 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Tuned Parameters on a LSA MCQ Answering Model
May 14, 2009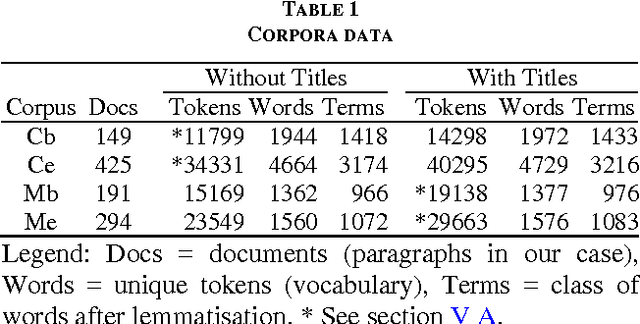
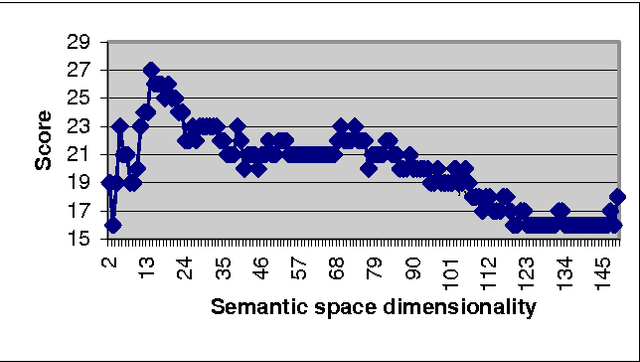
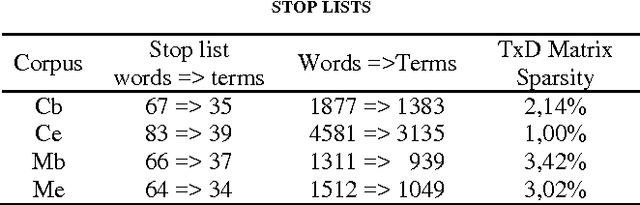
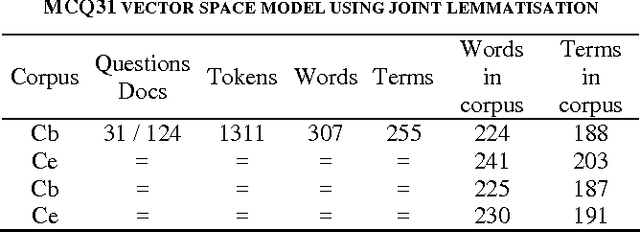
This paper presents the current state of a work in progress, whose objective is to better understand the effects of factors that significantly influence the performance of Latent Semantic Analysis (LSA). A difficult task, which consists in answering (French) biology Multiple Choice Questions, is used to test the semantic properties of the truncated singular space and to study the relative influence of main parameters. A dedicated software has been designed to fine tune the LSA semantic space for the Multiple Choice Questions task. With optimal parameters, the performances of our simple model are quite surprisingly equal or superior to those of 7th and 8th grades students. This indicates that semantic spaces were quite good despite their low dimensions and the small sizes of training data sets. Besides, we present an original entropy global weighting of answers' terms of each question of the Multiple Choice Questions which was necessary to achieve the model's success.
* 9 pages
A semantic space for modeling children's semantic memory
May 28, 2008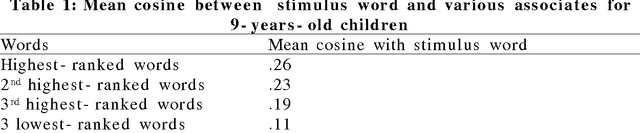
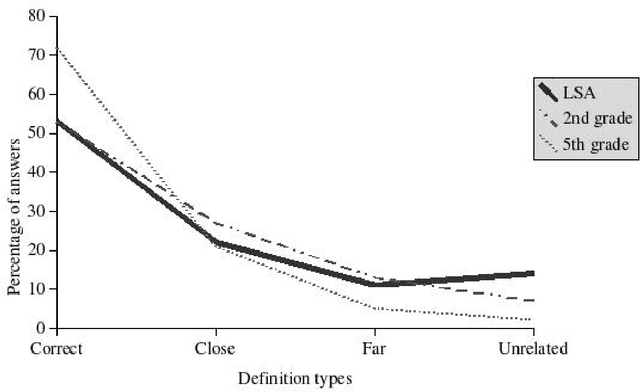
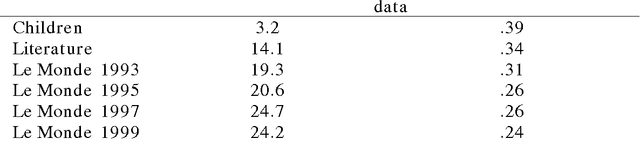
The goal of this paper is to present a model of children's semantic memory, which is based on a corpus reproducing the kinds of texts children are exposed to. After presenting the literature in the development of the semantic memory, a preliminary French corpus of 3.2 million words is described. Similarities in the resulting semantic space are compared to human data on four tests: association norms, vocabulary test, semantic judgments and memory tasks. A second corpus is described, which is composed of subcorpora corresponding to various ages. This stratified corpus is intended as a basis for developmental studies. Finally, two applications of these models of semantic memory are presented: the first one aims at tracing the development of semantic similarities paragraph by paragraph; the second one describes an implementation of a model of text comprehension derived from the Construction-integration model (Kintsch, 1988, 1998) and based on such models of semantic memory.
