 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach for Link Prediction in Directed Complex Networks based on Asymmetric Similarity-Popularity
Jul 15, 2022
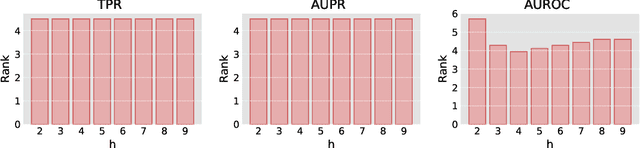
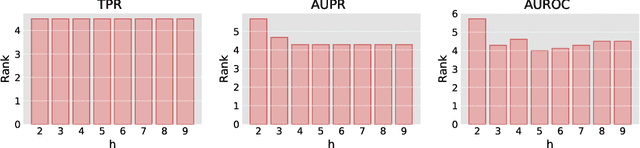
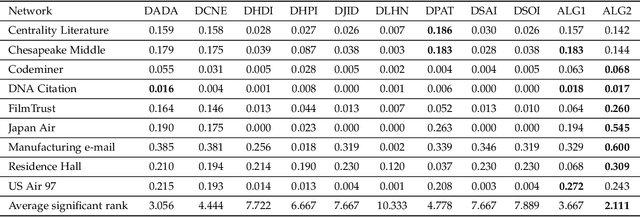
Complex networks are graphs representing real-life systems that exhibit unique characteristics not found in purely regular or completely random graphs. The study of such systems is vital but challenging due to the complexity of the underlying processes. This task has nevertheless been made easier in recent decades thanks to the availability of large amounts of networked data. Link prediction in complex networks aims to estimate the likelihood that a link between two nodes is missing from the network. Links can be missing due to imperfections in data collection or simply because they are yet to appear. Discovering new relationships between entities in networked data has attracted researchers' attention in various domains such as sociology, computer science, physics, and biology. Most existing research focuses on link prediction in undirected complex networks. However, not all real-life systems can be faithfully represented as undirected networks. This simplifying assumption is often made when using link prediction algorithms but inevitably leads to loss of information about relations among nodes and degradation in prediction performance. This paper introduces a link prediction method designed explicitly for directed networks. It is based on the similarity-popularity paradigm, which has recently proven successful in undirected networks. The presented algorithms handle the asymmetry in node relationships by modeling it as asymmetry in similarity and popularity. Given the observed network topology, the algorithms approximate the hidden similarities as shortest path distances using edge weights that capture and factor out the links' asymmetry and nodes' popularity. The proposed approach is evaluated on real-life networks, and the experimental results demonstrate its effectiveness in predicting missing links across a broad spectrum of networked data types and sizes.