 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Sparse Subnetworks in One Training Cycle via Progressive Magnitude-Based Pruning
Jun 10, 2026Neural network pruning reduces model size by removing less important parameters while aiming to preserve predictive performance. Although the Lottery Ticket Hypothesis (LTH) shows that sparse subnetworks can match dense networks when trained from suitable initializations, its iterative pruning procedure requires multiple complete training cycles. This work evaluates progressive magnitude-based pruning as a single-cycle alternative. The method gradually increases sparsity during training using a linear schedule and updates pruning masks based on active weight magnitudes. We conduct systematic experiments on CIFAR-10 and MNIST across ResNet, VGG-style, and LeNet architectures, comparing the proposed method with representative iterative and initialization-based pruning baselines, including LTH, SNIP, and GraSP. On CIFAR-10, the method achieves 95.12\% accuracy on ResNet-18 at 72.9\% sparsity, compared with 90.5\% reported for LTH. At extreme sparsity, it achieves 93.13\% accuracy on a VGG-like architecture at 97\% sparsity, compared with approximately 92.0\% for SNIP, and 93.44\% accuracy on VGG-19 at 97.97\% sparsity, compared with 92.19\% for GraSP at 98\% sparsity. A sparsity-accuracy analysis on ResNet-18 further shows that accuracy remains within 0.1 percentage points of the dense baseline across 70--85\% sparsity. These results indicate that progressive magnitude-based pruning provides an effective single-cycle approach for neural network sparsification under the evaluated settings.
A Survey of Latent Factor Models in Recommender Systems
May 28, 2024
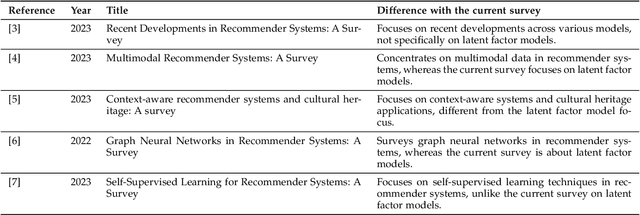
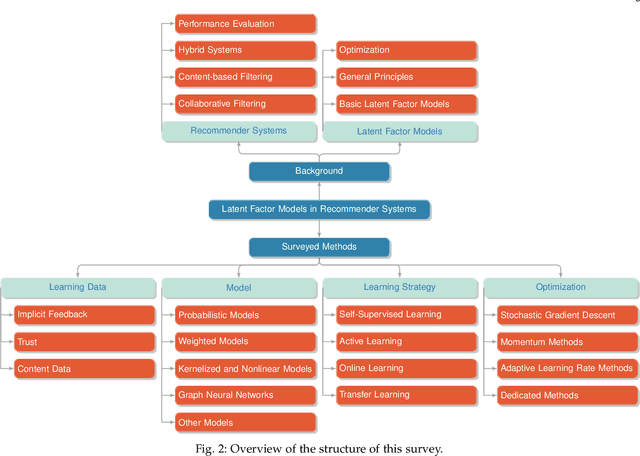
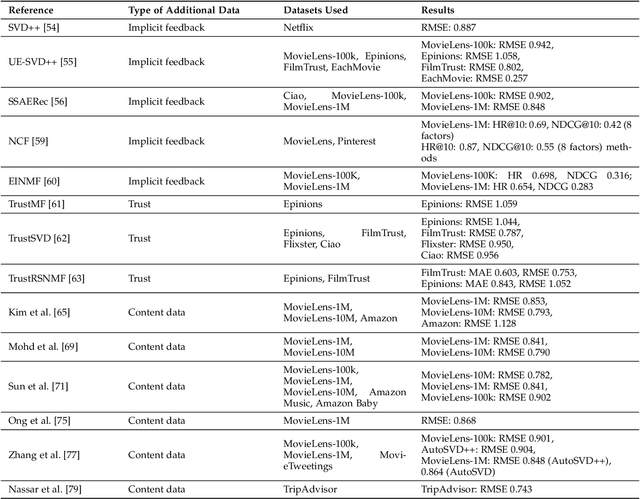
Recommender systems are essential tools in the digital era, providing personalized content to users in areas like e-commerce, entertainment, and social media. Among the many approaches developed to create these systems, latent factor models have proven particularly effective. This survey systematically reviews latent factor models in recommender systems, focusing on their core principles, methodologies, and recent advancements. The literature is examined through a structured framework covering learning data, model architecture, learning strategies, and optimization techniques. The analysis includes a taxonomy of contributions and detailed discussions on the types of learning data used, such as implicit feedback, trust, and content data, various models such as probabilistic, nonlinear, and neural models, and an exploration of diverse learning strategies like online learning, transfer learning, and active learning. Furthermore, the survey addresses the optimization strategies used to train latent factor models, improving their performance and scalability. By identifying trends, gaps, and potential research directions, this survey aims to provide valuable insights for researchers and practitioners looking to advance the field of recommender systems.
