 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Analysis of Minimax Excess Risk
Feb 15, 2022Two main concepts studied in machine learning theory are generalization gap (difference between train and test error) and excess risk (difference between test error and the minimum possible error). While information-theoretic tools have been used extensively to study the generalization gap of learning algorithms, the information-theoretic nature of excess risk has not yet been fully investigated. In this paper, some steps are taken toward this goal. We consider the frequentist problem of minimax excess risk as a zero-sum game between algorithm designer and the world. Then, we argue that it is desirable to modify this game in a way that the order of play can be swapped. We prove that, under some regularity conditions, if the world and designer can play randomly the duality gap is zero and the order of play can be changed. In this case, a Bayesian problem surfaces in the dual representation. This makes it possible to utilize recent information-theoretic results on minimum excess risk in Bayesian learning to provide bounds on the minimax excess risk. We demonstrate the applicability of the results by providing information theoretic insight on two important classes of problems: classification when the hypothesis space has finite VC-dimension, and regularized least squares.
Rate-Distortion Analysis of Minimum Excess Risk in Bayesian Learning
May 10, 2021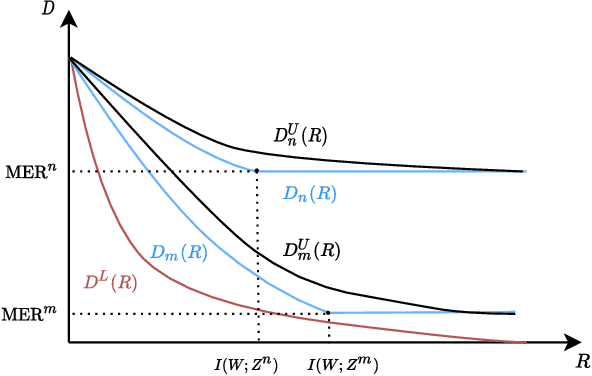

Minimum Excess Risk (MER) in Bayesian learning is defined as the difference between the minimum expected loss achievable when learning from data and the minimum expected loss that could be achieved if the underlying parameter $W$ was observed. In this paper, we build upon and extend the recent results of (Xu & Raginsky, 2020) to analyze the MER in Bayesian learning and derive information-theoretic bounds on it. We formulate the problem as a (constrained) rate-distortion optimization and show how the solution can be bounded above and below by two other rate-distortion functions that are easier to study. The lower bound represents the minimum possible excess risk achievable by \emph{any} process using $R$ bits of information from the parameter $W$. For the upper bound, the optimization is further constrained to use $R$ bits from the training set, a setting which relates MER to information-theoretic bounds on the generalization gap in frequentist learning. We derive information-theoretic bounds on the difference between these upper and lower bounds and show that they can provide order-wise tight rates for MER. This analysis gives more insight into the information-theoretic nature of Bayesian learning as well as providing novel bounds.
Do Compressed Representations Generalize Better?
Sep 20, 2019
One of the most studied problems in machine learning is finding reasonable constraints that guarantee the generalization of a learning algorithm. These constraints are usually expressed as some simplicity assumptions on the target. For instance, in the Vapnik-Chervonenkis (VC) theory the space of possible hypotheses is considered to have a limited VC dimension. In this paper, the constraint on the entropy $H(X)$ of the input variable $X$ is studied as a simplicity assumption. It is proven that the sample complexity to achieve an $\epsilon$-$\delta$ Probably Approximately Correct (PAC) hypothesis is bounded by $\frac{2^{ \left.2H(X)\middle/\epsilon\right.}+\log{\frac{1}{\delta}}}{\epsilon^2}$ which is sharp up to the $\frac{1}{\epsilon^2}$ factor. Morever, it is shown that if a feature learning process is employed to learn the compressed representation from the dataset, this bound no longer exists. These findings have important implications on the Information Bottleneck (IB) theory which had been utilized to explain the generalization power of Deep Neural Networks (DNNs), but its applicability for this purpose is currently under debate by researchers. In particular, this is a rigorous proof for the previous heuristic that compressed representations are expnentially easier to be learned. However, our analysis pinpoints two factors preventing the IB, in its current form, to be applicable in studying neural networks. Firstly, the exponential dependence of sample complexity on $\frac{1}{\epsilon}$, which can lead to a dramatic effect on the bounds in practical applications when $\epsilon$ is small. Secondly, our analysis reveals that arguments based on input compression are inherently insufficient to explain generalization of methods like DNNs in which the features are also learned using available data.
Information Bottleneck and its Applications in Deep Learning
Apr 07, 2019
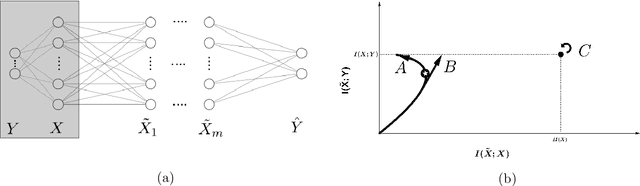

Information Theory (IT) has been used in Machine Learning (ML) from early days of this field. In the last decade, advances in Deep Neural Networks (DNNs) have led to surprising improvements in many applications of ML. The result has been a paradigm shift in the community toward revisiting previous ideas and applications in this new framework. Ideas from IT are no exception. One of the ideas which is being revisited by many researchers in this new era, is Information Bottleneck (IB); a formulation of information extraction based on IT. The IB is promising in both analyzing and improving DNNs. The goal of this survey is to review the IB concept and demonstrate its applications in deep learning. The information theoretic nature of IB, makes it also a good candidate in showing the more general concept of how IT can be used in ML. Two important concepts are highlighted in this narrative on the subject, i) the concise and universal view that IT provides on seemingly unrelated methods of ML, demonstrated by explaining how IB relates to minimal sufficient statistics, stochastic gradient descent, and variational auto-encoders, and ii) the common technical mistakes and problems caused by applying ideas from IT, which is discussed by a careful study of some recent methods suffering from them.