 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentimental Content Analysis and Knowledge Extraction from News Articles
Paper and Code
Aug 09, 2018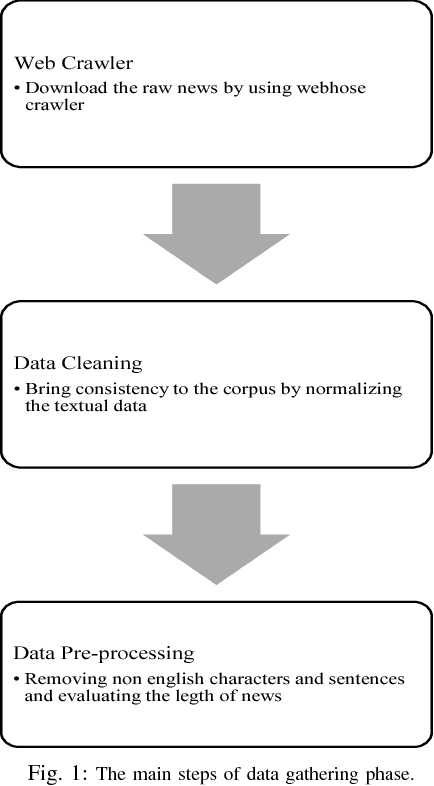
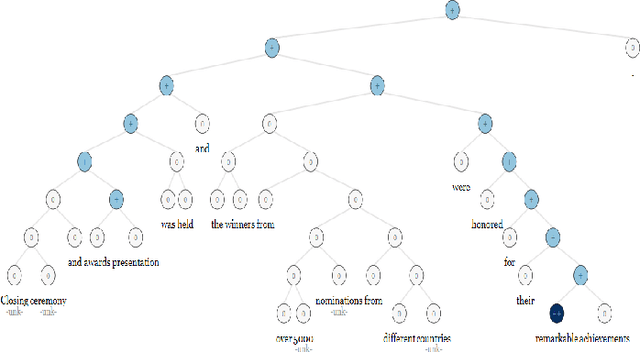
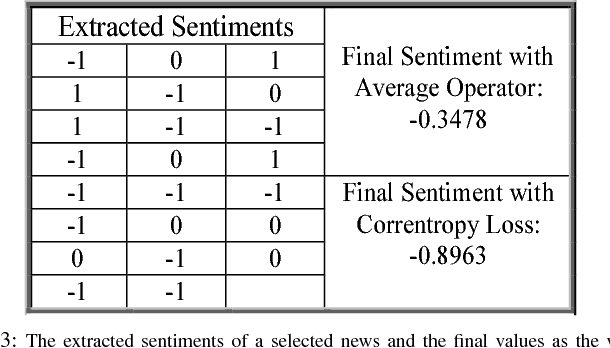

In web era, since technology has revolutionized mankind life, plenty of data and information are published on the Internet each day. For instance, news agencies publish news on their websites all over the world. These raw data could be an important resource for knowledge extraction. These shared data contain emotions (i.e., positive, neutral or negative) toward various topics; therefore, sentimental content extraction could be a beneficial task in many aspects. Extracting the sentiment of news illustrates highly valuable information about the events over a period of time, the viewpoint of a media or news agency to these events. In this paper an attempt is made to propose an approach for news analysis and extracting useful knowledge from them. Firstly, we attempt to extract a noise robust sentiment of news documents; therefore, the news associated to six countries: United State, United Kingdom, Germany, Canada, France and Australia in 5 different news categories: Politics, Sports, Business, Entertainment and Technology are downloaded. In this paper we compare the condition of different countries in each 5 news topics based on the extracted sentiments and emotional contents in news documents. Moreover, we propose an approach to reduce the bulky news data to extract the hottest topics and news titles as a knowledge. Eventually, we generate a word model to map each word to a fixed-size vector by Word2Vec in order to understand the relations between words in our collected news database.