A Sequence-to-Sequence Approach for Arabic Pronoun Resolution
May 19, 2023
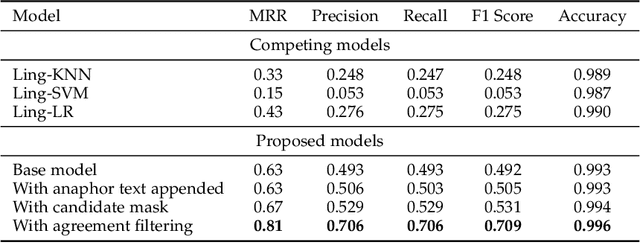
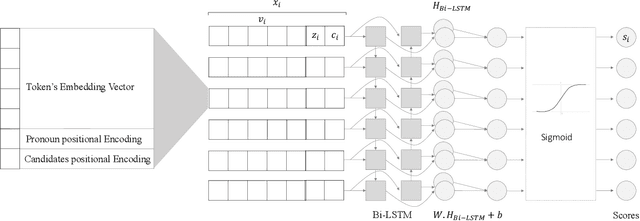

This paper proposes a sequence-to-sequence learning approach for Arabic pronoun resolution, which explores the effectiveness of using advanced natural language processing (NLP) techniques, specifically Bi-LSTM and the BERT pre-trained Language Model, in solving the pronoun resolution problem in Arabic. The proposed approach is evaluated on the AnATAr dataset, and its performance is compared to several baseline models, including traditional machine learning models and handcrafted feature-based models. Our results demonstrate that the proposed model outperforms the baseline models, which include KNN, logistic regression, and SVM, across all metrics. In addition, we explore the effectiveness of various modifications to the model, including concatenating the anaphor text beside the paragraph text as input, adding a mask to focus on candidate scores, and filtering candidates based on gender and number agreement with the anaphor. Our results show that these modifications significantly improve the model's performance, achieving up to 81% on MRR and 71% for F1 score while also demonstrating higher precision, recall, and accuracy. These findings suggest that the proposed model is an effective approach to Arabic pronoun resolution and highlights the potential benefits of leveraging advanced NLP neural models.
A Complex Network based Graph Embedding Method for Link Prediction
Sep 11, 2022
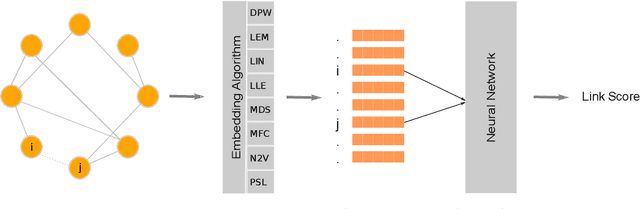
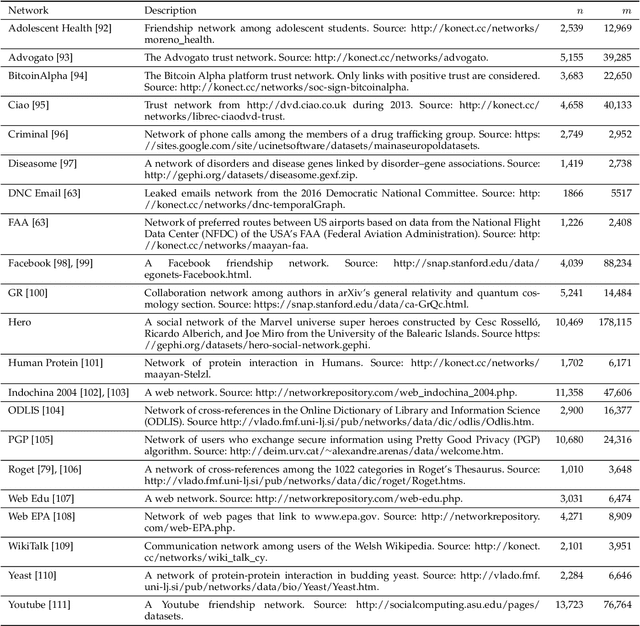
Graph embedding methods aim at finding useful graph representations by mapping nodes to a low-dimensional vector space. It is a task with important downstream applications, such as link prediction, graph reconstruction, data visualization, node classification, and language modeling. In recent years, the field of graph embedding has witnessed a shift from linear algebraic approaches towards local, gradient-based optimization methods combined with random walks and deep neural networks to tackle the problem of embedding large graphs. However, despite this improvement in the optimization tools, graph embedding methods are still generically designed in a way that is oblivious to the particularities of real-life networks. Indeed, there has been significant progress in understanding and modeling complex real-life networks in recent years. However, the obtained results have had a minor influence on the development of graph embedding algorithms. This paper aims to remedy this by designing a graph embedding method that takes advantage of recent valuable insights from the field of network science. More precisely, we present a novel graph embedding approach based on the popularity-similarity and local attraction paradigms. We evaluate the performance of the proposed approach on the link prediction task on a large number of real-life networks. We show, using extensive experimental analysis, that the proposed method outperforms state-of-the-art graph embedding algorithms. We also demonstrate its robustness to data scarcity and the choice of embedding dimensionality.
