 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Data-driven Framework for Anxiety Screening
Mar 16, 2023Early screening for anxiety and appropriate interventions are essential to reduce the incidence of self-harm and suicide in patients. Due to limited medical resources, traditional methods that overly rely on physician expertise and specialized equipment cannot simultaneously meet the needs for high accuracy and model interpretability. Multimodal data can provide more objective evidence for anxiety screening to improve the accuracy of models. The large amount of noise in multimodal data and the unbalanced nature of the data make the model prone to overfitting. However, it is a non-differentiable problem when high-dimensional and multimodal feature combinations are used as model inputs and incorporated into model training. This causes existing anxiety screening methods based on machine learning and deep learning to be inapplicable. Therefore, we propose a multimodal data-driven anxiety screening framework, namely MMD-AS, and conduct experiments on the collected health data of over 200 seafarers by smartphones. The proposed framework's feature extraction, dimension reduction, feature selection, and anxiety inference are jointly trained to improve the model's performance. In the feature selection step, a feature selection method based on the Improved Fireworks Algorithm is used to solve the non-differentiable problem of feature combination to remove redundant features and search for the ideal feature subset. The experimental results show that our framework outperforms the comparison methods.
A Lite Fireworks Algorithm with Fractal Dimension Constraint for Feature Selection
Mar 09, 2023As the use of robotics becomes more widespread, the huge amount of vision data leads to a dramatic increase in data dimensionality. Although deep learning methods can effectively process these high-dimensional vision data. Due to the limitation of computational resources, some special scenarios still rely on traditional machine learning methods. However, these high-dimensional visual data lead to great challenges for traditional machine learning methods. Therefore, we propose a Lite Fireworks Algorithm with Fractal Dimension constraint for feature selection (LFWA+FD) and use it to solve the feature selection problem driven by robot vision. The "LFWA+FD" focuses on searching the ideal feature subset by simplifying the fireworks algorithm and constraining the dimensionality of selected features by fractal dimensionality, which in turn reduces the approximate features and reduces the noise in the original data to improve the accuracy of the model. The comparative experimental results of two publicly available datasets from UCI show that the proposed method can effectively select a subset of features useful for model inference and remove a large amount of noise noise present in the original data to improve the performance.
A Lite Fireworks Algorithm for Optimization
Jan 07, 2023
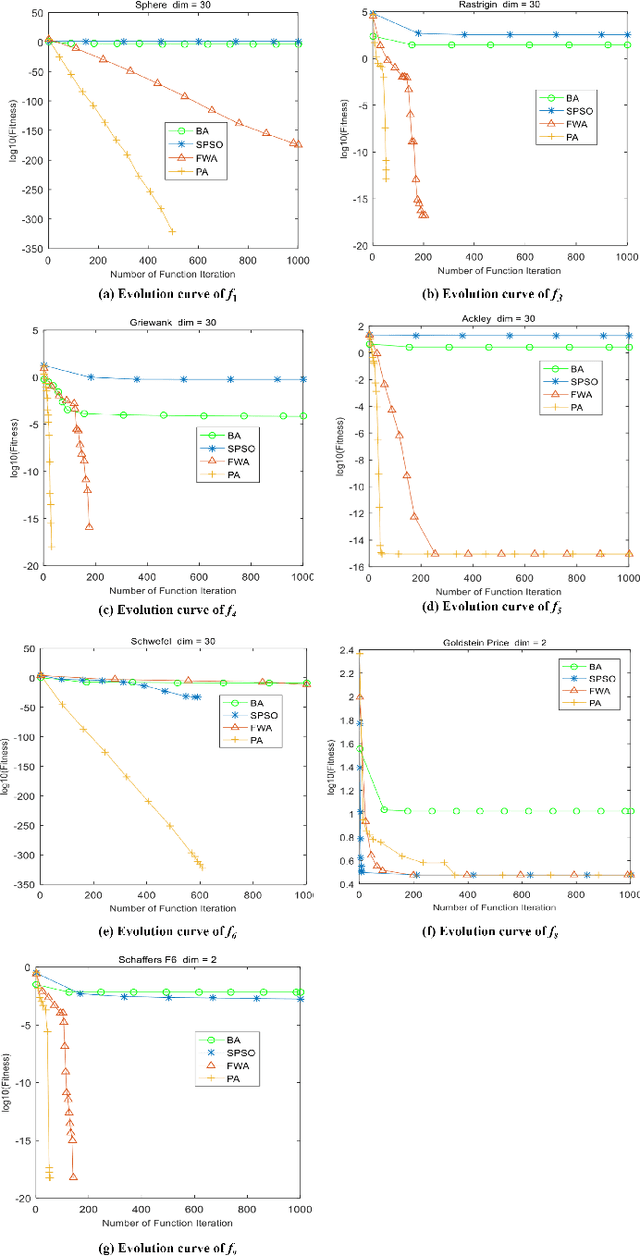


The fireworks algorithm is an optimization algorithm for simulating the explosion phenomenon of fireworks. Because of its fast convergence and high precision, it is widely used in pattern recognition, optimal scheduling, and other fields. However, most of the existing research work on the fireworks algorithm is improved based on its defects, and little consideration is given to reducing the number of parameters of the fireworks algorithm. The original fireworks algorithm has too many parameters, which increases the cost of algorithm adjustment and is not conducive to engineering applications. In addition, in the fireworks population, the unselected individuals are discarded, thus causing a waste of their location information. To reduce the number of parameters of the original Fireworks Algorithm and make full use of the location information of discarded individuals, we propose a simplified version of the Fireworks Algorithm. It reduces the number of algorithm parameters by redesigning the explosion operator of the fireworks algorithm and constructs an adaptive explosion radius by using the historical optimal information to balance the local mining and global exploration capabilities. The comparative experimental results of function optimization show that the overall performance of our proposed LFWA is better than that of comparative algorithms, such as the fireworks algorithm, particle swarm algorithm, and bat algorithm.
