 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel and Limited Data Voice Conversion Using Stochastic Variational Deep Kernel Learning
Sep 08, 2023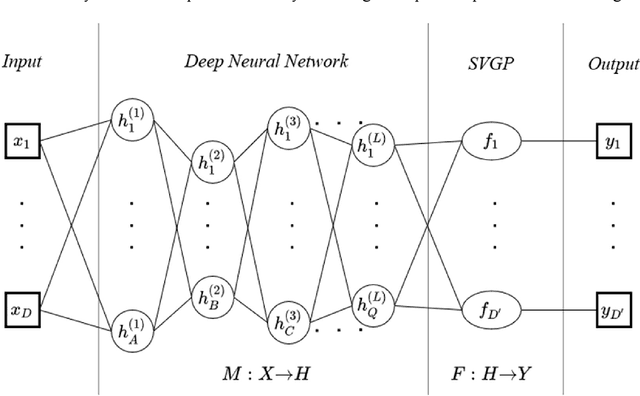
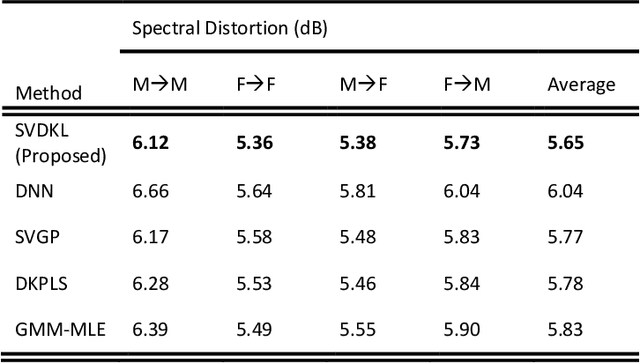
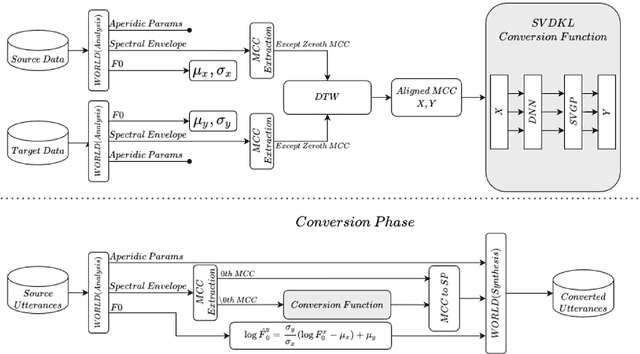
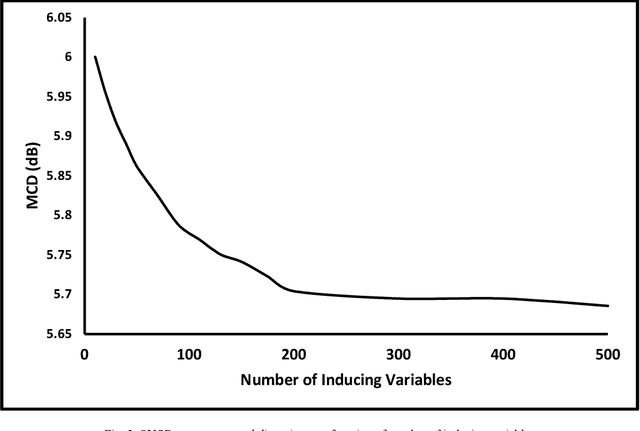
Typically, voice conversion is regarded as an engineering problem with limited training data. The reliance on massive amounts of data hinders the practical applicability of deep learning approaches, which have been extensively researched in recent years. On the other hand, statistical methods are effective with limited data but have difficulties in modelling complex mapping functions. This paper proposes a voice conversion method that works with limited data and is based on stochastic variational deep kernel learning (SVDKL). At the same time, SVDKL enables the use of deep neural networks' expressive capability as well as the high flexibility of the Gaussian process as a Bayesian and non-parametric method. When the conventional kernel is combined with the deep neural network, it is possible to estimate non-smooth and more complex functions. Furthermore, the model's sparse variational Gaussian process solves the scalability problem and, unlike the exact Gaussian process, allows for the learning of a global mapping function for the entire acoustic space. One of the most important aspects of the proposed scheme is that the model parameters are trained using marginal likelihood optimization, which considers both data fitting and model complexity. Considering the complexity of the model reduces the amount of training data by increasing the resistance to overfitting. To evaluate the proposed scheme, we examined the model's performance with approximately 80 seconds of training data. The results indicated that our method obtained a higher mean opinion score, smaller spectral distortion, and better preference tests than the compared methods.