An Approach for Link Prediction in Directed Complex Networks based on Asymmetric Similarity-Popularity
Jul 15, 2022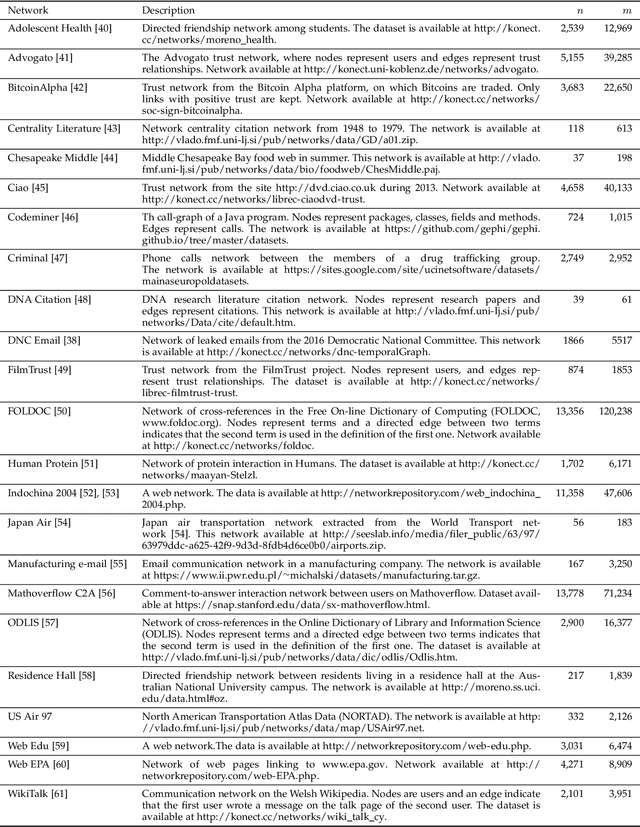
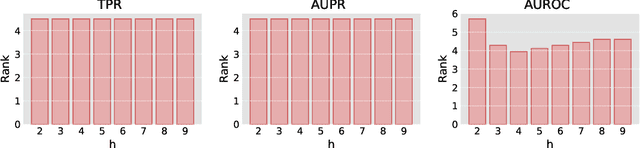
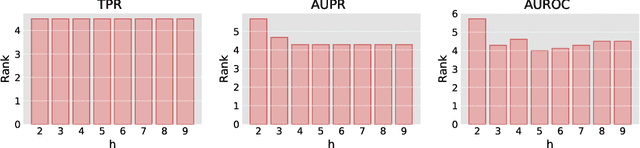
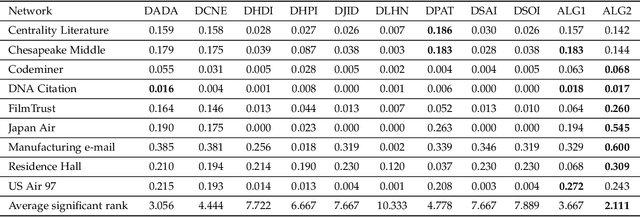
Complex networks are graphs representing real-life systems that exhibit unique characteristics not found in purely regular or completely random graphs. The study of such systems is vital but challenging due to the complexity of the underlying processes. This task has nevertheless been made easier in recent decades thanks to the availability of large amounts of networked data. Link prediction in complex networks aims to estimate the likelihood that a link between two nodes is missing from the network. Links can be missing due to imperfections in data collection or simply because they are yet to appear. Discovering new relationships between entities in networked data has attracted researchers' attention in various domains such as sociology, computer science, physics, and biology. Most existing research focuses on link prediction in undirected complex networks. However, not all real-life systems can be faithfully represented as undirected networks. This simplifying assumption is often made when using link prediction algorithms but inevitably leads to loss of information about relations among nodes and degradation in prediction performance. This paper introduces a link prediction method designed explicitly for directed networks. It is based on the similarity-popularity paradigm, which has recently proven successful in undirected networks. The presented algorithms handle the asymmetry in node relationships by modeling it as asymmetry in similarity and popularity. Given the observed network topology, the algorithms approximate the hidden similarities as shortest path distances using edge weights that capture and factor out the links' asymmetry and nodes' popularity. The proposed approach is evaluated on real-life networks, and the experimental results demonstrate its effectiveness in predicting missing links across a broad spectrum of networked data types and sizes.
