 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Tuned Parameters on a LSA MCQ Answering Model
May 14, 2009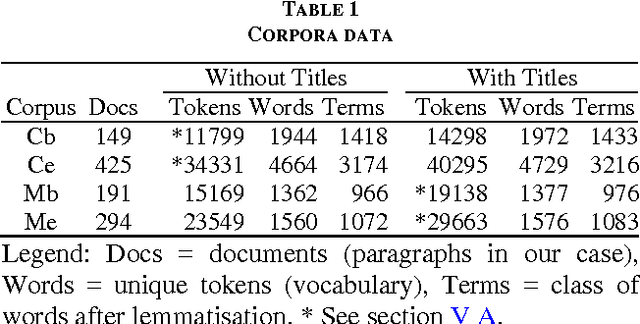
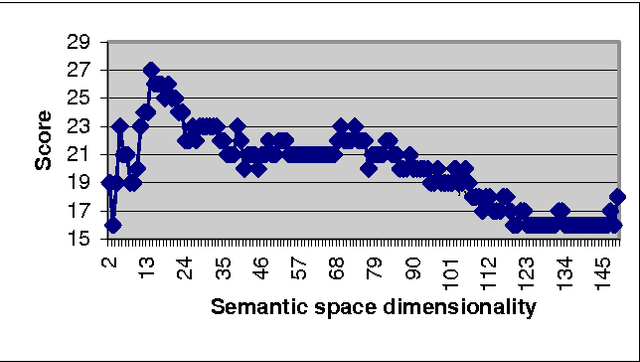
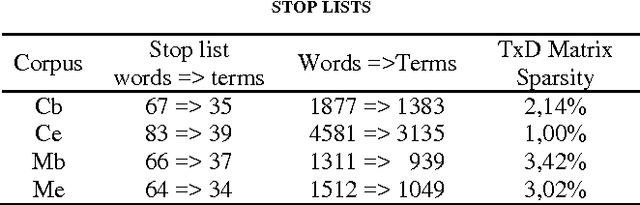
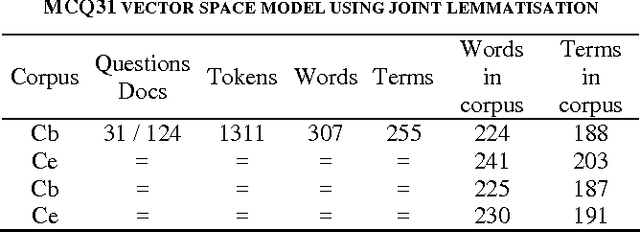
This paper presents the current state of a work in progress, whose objective is to better understand the effects of factors that significantly influence the performance of Latent Semantic Analysis (LSA). A difficult task, which consists in answering (French) biology Multiple Choice Questions, is used to test the semantic properties of the truncated singular space and to study the relative influence of main parameters. A dedicated software has been designed to fine tune the LSA semantic space for the Multiple Choice Questions task. With optimal parameters, the performances of our simple model are quite surprisingly equal or superior to those of 7th and 8th grades students. This indicates that semantic spaces were quite good despite their low dimensions and the small sizes of training data sets. Besides, we present an original entropy global weighting of answers' terms of each question of the Multiple Choice Questions which was necessary to achieve the model's success.
* 9 pages
Fast Lexically Constrained Viterbi Algorithm (FLCVA): Simultaneous Optimization of Speed and Memory
Mar 19, 2006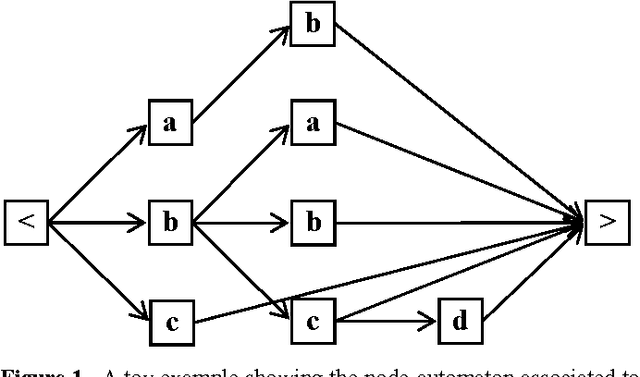
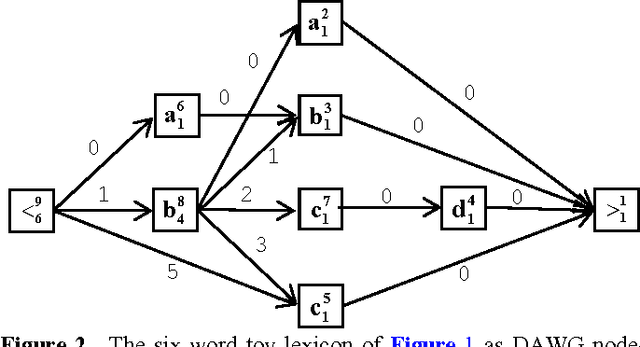
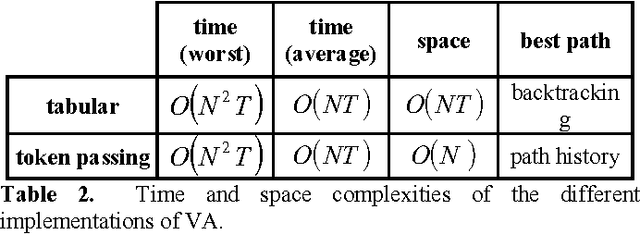
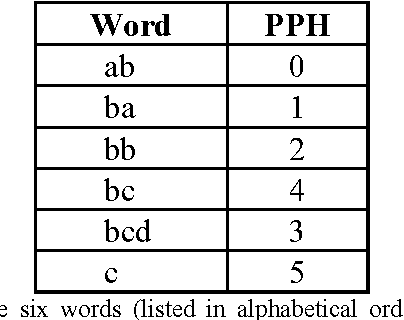
Lexical constraints on the input of speech and on-line handwriting systems improve the performance of such systems. A significant gain in speed can be achieved by integrating in a digraph structure the different Hidden Markov Models (HMM) corresponding to the words of the relevant lexicon. This integration avoids redundant computations by sharing intermediate results between HMM's corresponding to different words of the lexicon. In this paper, we introduce a token passing method to perform simultaneously the computation of the a posteriori probabilities of all the words of the lexicon. The coding scheme that we introduce for the tokens is optimal in the information theory sense. The tokens use the minimum possible number of bits. Overall, we optimize simultaneously the execution speed and the memory requirement of the recognition systems.