 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle and Multi-Hop Question-Answering Datasets for Reticular Chemistry with GPT-4-Turbo
May 03, 2024The rapid advancement in artificial intelligence and natural language processing has led to the development of large-scale datasets aimed at benchmarking the performance of machine learning models. Herein, we introduce 'RetChemQA,' a comprehensive benchmark dataset designed to evaluate the capabilities of such models in the domain of reticular chemistry. This dataset includes both single-hop and multi-hop question-answer pairs, encompassing approximately 45,000 Q&As for each type. The questions have been extracted from an extensive corpus of literature containing about 2,530 research papers from publishers including NAS, ACS, RSC, Elsevier, and Nature Publishing Group, among others. The dataset has been generated using OpenAI's GPT-4 Turbo, a cutting-edge model known for its exceptional language understanding and generation capabilities. In addition to the Q&A dataset, we also release a dataset of synthesis conditions extracted from the corpus of literature used in this study. The aim of RetChemQA is to provide a robust platform for the development and evaluation of advanced machine learning algorithms, particularly for the reticular chemistry community. The dataset is structured to reflect the complexities and nuances of real-world scientific discourse, thereby enabling nuanced performance assessments across a variety of tasks. The dataset is available at the following link: https://github.com/nakulrampal/RetChemQA
A Sequence-to-Sequence Approach for Arabic Pronoun Resolution
May 19, 2023
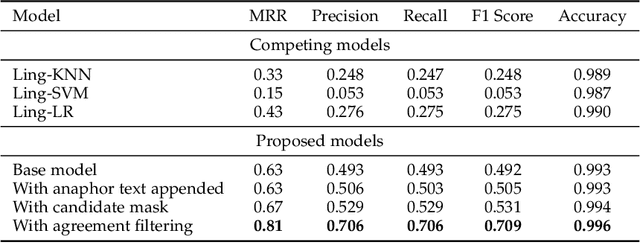
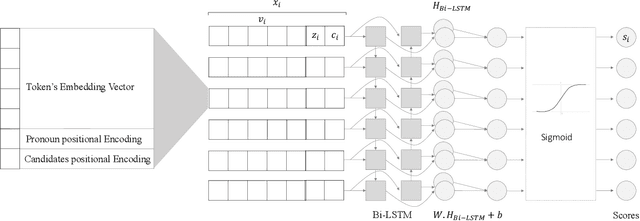

This paper proposes a sequence-to-sequence learning approach for Arabic pronoun resolution, which explores the effectiveness of using advanced natural language processing (NLP) techniques, specifically Bi-LSTM and the BERT pre-trained Language Model, in solving the pronoun resolution problem in Arabic. The proposed approach is evaluated on the AnATAr dataset, and its performance is compared to several baseline models, including traditional machine learning models and handcrafted feature-based models. Our results demonstrate that the proposed model outperforms the baseline models, which include KNN, logistic regression, and SVM, across all metrics. In addition, we explore the effectiveness of various modifications to the model, including concatenating the anaphor text beside the paragraph text as input, adding a mask to focus on candidate scores, and filtering candidates based on gender and number agreement with the anaphor. Our results show that these modifications significantly improve the model's performance, achieving up to 81% on MRR and 71% for F1 score while also demonstrating higher precision, recall, and accuracy. These findings suggest that the proposed model is an effective approach to Arabic pronoun resolution and highlights the potential benefits of leveraging advanced NLP neural models.