 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMouseSIS: A Frames-and-Events Dataset for Space-Time Instance Segmentation of Mice
Sep 05, 2024



Enabled by large annotated datasets, tracking and segmentation of objects in videos has made remarkable progress in recent years. Despite these advancements, algorithms still struggle under degraded conditions and during fast movements. Event cameras are novel sensors with high temporal resolution and high dynamic range that offer promising advantages to address these challenges. However, annotated data for developing learning-based mask-level tracking algorithms with events is not available. To this end, we introduce: ($i$) a new task termed \emph{space-time instance segmentation}, similar to video instance segmentation, whose goal is to segment instances throughout the entire duration of the sensor input (here, the input are quasi-continuous events and optionally aligned frames); and ($ii$) \emph{\dname}, a dataset for the new task, containing aligned grayscale frames and events. It includes annotated ground-truth labels (pixel-level instance segmentation masks) of a group of up to seven freely moving and interacting mice. We also provide two reference methods, which show that leveraging event data can consistently improve tracking performance, especially when used in combination with conventional cameras. The results highlight the potential of event-aided tracking in difficult scenarios. We hope our dataset opens the field of event-based video instance segmentation and enables the development of robust tracking algorithms for challenging conditions.\url{https://github.com/tub-rip/MouseSIS}
Quantum reinforcement learning
Oct 21, 2008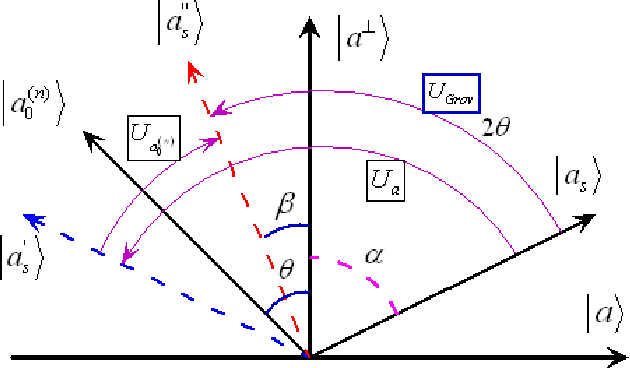
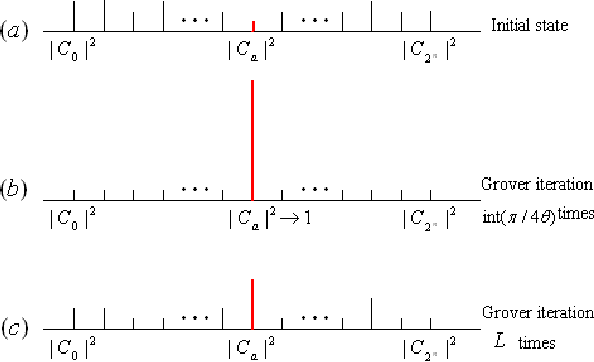

The key approaches for machine learning, especially learning in unknown probabilistic environments are new representations and computation mechanisms. In this paper, a novel quantum reinforcement learning (QRL) method is proposed by combining quantum theory and reinforcement learning (RL). Inspired by the state superposition principle and quantum parallelism, a framework of value updating algorithm is introduced. The state (action) in traditional RL is identified as the eigen state (eigen action) in QRL. The state (action) set can be represented with a quantum superposition state and the eigen state (eigen action) can be obtained by randomly observing the simulated quantum state according to the collapse postulate of quantum measurement. The probability of the eigen action is determined by the probability amplitude, which is parallelly updated according to rewards. Some related characteristics of QRL such as convergence, optimality and balancing between exploration and exploitation are also analyzed, which shows that this approach makes a good tradeoff between exploration and exploitation using the probability amplitude and can speed up learning through the quantum parallelism. To evaluate the performance and practicability of QRL, several simulated experiments are given and the results demonstrate the effectiveness and superiority of QRL algorithm for some complex problems. The present work is also an effective exploration on the application of quantum computation to artificial intelligence.
* 13 pages, 7 figures, Latex