 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption
Paper and Code
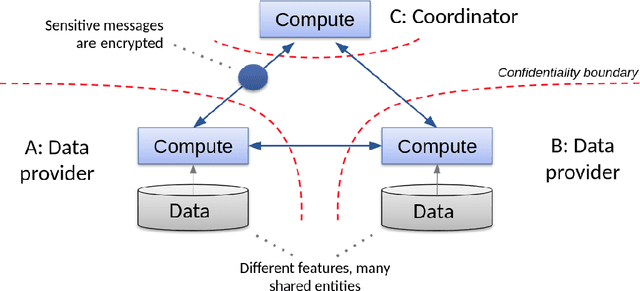



Consider two data providers, each maintaining private records of different feature sets about common entities. They aim to learn a linear model jointly in a federated setting, namely, data is local and a shared model is trained from locally computed updates. In contrast with most work on distributed learning, in this scenario (i) data is split vertically, i.e. by features, (ii) only one data provider knows the target variable and (iii) entities are not linked across the data providers. Hence, to the challenge of private learning, we add the potentially negative consequences of mistakes in entity resolution. Our contribution is twofold. First, we describe a three-party end-to-end solution in two phases ---privacy-preserving entity resolution and federated logistic regression over messages encrypted with an additively homomorphic scheme---, secure against a honest-but-curious adversary. The system allows learning without either exposing data in the clear or sharing which entities the data providers have in common. Our implementation is as accurate as a naive non-private solution that brings all data in one place, and scales to problems with millions of entities with hundreds of features. Second, we provide what is to our knowledge the first formal analysis of the impact of entity resolution's mistakes on learning, with results on how optimal classifiers, empirical losses, margins and generalisation abilities are affected. Our results bring a clear and strong support for federated learning: under reasonable assumptions on the number and magnitude of entity resolution's mistakes, it can be extremely beneficial to carry out federated learning in the setting where each peer's data provides a significant uplift to the other.