 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Locally Linear Embedding
Apr 09, 2025Manifold learning techniques, such as Locally linear embedding (LLE), are designed to preserve the local neighborhood structures of high-dimensional data during dimensionality reduction. Traditional LLE employs Euclidean distance to define neighborhoods, which can struggle to capture the intrinsic geometric relationships within complex data. A novel approach, Adaptive locally linear embedding(ALLE), is introduced to address this limitation by incorporating a dynamic, data-driven metric that enhances topological preservation. This method redefines the concept of proximity by focusing on topological neighborhood inclusion rather than fixed distances. By adapting the metric based on the local structure of the data, it achieves superior neighborhood preservation, particularly for datasets with complex geometries and high-dimensional structures. Experimental results demonstrate that ALLE significantly improves the alignment between neighborhoods in the input and feature spaces, resulting in more accurate and topologically faithful embeddings. This approach advances manifold learning by tailoring distance metrics to the underlying data, providing a robust solution for capturing intricate relationships in high-dimensional datasets.
RELF: Robust Regression Extended with Ensemble Loss Function
Oct 25, 2018

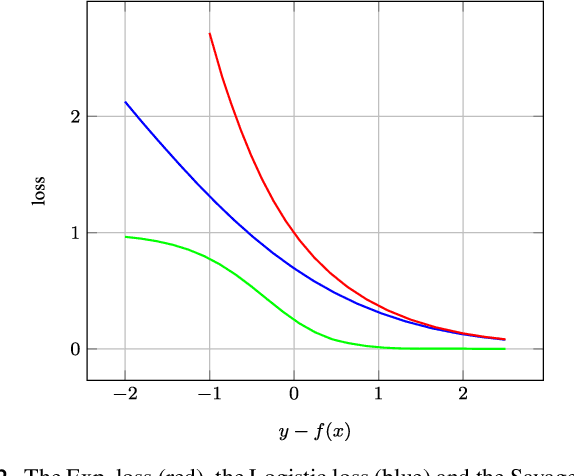

Ensemble techniques are powerful approaches that combine several weak learners to build a stronger one. As a meta-learning framework, ensemble techniques can easily be applied to many machine learning methods. Inspired by ensemble techniques, in this paper we propose an ensemble loss functions applied to a simple regressor. We then propose a half-quadratic learning algorithm in order to find the parameter of the regressor and the optimal weights associated with each loss function. Moreover, we show that our proposed loss function is robust in noisy environments. For a particular class of loss functions, we show that our proposed ensemble loss function is Bayes consistent and robust. Experimental evaluations on several datasets demonstrate that our proposed ensemble loss function significantly improves the performance of a simple regressor in comparison with state-of-the-art methods.
Sentimental Content Analysis and Knowledge Extraction from News Articles
Aug 09, 2018
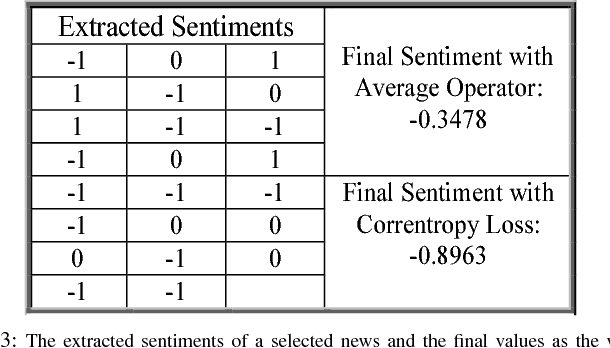

