 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEALion: a Framework for Neural Network Inference on Encrypted Data
Apr 29, 2019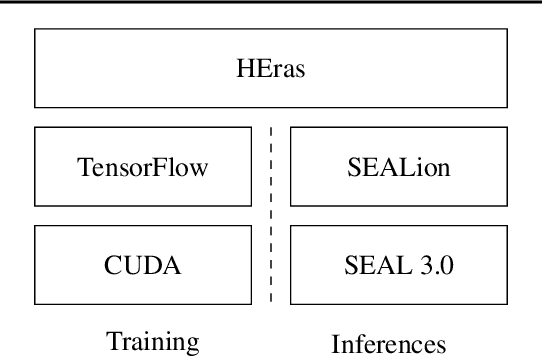
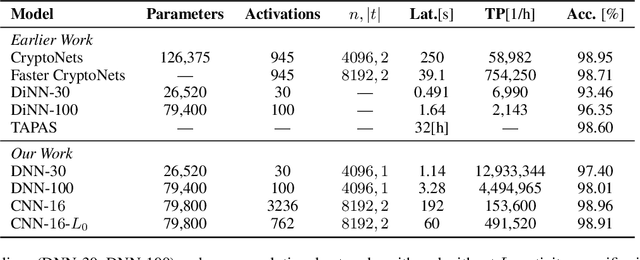
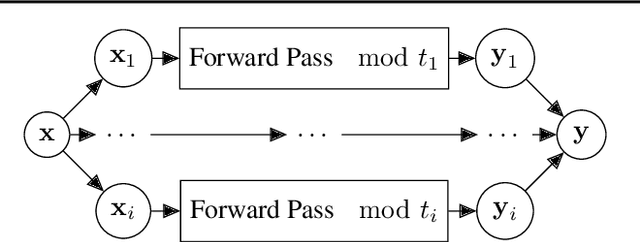

We present SEALion: an extensible framework for privacy-preserving machine learning with homomorphic encryption. It allows one to learn deep neural networks that can be seamlessly utilized for prediction on encrypted data. The framework consists of two layers: the first is built upon TensorFlow and SEAL and exposes standard algebra and deep learning primitives; the second implements a Keras-like syntax for training and inference with neural networks. Given a required level of security, a user is abstracted from the details of the encoding and the encryption scheme, allowing quick prototyping. We present two applications that exemplifying the extensibility of our proposal, which are also of independent interest: i) improving efficiency of neural network inference by an activity sparsifier and ii) transfer learning by querying a server-side Variational AutoEncoder that can handle encrypted data.
Entity Resolution and Federated Learning get a Federated Resolution
Mar 20, 2018


Consider two data providers, each maintaining records of different feature sets about common entities. They aim to learn a linear model over the whole set of features. This problem of federated learning over vertically partitioned data includes a crucial upstream issue: entity resolution, i.e. finding the correspondence between the rows of the datasets. It is well known that entity resolution, just like learning, is mistake-prone in the real world. Despite the importance of the problem, there has been no formal assessment of how errors in entity resolution impact learning. In this paper, we provide a thorough answer to this question, answering how optimal classifiers, empirical losses, margins and generalisation abilities are affected. While our answer spans a wide set of losses --- going beyond proper, convex, or classification calibrated ---, it brings simple practical arguments to upgrade entity resolution as a preprocessing step to learning. One of these suggests that entity resolution should be aimed at controlling or minimizing the number of matching errors between examples of distinct classes. In our experiments, we modify a simple token-based entity resolution algorithm so that it indeed aims at avoiding matching rows belonging to different classes, and perform experiments in the setting where entity resolution relies on noisy data, which is very relevant to real world domains. Notably, our approach covers the case where one peer \textit{does not} have classes, or a noisy record of classes. Experiments display that using the class information during entity resolution can buy significant uplift for learning at little expense from the complexity standpoint.
Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption
Nov 29, 2017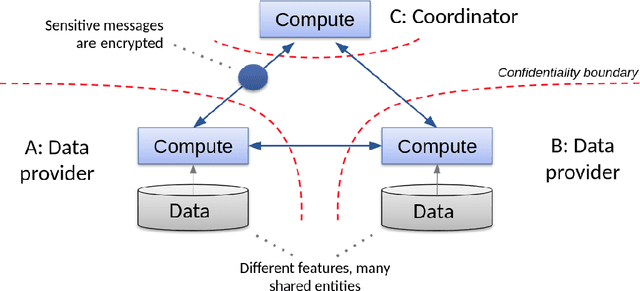



Consider two data providers, each maintaining private records of different feature sets about common entities. They aim to learn a linear model jointly in a federated setting, namely, data is local and a shared model is trained from locally computed updates. In contrast with most work on distributed learning, in this scenario (i) data is split vertically, i.e. by features, (ii) only one data provider knows the target variable and (iii) entities are not linked across the data providers. Hence, to the challenge of private learning, we add the potentially negative consequences of mistakes in entity resolution. Our contribution is twofold. First, we describe a three-party end-to-end solution in two phases ---privacy-preserving entity resolution and federated logistic regression over messages encrypted with an additively homomorphic scheme---, secure against a honest-but-curious adversary. The system allows learning without either exposing data in the clear or sharing which entities the data providers have in common. Our implementation is as accurate as a naive non-private solution that brings all data in one place, and scales to problems with millions of entities with hundreds of features. Second, we provide what is to our knowledge the first formal analysis of the impact of entity resolution's mistakes on learning, with results on how optimal classifiers, empirical losses, margins and generalisation abilities are affected. Our results bring a clear and strong support for federated learning: under reasonable assumptions on the number and magnitude of entity resolution's mistakes, it can be extremely beneficial to carry out federated learning in the setting where each peer's data provides a significant uplift to the other.