SFF-DA: Sptialtemporal Feature Fusion for Detecting Anxiety Nonintrusively
Aug 12, 2022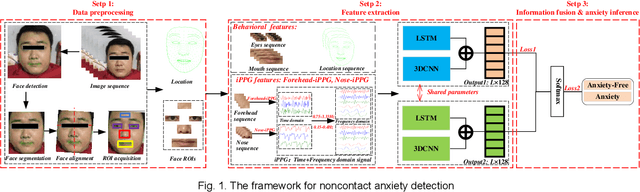
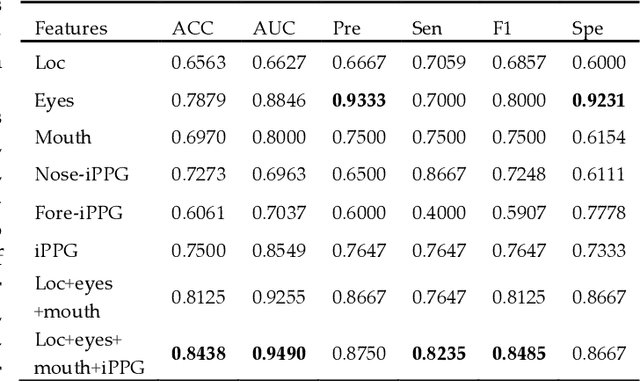
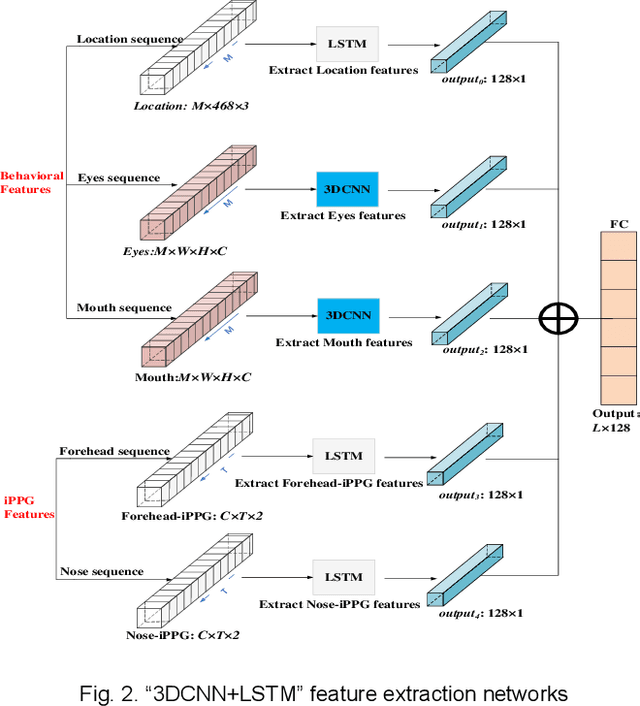

Early detection of anxiety disorders is essential to reduce the suffering of people with mental disorders and to improve treatment outcomes. Anxiety screening based on the mHealth platform is of particular practical value in improving screening efficiency and reducing screening costs. In practice, differences in mobile devices in subjects' physical and mental evaluations and the problems faced with uneven data quality and small sample sizes of data in the real world have made existing methods ineffective. Therefore, we propose a framework based on spatiotemporal feature fusion for detecting anxiety nonintrusively. To reduce the impact of uneven data quality, we constructed a feature extraction network based on "3DCNN+LSTM" and fused spatiotemporal features of facial behavior and noncontact physiology. Moreover, we designed a similarity assessment strategy to solve the problem that the small sample size of data leads to a decline in model accuracy. Our framework was validated with our crew dataset from the real world and two public datasets, UBFC-PHYS and SWELL-KW. The experimental results show that the overall performance of our framework was better than that of the state-of-the-art comparison methods.
