 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Lexically Constrained Viterbi Algorithm (FLCVA): Simultaneous Optimization of Speed and Memory
Paper and Code
Mar 19, 2006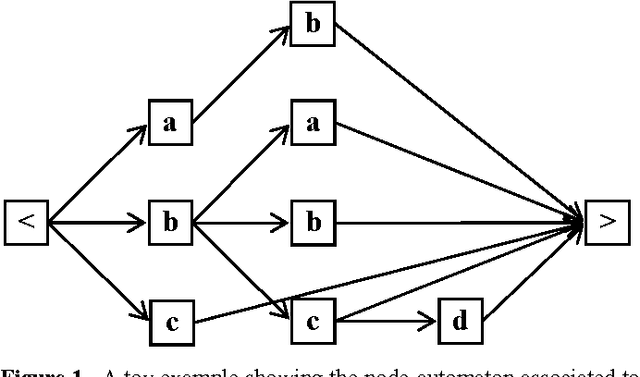
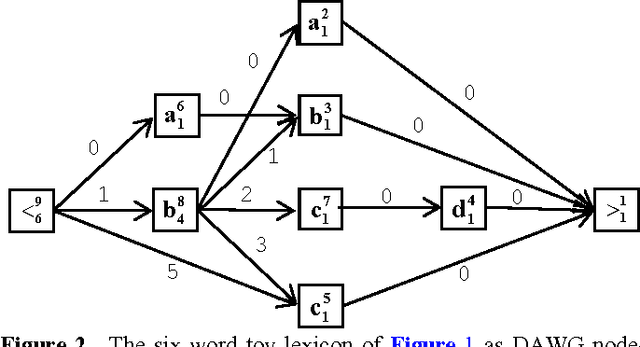
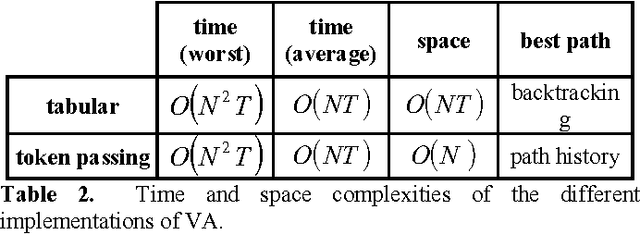
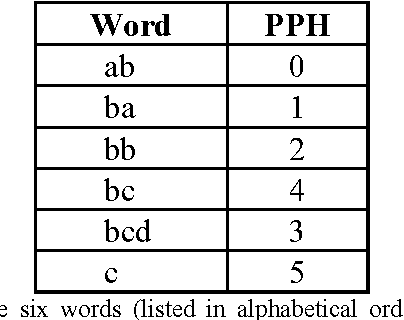
Lexical constraints on the input of speech and on-line handwriting systems improve the performance of such systems. A significant gain in speed can be achieved by integrating in a digraph structure the different Hidden Markov Models (HMM) corresponding to the words of the relevant lexicon. This integration avoids redundant computations by sharing intermediate results between HMM's corresponding to different words of the lexicon. In this paper, we introduce a token passing method to perform simultaneously the computation of the a posteriori probabilities of all the words of the lexicon. The coding scheme that we introduce for the tokens is optimal in the information theory sense. The tokens use the minimum possible number of bits. Overall, we optimize simultaneously the execution speed and the memory requirement of the recognition systems.