 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning based on Feature Refinement and Reflective Decoding
Paper and Code
Jun 16, 2022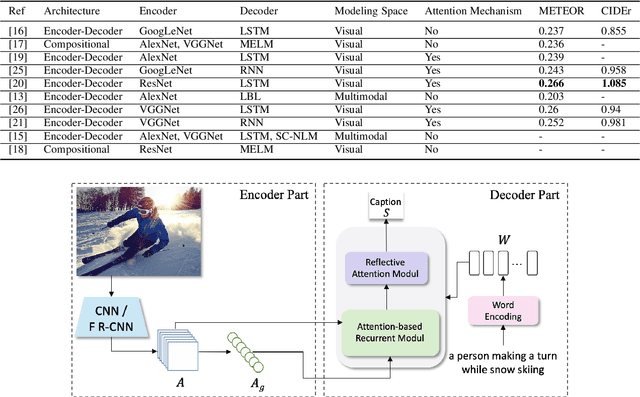
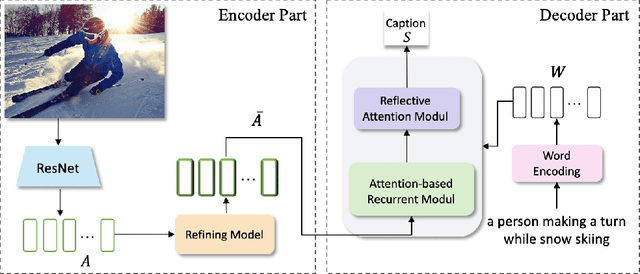
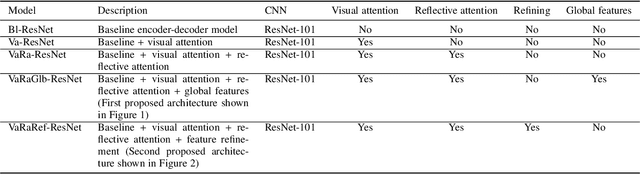
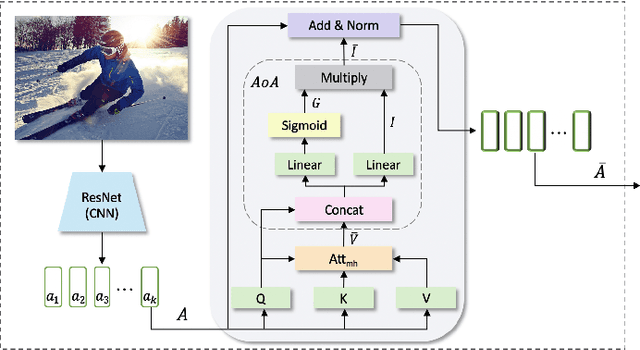
Automatically generating a description of an image in natural language is called image captioning. It is an active research topic that lies at the intersection of two major fields in artificial intelligence, computer vision, and natural language processing. Image captioning is one of the significant challenges in image understanding since it requires not only recognizing salient objects in the image but also their attributes and the way they interact. The system must then generate a syntactically and semantically correct caption that describes the image content in natural language. With the significant progress in deep learning models and their ability to effectively encode large sets of images and generate correct sentences, several neural-based captioning approaches have been proposed recently, each trying to achieve better accuracy and caption quality. This paper introduces an encoder-decoder-based image captioning system in which the encoder extracts spatial and global features for each region in the image using the Faster R-CNN with ResNet-101 as a backbone. This stage is followed by a refining model, which uses an attention-on-attention mechanism to extract the visual features of the target image objects, then determine their interactions. The decoder consists of an attention-based recurrent module and a reflective attention module, which collaboratively apply attention to the visual and textual features to enhance the decoder's ability to model long-term sequential dependencies. Extensive experiments performed on two benchmark datasets, MSCOCO and Flickr30K, show the effectiveness the proposed approach and the high quality of the generated captions.