 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Distortion Analysis of Minimum Excess Risk in Bayesian Learning
Paper and Code
May 10, 2021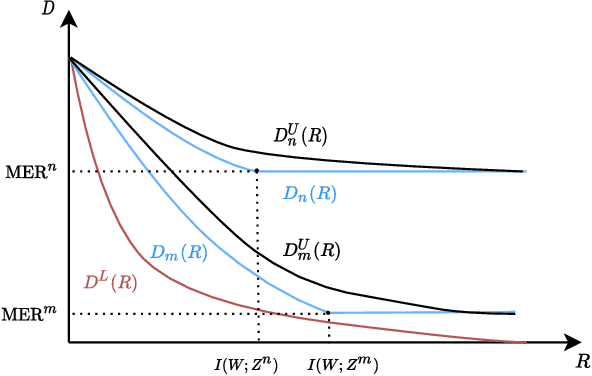

Minimum Excess Risk (MER) in Bayesian learning is defined as the difference between the minimum expected loss achievable when learning from data and the minimum expected loss that could be achieved if the underlying parameter $W$ was observed. In this paper, we build upon and extend the recent results of (Xu & Raginsky, 2020) to analyze the MER in Bayesian learning and derive information-theoretic bounds on it. We formulate the problem as a (constrained) rate-distortion optimization and show how the solution can be bounded above and below by two other rate-distortion functions that are easier to study. The lower bound represents the minimum possible excess risk achievable by \emph{any} process using $R$ bits of information from the parameter $W$. For the upper bound, the optimization is further constrained to use $R$ bits from the training set, a setting which relates MER to information-theoretic bounds on the generalization gap in frequentist learning. We derive information-theoretic bounds on the difference between these upper and lower bounds and show that they can provide order-wise tight rates for MER. This analysis gives more insight into the information-theoretic nature of Bayesian learning as well as providing novel bounds.