 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Hair Simulation Using Image Blending
Apr 19, 2019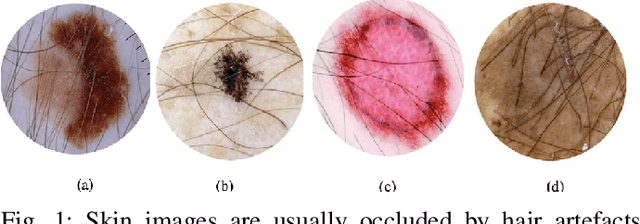

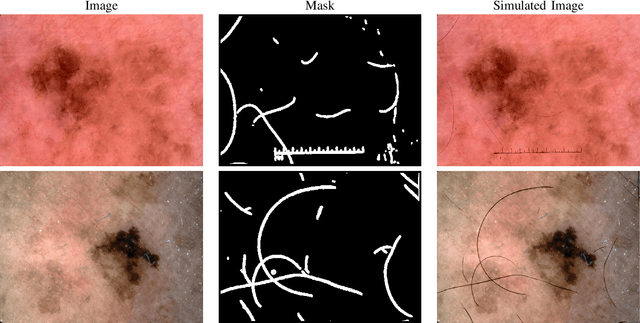
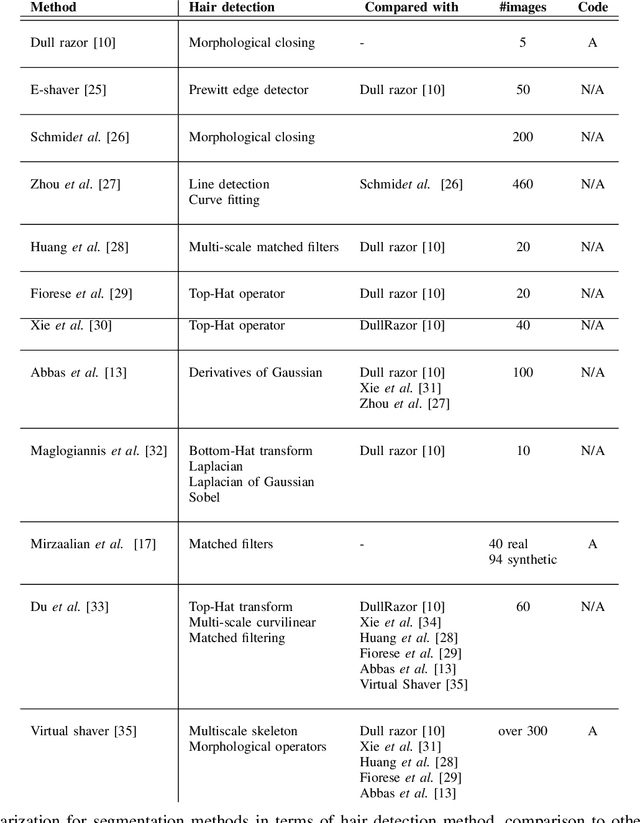
In this presented work, we propose a realistic hair simulator using image blending for dermoscopic images. This hair simulator can be used for benchmarking and validation of the hair removal methods and in data augmentation for improving computer aided diagnostic tools. We adopted one of the popular implementation of image blending to superimpose realistic hair masks to hair lesion. This method was able to produce realistic hair masks according to a predefined mask for hair. Thus, the produced hair images and masks can be used as ground truth for hair segmentation and removal methods by inpainting hair according to a pre-defined hair masks on hairfree areas. Also, we achieved a realism score equals to 1.65 in comparison to 1.59 for the state-of-the-art hair simulator.
Covfefe: A Computer Vision Approach For Estimating Force Exertion
Sep 25, 2018
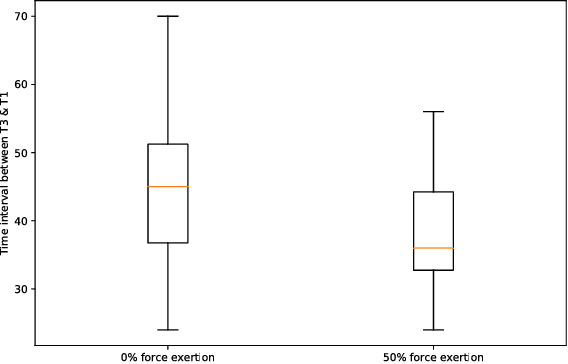


Cumulative exposure to repetitive and forceful activities may lead to musculoskeletal injuries which not only reduce workers' efficiency and productivity, but also affect their quality of life. Thus, widely accessible techniques for reliable detection of unsafe muscle force exertion levels for human activity is necessary for their well-being. However, measurement of force exertion levels is challenging and the existing techniques pose a great challenge as they are either intrusive, interfere with human-machine interface, and/or subjective in the nature, thus are not scalable for all workers. In this work, we use face videos and the photoplethysmography (PPG) signals to classify force exertion levels of 0\%, 50\%, and 100\% (representing rest, moderate effort, and high effort), thus providing a non-intrusive and scalable approach. Efficient feature extraction approaches have been investigated, including standard deviation of the movement of different landmarks of the face, distances between peaks and troughs in the PPG signals. We note that the PPG signals can be obtained from the face videos, thus giving an efficient classification algorithm for the force exertion levels using face videos. Based on the data collected from 20 subjects, features extracted from the face videos give 90\% accuracy in classification among the 100\% and the combination of 0\% and 50\% datasets. Further combining the PPG signals provide 81.7\% accuracy. The approach is also shown to be robust to the correctly identify force level when the person is talking, even though such datasets are not included in the training.