 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Frame Interpolation with Flow Transformer
Jul 30, 2023



Video frame interpolation has been actively studied with the development of convolutional neural networks. However, due to the intrinsic limitations of kernel weight sharing in convolution, the interpolated frame generated by it may lose details. In contrast, the attention mechanism in Transformer can better distinguish the contribution of each pixel, and it can also capture long-range pixel dependencies, which provides great potential for video interpolation. Nevertheless, the original Transformer is commonly used for 2D images; how to develop a Transformer-based framework with consideration of temporal self-attention for video frame interpolation remains an open issue. In this paper, we propose Video Frame Interpolation Flow Transformer to incorporate motion dynamics from optical flows into the self-attention mechanism. Specifically, we design a Flow Transformer Block that calculates the temporal self-attention in a matched local area with the guidance of flow, making our framework suitable for interpolating frames with large motion while maintaining reasonably low complexity. In addition, we construct a multi-scale architecture to account for multi-scale motion, further improving the overall performance. Extensive experiments on three benchmarks demonstrate that the proposed method can generate interpolated frames with better visual quality than state-of-the-art methods.
IncepFormer: Efficient Inception Transformer with Pyramid Pooling for Semantic Segmentation
Dec 06, 2022Semantic segmentation usually benefits from global contexts, fine localisation information, multi-scale features, etc. To advance Transformer-based segmenters with these aspects, we present a simple yet powerful semantic segmentation architecture, termed as IncepFormer. IncepFormer has two critical contributions as following. First, it introduces a novel pyramid structured Transformer encoder which harvests global context and fine localisation features simultaneously. These features are concatenated and fed into a convolution layer for final per-pixel prediction. Second, IncepFormer integrates an Inception-like architecture with depth-wise convolutions, and a light-weight feed-forward module in each self-attention layer, efficiently obtaining rich local multi-scale object features. Extensive experiments on five benchmarks show that our IncepFormer is superior to state-of-the-art methods in both accuracy and speed, e.g., 1) our IncepFormer-S achieves 47.7% mIoU on ADE20K which outperforms the existing best method by 1% while only costs half parameters and fewer FLOPs. 2) Our IncepFormer-B finally achieves 82.0% mIoU on Cityscapes dataset with 39.6M parameters. Code is available:github.com/shendu0321/IncepFormer.
Video Frame Interpolation Based on Deformable Kernel Region
Apr 25, 2022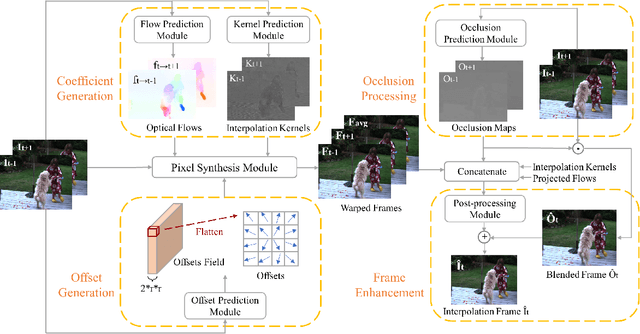
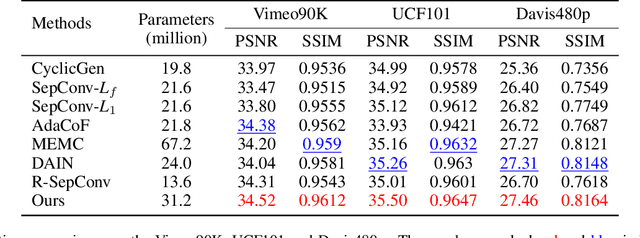


Video frame interpolation task has recently become more and more prevalent in the computer vision field. At present, a number of researches based on deep learning have achieved great success. Most of them are either based on optical flow information, or interpolation kernel, or a combination of these two methods. However, these methods have ignored that there are grid restrictions on the position of kernel region during synthesizing each target pixel. These limitations result in that they cannot well adapt to the irregularity of object shape and uncertainty of motion, which may lead to irrelevant reference pixels used for interpolation. In order to solve this problem, we revisit the deformable convolution for video interpolation, which can break the fixed grid restrictions on the kernel region, making the distribution of reference points more suitable for the shape of the object, and thus warp a more accurate interpolation frame. Experiments are conducted on four datasets to demonstrate the superior performance of the proposed model in comparison to the state-of-the-art alternatives.
Dilated convolutional neural network-based deep reference picture generation for video compression
Feb 11, 2022
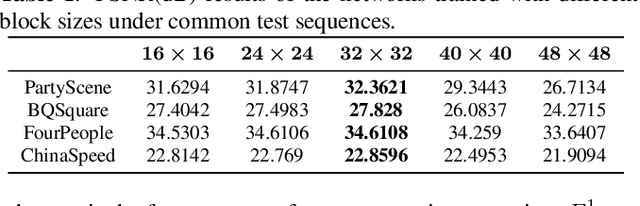
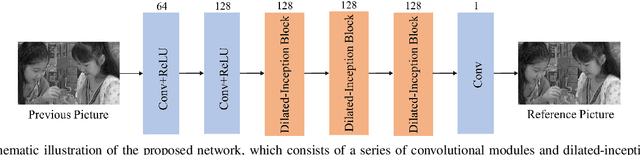
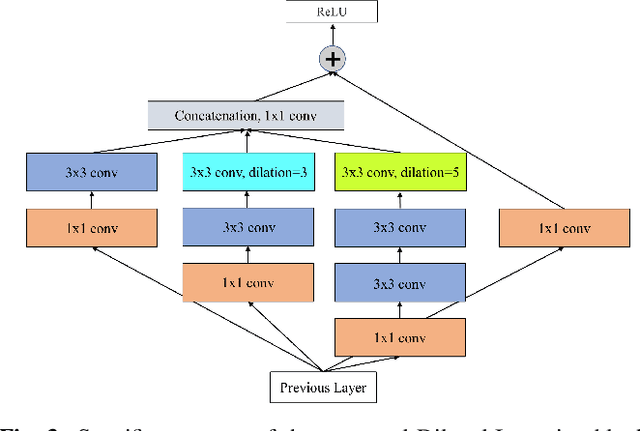
Motion estimation and motion compensation are indispensable parts of inter prediction in video coding. Since the motion vector of objects is mostly in fractional pixel units, original reference pictures may not accurately provide a suitable reference for motion compensation. In this paper, we propose a deep reference picture generator which can create a picture that is more relevant to the current encoding frame, thereby further reducing temporal redundancy and improving video compression efficiency. Inspired by the recent progress of Convolutional Neural Network(CNN), this paper proposes to use a dilated CNN to build the generator. Moreover, we insert the generated deep picture into Versatile Video Coding(VVC) as a reference picture and perform a comprehensive set of experiments to evaluate the effectiveness of our network on the latest VVC Test Model VTM. The experimental results demonstrate that our proposed method achieves on average 9.7% bit saving compared with VVC under low-delay P configuration.