 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams
Sep 28, 2020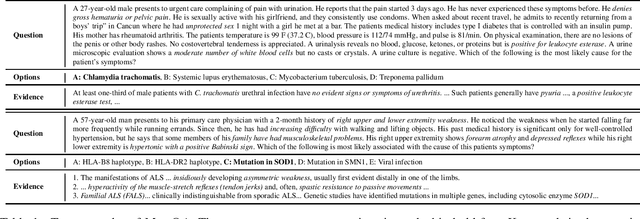
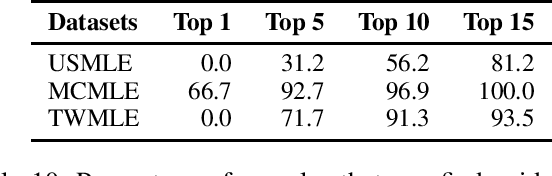

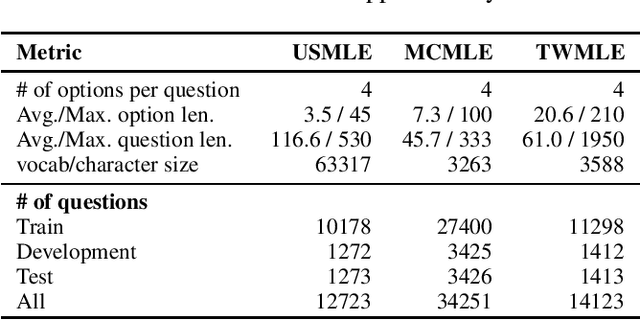
Open domain question answering (OpenQA) tasks have been recently attracting more and more attention from the natural language processing (NLP) community. In this work, we present the first free-form multiple-choice OpenQA dataset for solving medical problems, MedQA, collected from the professional medical board exams. It covers three languages: English, simplified Chinese, and traditional Chinese, and contains 12,723, 34,251, and 14,123 questions for the three languages, respectively. We implement both rule-based and popular neural methods by sequentially combining a document retriever and a machine comprehension model. Through experiments, we find that even the current best method can only achieve 36.7\%, 42.0\%, and 70.1\% of test accuracy on the English, traditional Chinese, and simplified Chinese questions, respectively. We expect MedQA to present great challenges to existing OpenQA systems and hope that it can serve as a platform to promote much stronger OpenQA models from the NLP community in the future.