The Role of Edge Robotics As-a-Service in Monitoring COVID-19 Infection
Dec 09, 2020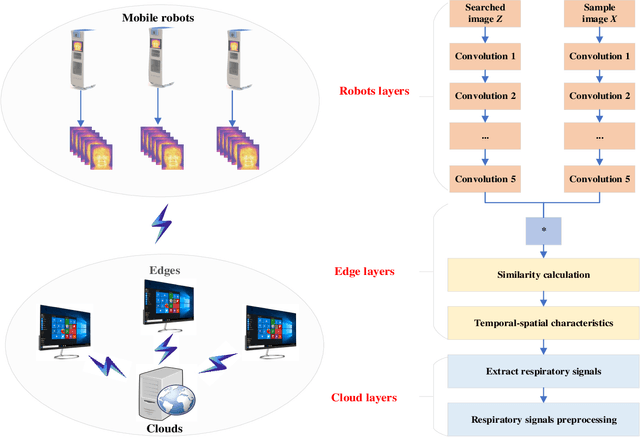
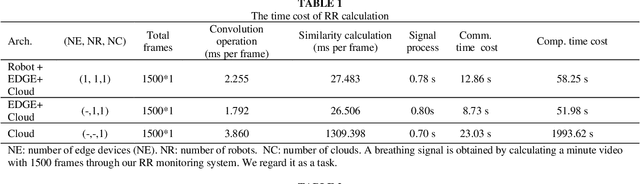
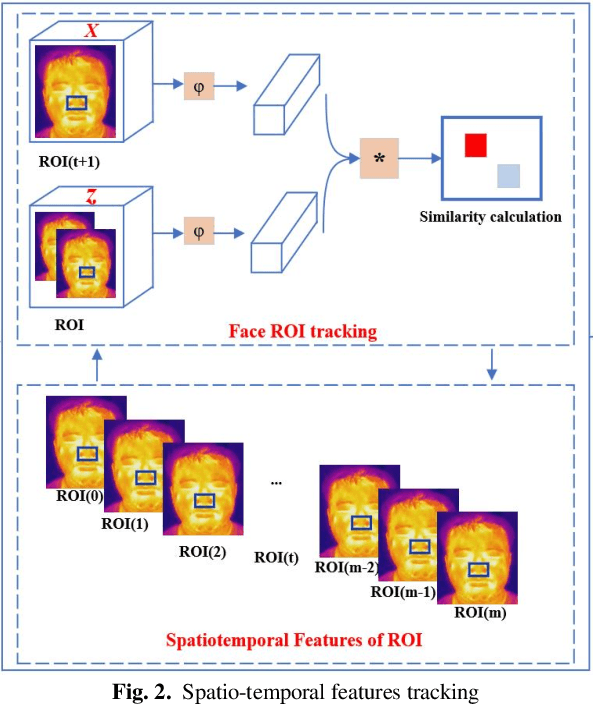
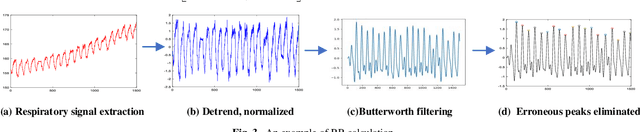
Deep learning technology has been widely used in edge computing. However, pandemics like covid-19 require deep learning capabilities at mobile devices (detect respiratory rate using mobile robotics or conduct CT scan using a mobile scanner), which are severely constrained by the limited storage and computation resources at the device level. To solve this problem, we propose a three-tier architecture, including robot layers, edge layers, and cloud layers. We adopt this architecture to design a non-contact respiratory monitoring system to break down respiratory rate calculation tasks. Experimental results of respiratory rate monitoring show that the proposed approach in this paper significantly outperforms other approaches. It is supported by computation time costs with 2.26 ms per frame, 27.48 ms per frame, 0.78 seconds for convolution operation, similarity calculation, processing one-minute length respiratory signals, respectively. And the computation time costs of our three-tier architecture are less than that of edge+cloud architecture and cloud architecture. Moreover, we use our three-tire architecture for CT image diagnosis task decomposition. The evaluation of a CT image dataset of COVID-19 proves that our three-tire architecture is useful for resolving tasks on deep learning networks by edge equipment. There are broad application scenarios in smart hospitals in the future.