Image Captioning based on Feature Refinement and Reflective Decoding
Jun 16, 2022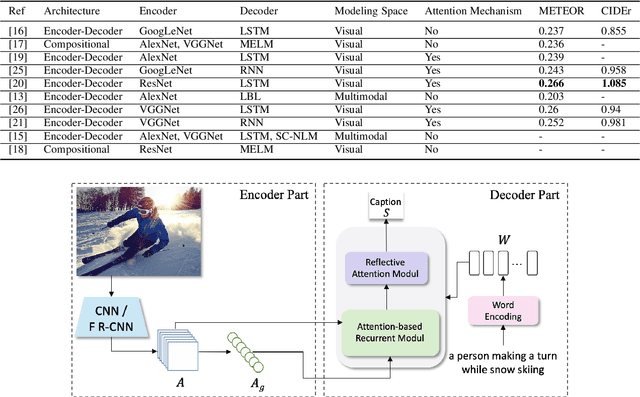
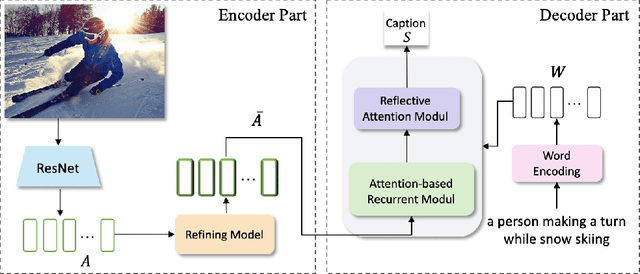
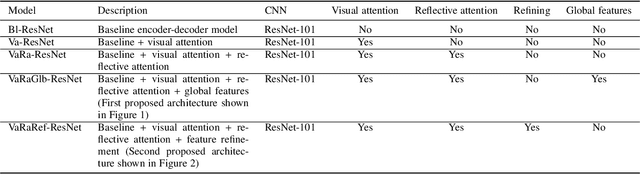
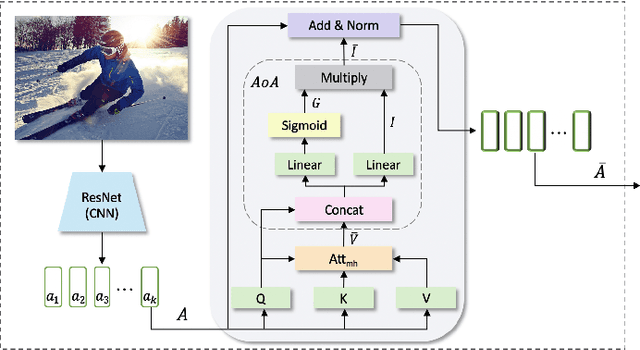
Automatically generating a description of an image in natural language is called image captioning. It is an active research topic that lies at the intersection of two major fields in artificial intelligence, computer vision, and natural language processing. Image captioning is one of the significant challenges in image understanding since it requires not only recognizing salient objects in the image but also their attributes and the way they interact. The system must then generate a syntactically and semantically correct caption that describes the image content in natural language. With the significant progress in deep learning models and their ability to effectively encode large sets of images and generate correct sentences, several neural-based captioning approaches have been proposed recently, each trying to achieve better accuracy and caption quality. This paper introduces an encoder-decoder-based image captioning system in which the encoder extracts spatial and global features for each region in the image using the Faster R-CNN with ResNet-101 as a backbone. This stage is followed by a refining model, which uses an attention-on-attention mechanism to extract the visual features of the target image objects, then determine their interactions. The decoder consists of an attention-based recurrent module and a reflective attention module, which collaboratively apply attention to the visual and textual features to enhance the decoder's ability to model long-term sequential dependencies. Extensive experiments performed on two benchmark datasets, MSCOCO and Flickr30K, show the effectiveness the proposed approach and the high quality of the generated captions.