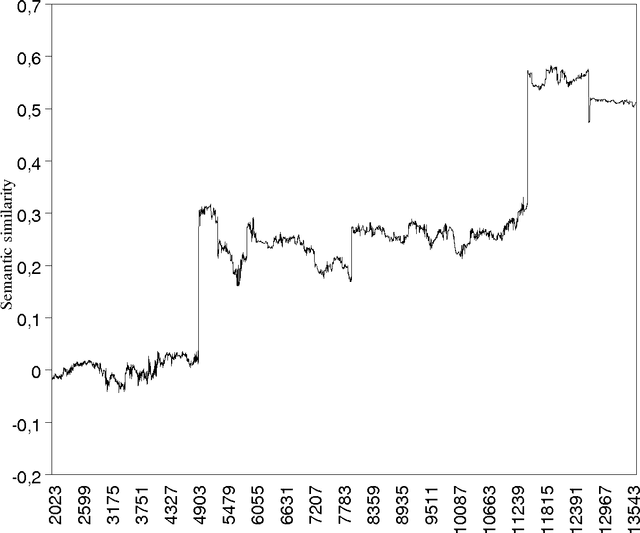
Effects of High-Order Co-occurrences on Word Semantic Similarities
Apr 01, 2008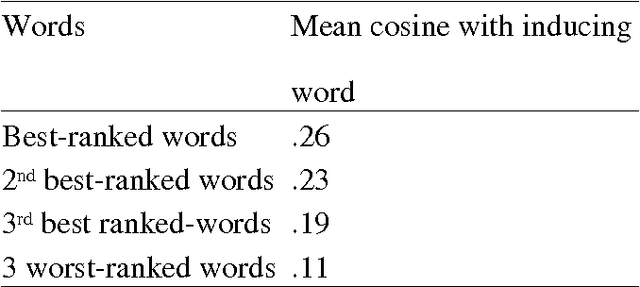
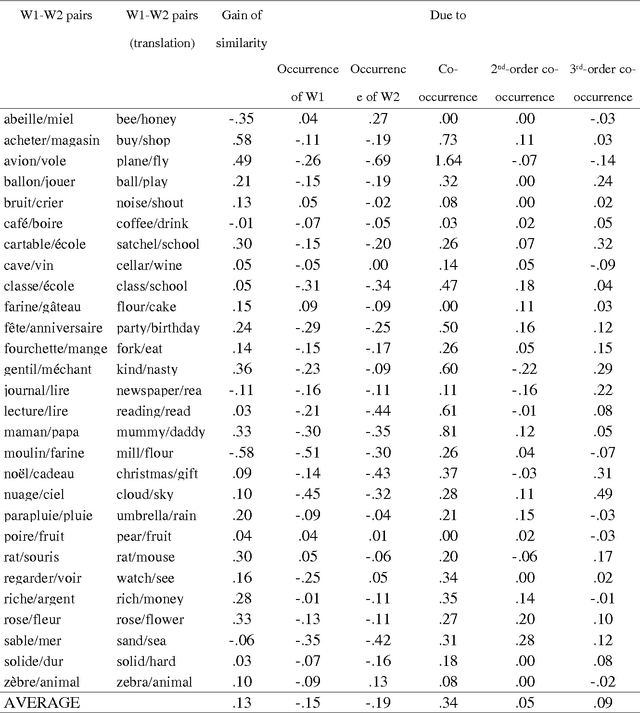
A computational model of the construction of word meaning through exposure to texts is built in order to simulate the effects of co-occurrence values on word semantic similarities, paragraph by paragraph. Semantic similarity is here viewed as association. It turns out that the similarity between two words W1 and W2 strongly increases with a co-occurrence, decreases with the occurrence of W1 without W2 or W2 without W1, and slightly increases with high-order co-occurrences. Therefore, operationalizing similarity as a frequency of co-occurrence probably introduces a bias: first, there are cases in which there is similarity without co-occurrence and, second, the frequency of co-occurrence overestimates similarity.