In web era, since technology has revolutionized mankind life, plenty of data and information are published on the Internet each day. For instance, news agencies publish news on their websites all over the world. These raw data could be an important resource for knowledge extraction. These shared data contain emotions (i.e., positive, neutral or negative) toward various topics; therefore, sentimental content extraction could be a beneficial task in many aspects. Extracting the sentiment of news illustrates highly valuable information about the events over a period of time, the viewpoint of a media or news agency to these events. In this paper an attempt is made to propose an approach for news analysis and extracting useful knowledge from them. Firstly, we attempt to extract a noise robust sentiment of news documents; therefore, the news associated to six countries: United State, United Kingdom, Germany, Canada, France and Australia in 5 different news categories: Politics, Sports, Business, Entertainment and Technology are downloaded. In this paper we compare the condition of different countries in each 5 news topics based on the extracted sentiments and emotional contents in news documents. Moreover, we propose an approach to reduce the bulky news data to extract the hottest topics and news titles as a knowledge. Eventually, we generate a word model to map each word to a fixed-size vector by Word2Vec in order to understand the relations between words in our collected news database.
Fuzzy Constraints Linear Discriminant Analysis
Dec 30, 2016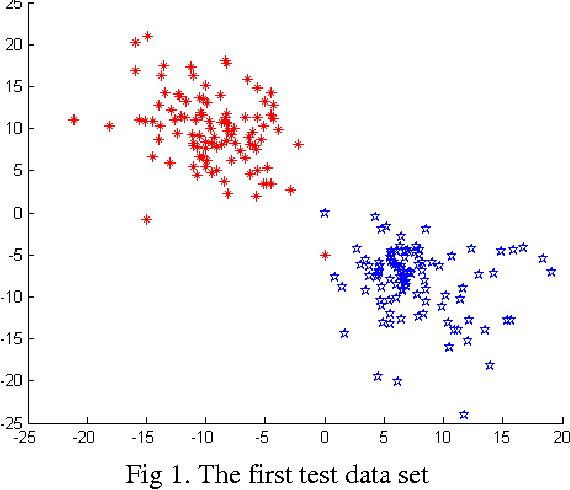
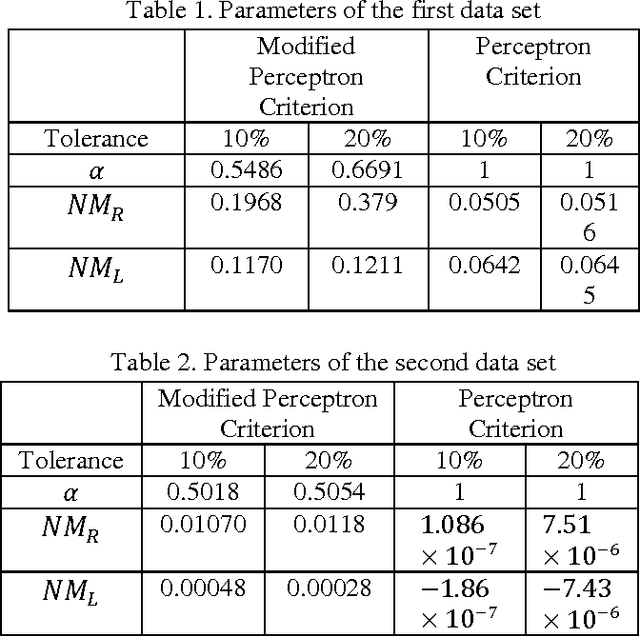
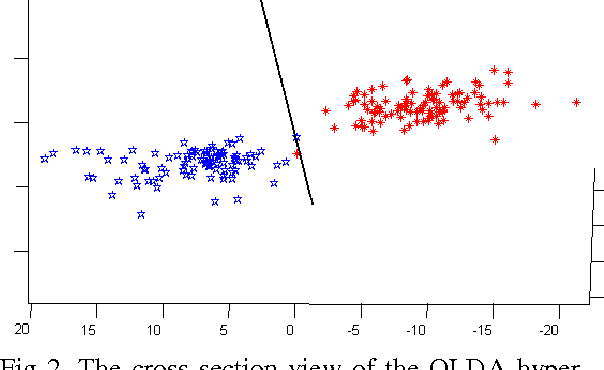
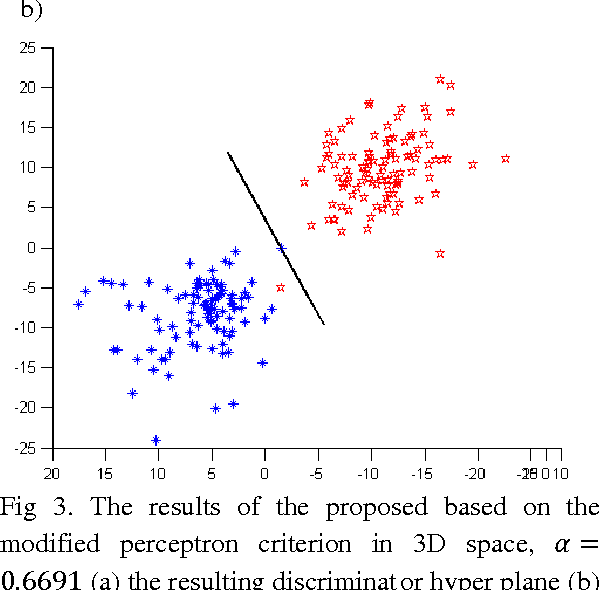
In this paper we introduce a fuzzy constraint linear discriminant analysis (FC-LDA). The FC-LDA tries to minimize misclassification error based on modified perceptron criterion that benefits handling the uncertainty near the decision boundary by means of a fuzzy linear programming approach with fuzzy resources. The method proposed has low computational complexity because of its linear characteristics and the ability to deal with noisy data with different degrees of tolerance. Obtained results verify the success of the algorithm when dealing with different problems. Comparing FC-LDA and LDA shows superiority in classification task.
Active Robust Learning
Aug 25, 2016In many practical applications of learning algorithms, unlabeled data is cheap and abundant whereas labeled data is expensive. Active learning algorithms developed to achieve better performance with lower cost. Usually Representativeness and Informativeness are used in active learning algoirthms. Advanced recent active learning methods consider both of these criteria. Despite its vast literature, very few active learning methods consider noisy instances, i.e. label noisy and outlier instances. Also, these methods didn't consider accuracy in computing representativeness and informativeness. Based on the idea that inaccuracy in these measures and not taking noisy instances into consideration are two sides of a coin and are inherently related, a new loss function is proposed. This new loss function helps to decrease the effect of noisy instances while at the same time, reduces bias. We defined "instance complexity" as a new notion of complexity for instances of a learning problem. It is proved that noisy instances in the data if any, are the ones with maximum instance complexity. Based on this loss function which has two functions for classifying ordinary and noisy instances, a new classifier, named "Simple-Complex Classifier" is proposed. In this classifier there are a simple and a complex function, with the complex function responsible for selecting noisy instances. The resulting optimization problem for both learning and active learning is highly non-convex and very challenging. In order to solve it, a convex relaxation is proposed.
Outlier absorbing based on a Bayesian approach
Jul 02, 2016



