 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sequence-to-Sequence Approach for Arabic Pronoun Resolution
Paper and Code
May 19, 2023
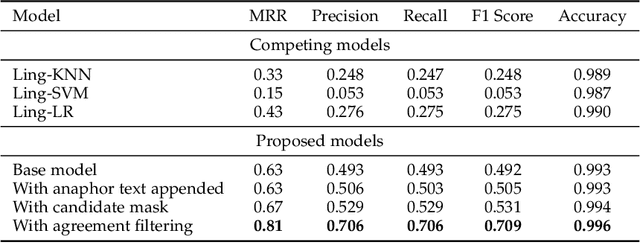
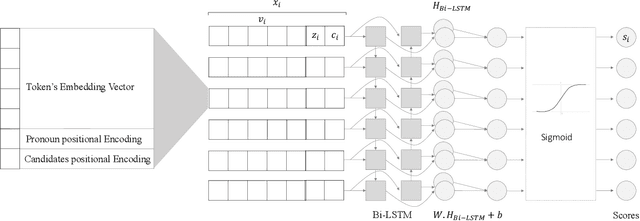

This paper proposes a sequence-to-sequence learning approach for Arabic pronoun resolution, which explores the effectiveness of using advanced natural language processing (NLP) techniques, specifically Bi-LSTM and the BERT pre-trained Language Model, in solving the pronoun resolution problem in Arabic. The proposed approach is evaluated on the AnATAr dataset, and its performance is compared to several baseline models, including traditional machine learning models and handcrafted feature-based models. Our results demonstrate that the proposed model outperforms the baseline models, which include KNN, logistic regression, and SVM, across all metrics. In addition, we explore the effectiveness of various modifications to the model, including concatenating the anaphor text beside the paragraph text as input, adding a mask to focus on candidate scores, and filtering candidates based on gender and number agreement with the anaphor. Our results show that these modifications significantly improve the model's performance, achieving up to 81% on MRR and 71% for F1 score while also demonstrating higher precision, recall, and accuracy. These findings suggest that the proposed model is an effective approach to Arabic pronoun resolution and highlights the potential benefits of leveraging advanced NLP neural models.