Fast Classification with Sequential Feature Selection in Test Phase
Jun 25, 2023This paper introduces a novel approach to active feature acquisition for classification, which is the task of sequentially selecting the most informative subset of features to achieve optimal prediction performance during testing while minimizing cost. The proposed approach involves a new lazy model that is significantly faster and more efficient compared to existing methods, while still producing comparable accuracy results. During the test phase, the proposed approach utilizes Fisher scores for feature ranking to identify the most important feature at each step. In the next step the training dataset is filtered based on the observed value of the selected feature and then we continue this process to reach to acceptable accuracy or limit of the budget for feature acquisition. The performance of the proposed approach was evaluated on synthetic and real datasets, including our new synthetic dataset, CUBE dataset and also real dataset Forest. The experimental results demonstrate that our approach achieves competitive accuracy results compared to existing methods, while significantly outperforming them in terms of speed. The source code of the algorithm is released at github with this link: https://github.com/alimirzaei/FCwSFS.
Progressive Transmission using Recurrent Neural Networks
Aug 03, 2021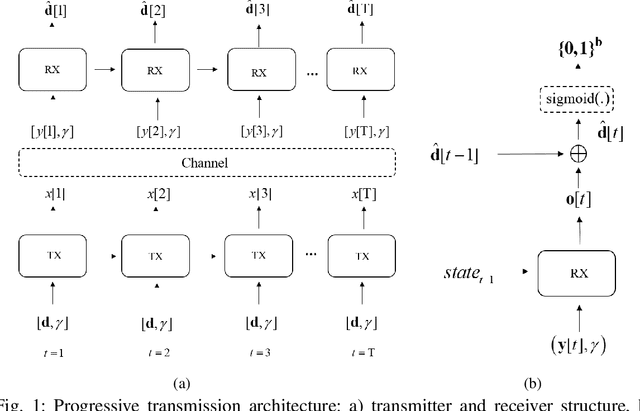

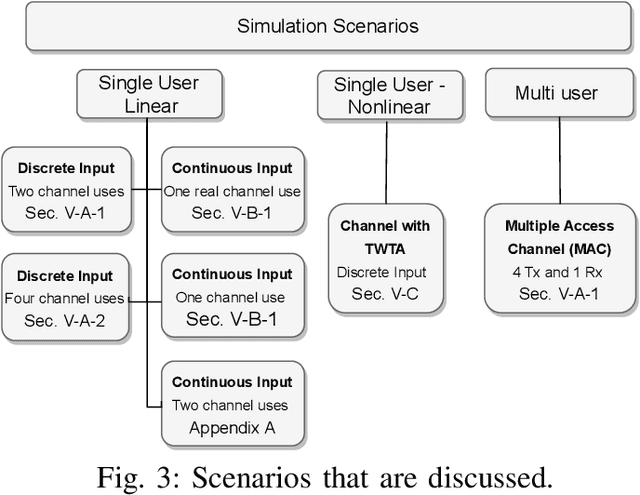
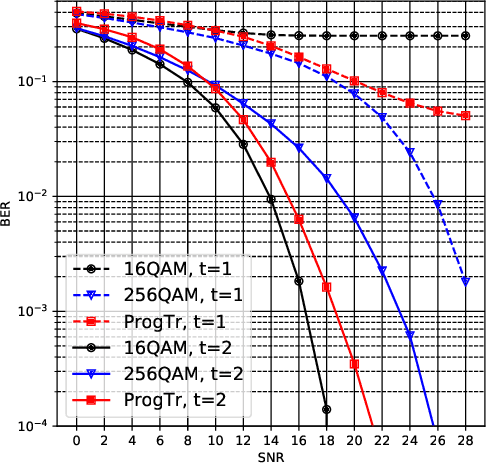
In this paper, we investigate a new machine learning-based transmission strategy called progressive transmission or ProgTr. In ProgTr, there are b variables that should be transmitted using at most T channel uses. The transmitter aims to send the data to the receiver as fast as possible and with as few channel uses as possible (as channel conditions permit) while the receiver refines its estimate after each channel use. We use recurrent neural networks as the building block of both the transmitter and receiver where the SNR is provided as an input that represents the channel conditions. To show how ProgTr works, the proposed scheme was simulated in different scenarios including single/multi-user settings, different channel conditions, and for both discrete and continuous input data. The results show that ProgTr can achieve better performance compared to conventional modulation methods. In addition to performance metrics such as BER, bit-wise mutual information is used to provide some interpretation to how the transmitter and receiver operate in ProgTr.