The presence of outliers is prevalent in machine learning applications and may produce misleading results. In this paper a new method for dealing with outliers and anomal samples is proposed. To overcome the outlier issue, the proposed method combines the global and local views of the samples. By combination of these views, our algorithm performs in a robust manner. The experimental results show the capabilities of the proposed method.
Comment on "robustness and regularization of support vector machines" by H. Xu, et al., (Journal of Machine Learning Research, vol. 10, pp. 1485-1510, 2009, arXiv:0803.3490)
Aug 17, 2013This paper comments on the published work dealing with robustness and regularization of support vector machines (Journal of Machine Learning Research, vol. 10, pp. 1485-1510, 2009) [arXiv:0803.3490] by H. Xu, etc. They proposed a theorem to show that it is possible to relate robustness in the feature space and robustness in the sample space directly. In this paper, we propose a counter example that rejects their theorem.
Designing Kernel Scheme for Classifiers Fusion
Dec 05, 2009



In this paper, we propose a special fusion method for combining ensembles of base classifiers utilizing new neural networks in order to improve overall efficiency of classification. While ensembles are designed such that each classifier is trained independently while the decision fusion is performed as a final procedure, in this method, we would be interested in making the fusion process more adaptive and efficient. This new combiner, called Neural Network Kernel Least Mean Square1, attempts to fuse outputs of the ensembles of classifiers. The proposed Neural Network has some special properties such as Kernel abilities,Least Mean Square features, easy learning over variants of patterns and traditional neuron capabilities. Neural Network Kernel Least Mean Square is a special neuron which is trained with Kernel Least Mean Square properties. This new neuron is used as a classifiers combiner to fuse outputs of base neural network classifiers. Performance of this method is analyzed and compared with other fusion methods. The analysis represents higher performance of our new method as opposed to others.
* 7 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS November 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/