 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing wildfire susceptibility in Iran: Leveraging machine learning for geospatial analysis of climatic and anthropogenic factors
May 20, 2025This study investigates the multifaceted factors influencing wildfire risk in Iran, focusing on the interplay between climatic conditions and human activities. Utilizing advanced remote sensing, geospatial information system (GIS) processing techniques such as cloud computing, and machine learning algorithms, this research analyzed the impact of climatic parameters, topographic features, and human-related factors on wildfire susceptibility assessment and prediction in Iran. Multiple scenarios were developed for this purpose based on the data sampling strategy. The findings revealed that climatic elements such as soil moisture, temperature, and humidity significantly contribute to wildfire susceptibility, while human activities-particularly population density and proximity to powerlines-also played a crucial role. Furthermore, the seasonal impact of each parameter was separately assessed during warm and cold seasons. The results indicated that human-related factors, rather than climatic variables, had a more prominent influence during the seasonal analyses. This research provided new insights into wildfire dynamics in Iran by generating high-resolution wildfire susceptibility maps using advanced machine learning classifiers. The generated maps identified high risk areas, particularly in the central Zagros region, the northeastern Hyrcanian Forest, and the northern Arasbaran forest, highlighting the urgent need for effective fire management strategies.
Enhancing crop classification accuracy by synthetic SAR-Optical data generation using deep learning
Feb 03, 2024Crop classification using remote sensing data has emerged as a prominent research area in recent decades. Studies have demonstrated that fusing SAR and optical images can significantly enhance the accuracy of classification. However, a major challenge in this field is the limited availability of training data, which adversely affects the performance of classifiers. In agricultural regions, the dominant crops typically consist of one or two specific types, while other crops are scarce. Consequently, when collecting training samples to create a map of agricultural products, there is an abundance of samples from the dominant crops, forming the majority classes. Conversely, samples from other crops are scarce, representing the minority classes. Addressing this issue requires overcoming several challenges and weaknesses associated with traditional data generation methods. These methods have been employed to tackle the imbalanced nature of the training data. Nevertheless, they still face limitations in effectively handling the minority classes. Overall, the issue of inadequate training data, particularly for minority classes, remains a hurdle that traditional methods struggle to overcome. In this research, We explore the effectiveness of conditional tabular generative adversarial network (CTGAN) as a synthetic data generation method based on a deep learning network, in addressing the challenge of limited training data for minority classes in crop classification using the fusion of SAR-optical data. Our findings demonstrate that the proposed method generates synthetic data with higher quality that can significantly increase the number of samples for minority classes leading to better performance of crop classifiers.
Fast Classification with Sequential Feature Selection in Test Phase
Jun 25, 2023This paper introduces a novel approach to active feature acquisition for classification, which is the task of sequentially selecting the most informative subset of features to achieve optimal prediction performance during testing while minimizing cost. The proposed approach involves a new lazy model that is significantly faster and more efficient compared to existing methods, while still producing comparable accuracy results. During the test phase, the proposed approach utilizes Fisher scores for feature ranking to identify the most important feature at each step. In the next step the training dataset is filtered based on the observed value of the selected feature and then we continue this process to reach to acceptable accuracy or limit of the budget for feature acquisition. The performance of the proposed approach was evaluated on synthetic and real datasets, including our new synthetic dataset, CUBE dataset and also real dataset Forest. The experimental results demonstrate that our approach achieves competitive accuracy results compared to existing methods, while significantly outperforming them in terms of speed. The source code of the algorithm is released at github with this link: https://github.com/alimirzaei/FCwSFS.
Deep Feature Selection using a Teacher-Student Network
Mar 17, 2019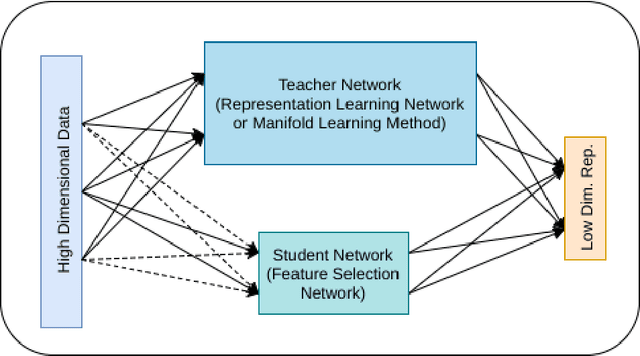

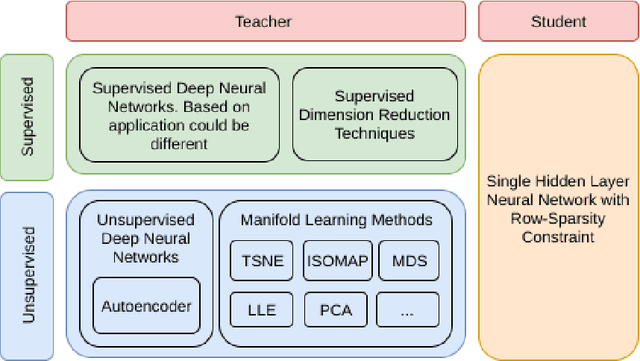

High-dimensional data in many machine learning applications leads to computational and analytical complexities. Feature selection provides an effective way for solving these problems by removing irrelevant and redundant features, thus reducing model complexity and improving accuracy and generalization capability of the model. In this paper, we present a novel teacher-student feature selection (TSFS) method in which a 'teacher' (a deep neural network or a complicated dimension reduction method) is first employed to learn the best representation of data in low dimension. Then a 'student' network (a simple neural network) is used to perform feature selection by minimizing the reconstruction error of low dimensional representation. Although the teacher-student scheme is not new, to the best of our knowledge, it is the first time that this scheme is employed for feature selection. The proposed TSFS can be used for both supervised and unsupervised feature selection. This method is evaluated on different datasets and is compared with state-of-the-art existing feature selection methods. The results show that TSFS performs better in terms of classification and clustering accuracies and reconstruction error. Moreover, experimental evaluations demonstrate a low degree of sensitivity to parameter selection in the proposed method.