 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel and Limited Data Voice Conversion Using Stochastic Variational Deep Kernel Learning
Sep 08, 2023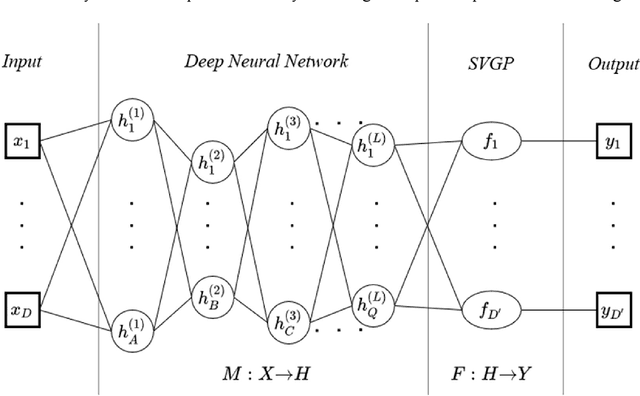
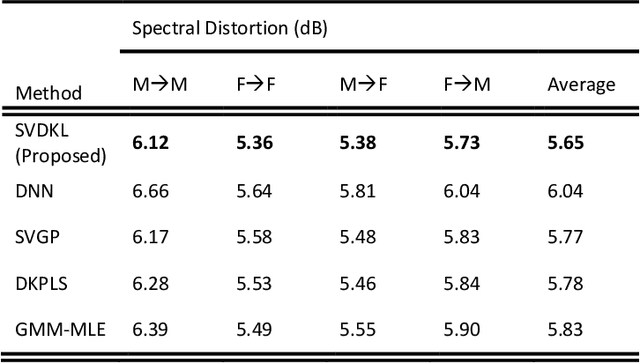
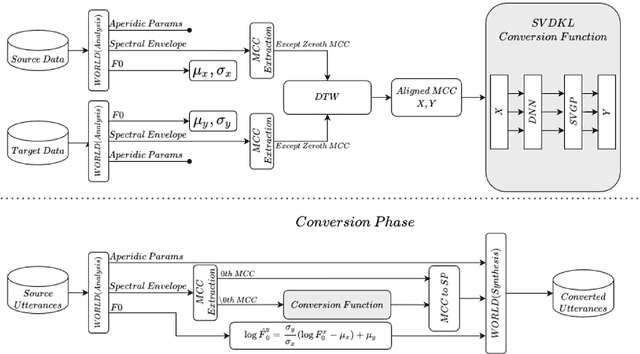
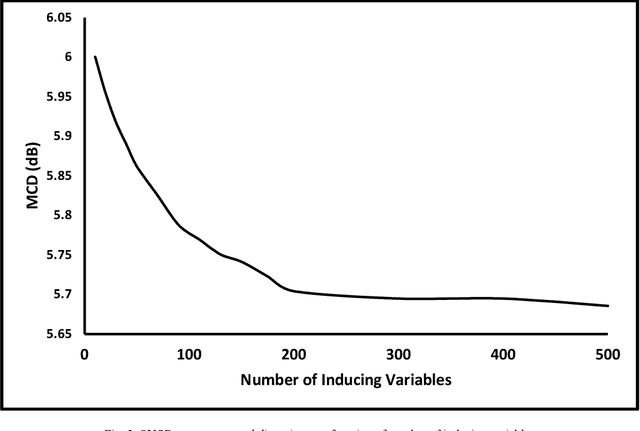
Typically, voice conversion is regarded as an engineering problem with limited training data. The reliance on massive amounts of data hinders the practical applicability of deep learning approaches, which have been extensively researched in recent years. On the other hand, statistical methods are effective with limited data but have difficulties in modelling complex mapping functions. This paper proposes a voice conversion method that works with limited data and is based on stochastic variational deep kernel learning (SVDKL). At the same time, SVDKL enables the use of deep neural networks' expressive capability as well as the high flexibility of the Gaussian process as a Bayesian and non-parametric method. When the conventional kernel is combined with the deep neural network, it is possible to estimate non-smooth and more complex functions. Furthermore, the model's sparse variational Gaussian process solves the scalability problem and, unlike the exact Gaussian process, allows for the learning of a global mapping function for the entire acoustic space. One of the most important aspects of the proposed scheme is that the model parameters are trained using marginal likelihood optimization, which considers both data fitting and model complexity. Considering the complexity of the model reduces the amount of training data by increasing the resistance to overfitting. To evaluate the proposed scheme, we examined the model's performance with approximately 80 seconds of training data. The results indicated that our method obtained a higher mean opinion score, smaller spectral distortion, and better preference tests than the compared methods.
Sleep Stage Scoring Using Joint Frequency-Temporal and Unsupervised Features
Apr 10, 2020

Patients with sleep disorders can better manage their lifestyle if they know about their special situations. Detection of such sleep disorders is usually possible by analyzing a number of vital signals that have been collected from the patients. To simplify this task, a number of Automatic Sleep Stage Recognition (ASSR) methods have been proposed. Most of these methods use temporal-frequency features that have been extracted from the vital signals. However, due to the non-stationary nature of sleep signals, such schemes are not leading an acceptable accuracy. Recently, some ASSR methods have been proposed which use deep neural networks for unsupervised feature extraction. In this paper, we proposed to combine the two ideas and use both temporal-frequency and unsupervised features at the same time. To augment the time resolution, each standard epoch is segmented into 5 sub-epochs. Additionally, to enhance the accuracy, we employ three classifiers with different properties and then use an ensemble method as the ultimate classifier. The simulation results show that the proposed method enhances the accuracy of conventional ASSR methods.