Propagation Channel Modeling by Deep learning Techniques
Aug 19, 2019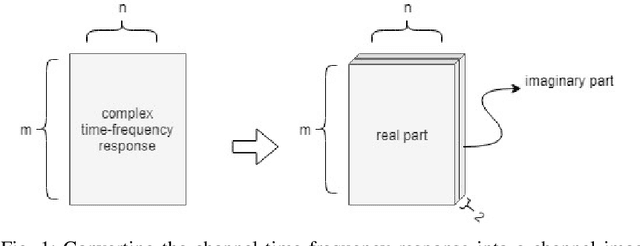
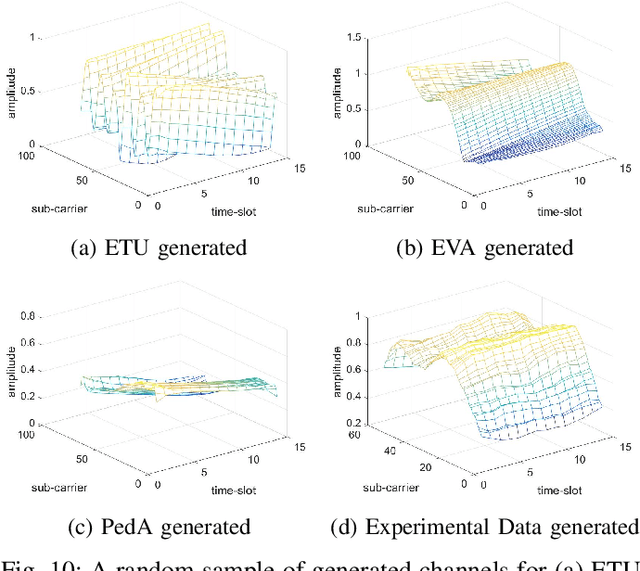
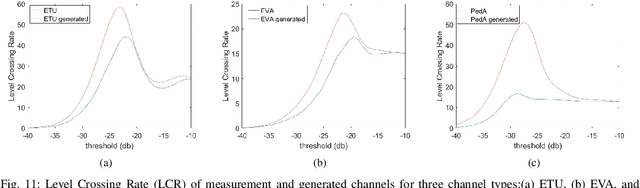
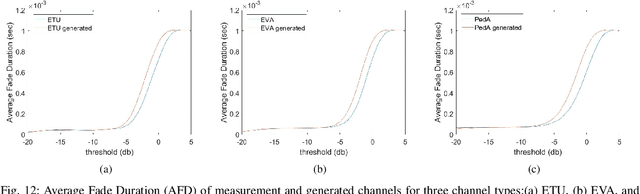
Channel, as the medium for the propagation of electromagnetic waves, is one of the most important parts of a communication system. Being aware of how the channel affects the propagation waves is essential for designing, optimization and performance analysis of a communication system. For this purpose, a proper channel model is needed. This paper presents a novel propagation channel model which considers the time-frequency response of the channel as an image. It models the distribution of these channel images using Deep Convolutional Generative Adversarial Networks. Moreover, for the measurements with different user speeds, the user speed is considered as an auxiliary parameter for the model. StarGAN as an image-to-image translation technique is used to change the generated channel images with respect to the desired user speed. The performance of the proposed model is evaluated using existing metrics. Furthermore, to capture 2D similarity in both time and frequency, a new metric is introduced. Using this metric, the generated channels show significant statistical similarity to the measurement data.
Deep Feature Selection using a Teacher-Student Network
Mar 17, 2019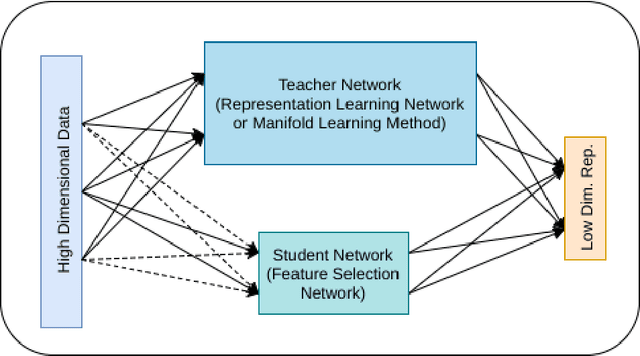

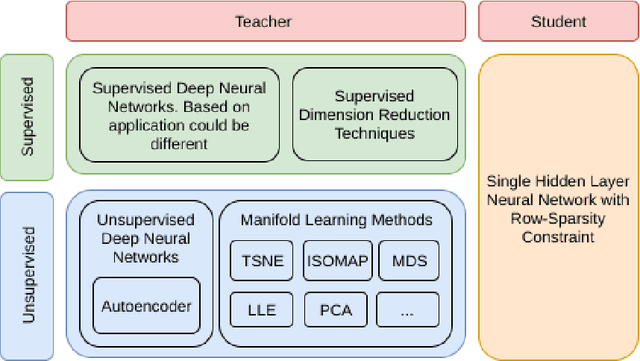

High-dimensional data in many machine learning applications leads to computational and analytical complexities. Feature selection provides an effective way for solving these problems by removing irrelevant and redundant features, thus reducing model complexity and improving accuracy and generalization capability of the model. In this paper, we present a novel teacher-student feature selection (TSFS) method in which a 'teacher' (a deep neural network or a complicated dimension reduction method) is first employed to learn the best representation of data in low dimension. Then a 'student' network (a simple neural network) is used to perform feature selection by minimizing the reconstruction error of low dimensional representation. Although the teacher-student scheme is not new, to the best of our knowledge, it is the first time that this scheme is employed for feature selection. The proposed TSFS can be used for both supervised and unsupervised feature selection. This method is evaluated on different datasets and is compared with state-of-the-art existing feature selection methods. The results show that TSFS performs better in terms of classification and clustering accuracies and reconstruction error. Moreover, experimental evaluations demonstrate a low degree of sensitivity to parameter selection in the proposed method.