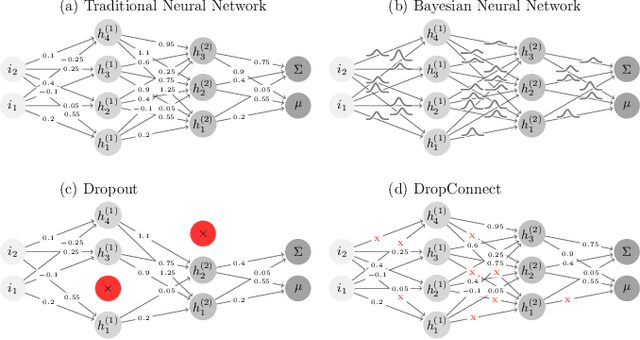
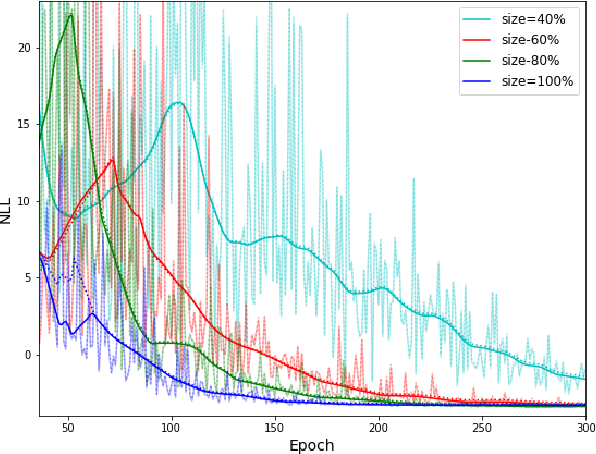
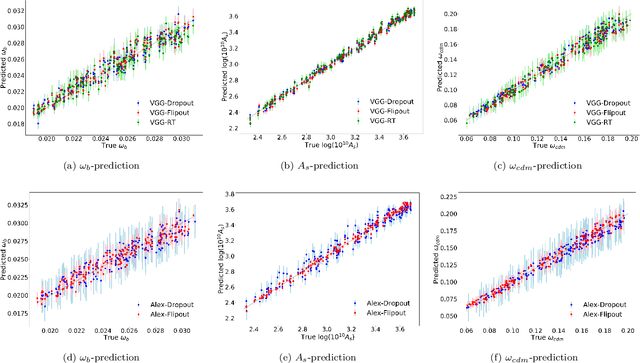
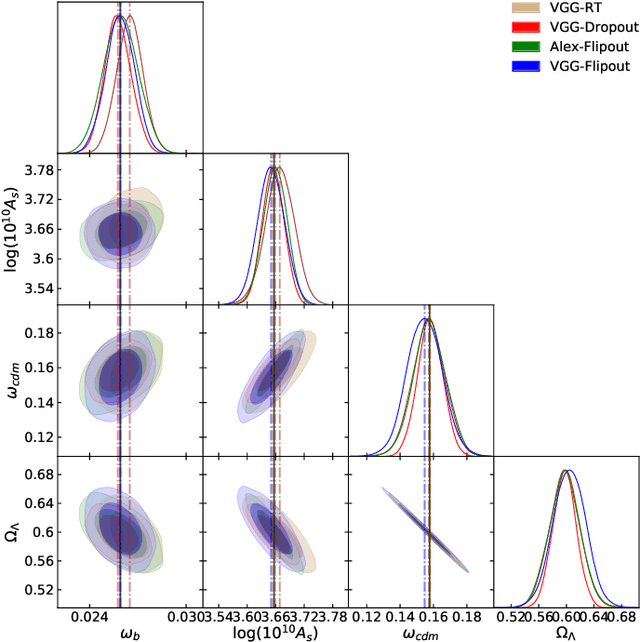
In this paper, we present the first study that compares different models of Bayesian Neural Networks (BNNs) to predict the posterior distribution of the cosmological parameters directly from the Cosmic Microwave Background temperature and polarization maps. We focus our analysis on four different methods to sample the weights of the network during training: Dropout, DropConnect, Reparameterization Trick (RT), and Flipout. We find out that Flipout outperforms all other methods regardless of the architecture used, and provides tighter constraints for the cosmological parameters. Additionally, we describe existing strategies for calibrating the networks and propose new ones. We show how tuning the regularization parameter for the scale of the approximate posterior on the weights in Flipout and RT we can produce unbiased and reliable uncertainty estimates, i.e., the regularizer acts as a hyper parameter analogous to the dropout rate in Dropout. The best performances are nevertheless achieved with a more convenient method, in which the network parameters are let free during training to achieve the best uncalibrated performances, and then the confidence intervals are calibrated in a subsequent phase. Furthermore, we claim that the correct calibration of these networks does not change the behavior for the aleatoric and epistemic uncertainties provided for BNNs when the size of the training dataset changes. The results reported in the paper can be extended to other cosmological datasets in order to capture features that can be extracted directly from the raw data, such as non-Gaussianity or foreground emissions.