Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of High-Order Co-occurrences on Word Semantic Similarities
Paper and Code
Apr 01, 2008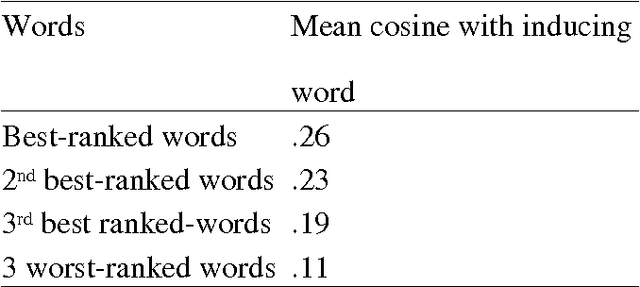
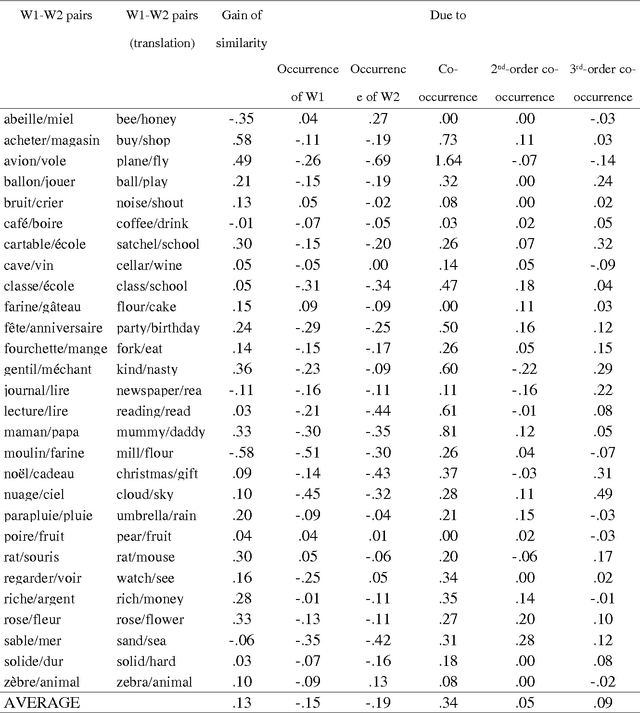
A computational model of the construction of word meaning through exposure to texts is built in order to simulate the effects of co-occurrence values on word semantic similarities, paragraph by paragraph. Semantic similarity is here viewed as association. It turns out that the similarity between two words W1 and W2 strongly increases with a co-occurrence, decreases with the occurrence of W1 without W2 or W2 without W1, and slightly increases with high-order co-occurrences. Therefore, operationalizing similarity as a frequency of co-occurrence probably introduces a bias: first, there are cases in which there is similarity without co-occurrence and, second, the frequency of co-occurrence overestimates similarity.
* Current Psychology Letters - Behaviour, Brain and Cognition 18, 1
(2006) 1
View paper on