 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInduction of High-level Behaviors from Problem-solving Traces using Machine Learning Tools
Apr 05, 2009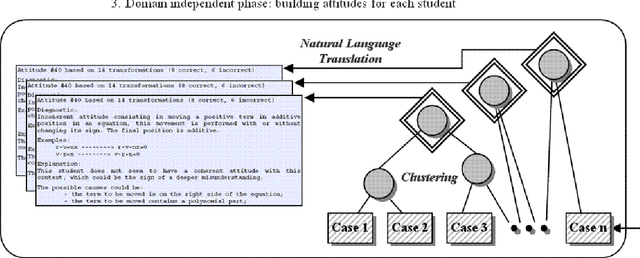
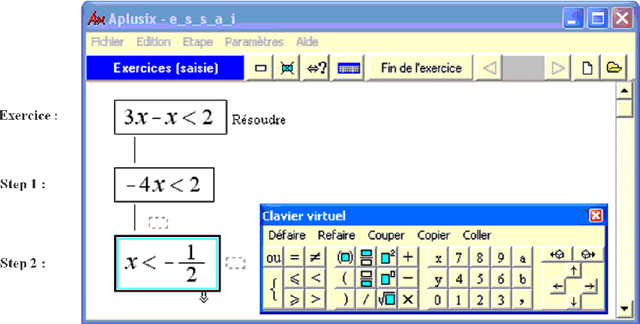
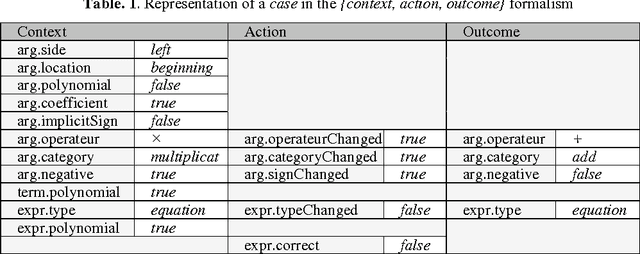
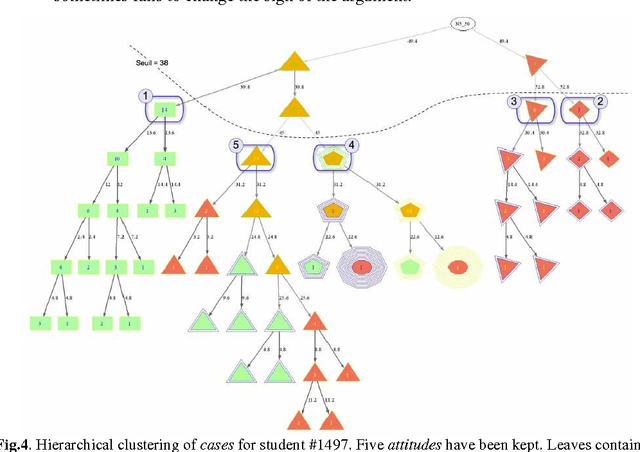
This paper applies machine learning techniques to student modeling. It presents a method for discovering high-level student behaviors from a very large set of low-level traces corresponding to problem-solving actions in a learning environment. Basic actions are encoded into sets of domain-dependent attribute-value patterns called cases. Then a domain-independent hierarchical clustering identifies what we call general attitudes, yielding automatic diagnosis expressed in natural language, addressed in principle to teachers. The method can be applied to individual students or to entire groups, like a class. We exhibit examples of this system applied to thousands of students' actions in the domain of algebraic transformations.
A semantic space for modeling children's semantic memory
May 28, 2008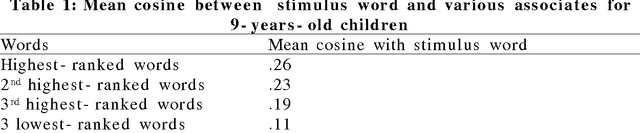
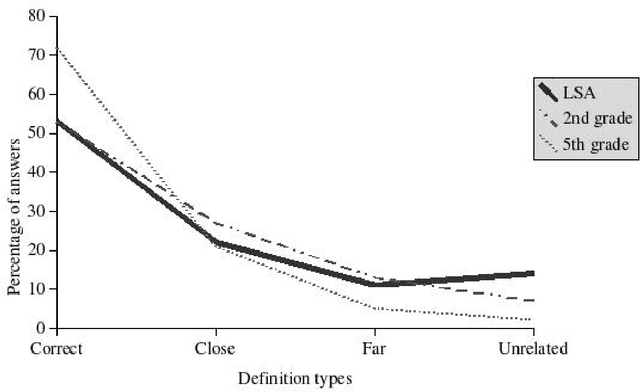
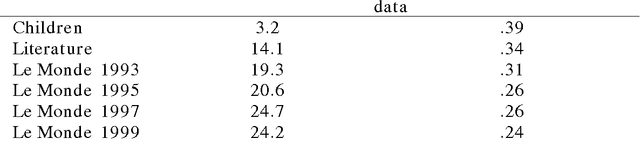
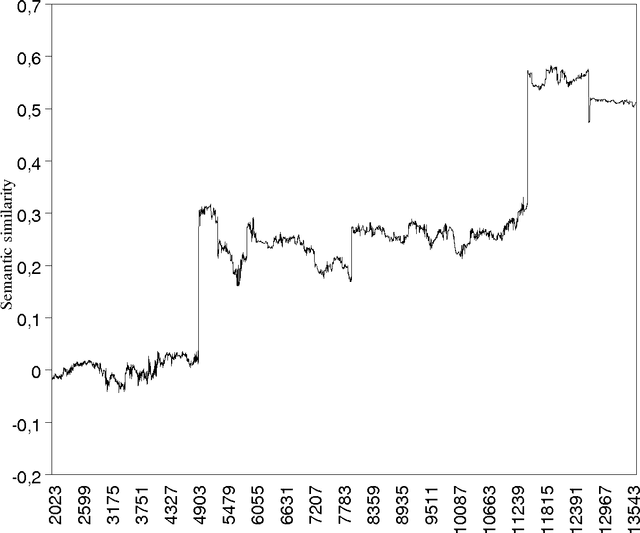
The goal of this paper is to present a model of children's semantic memory, which is based on a corpus reproducing the kinds of texts children are exposed to. After presenting the literature in the development of the semantic memory, a preliminary French corpus of 3.2 million words is described. Similarities in the resulting semantic space are compared to human data on four tests: association norms, vocabulary test, semantic judgments and memory tasks. A second corpus is described, which is composed of subcorpora corresponding to various ages. This stratified corpus is intended as a basis for developmental studies. Finally, two applications of these models of semantic memory are presented: the first one aims at tracing the development of semantic similarities paragraph by paragraph; the second one describes an implementation of a model of text comprehension derived from the Construction-integration model (Kintsch, 1988, 1998) and based on such models of semantic memory.
Effects of High-Order Co-occurrences on Word Semantic Similarities
Apr 01, 2008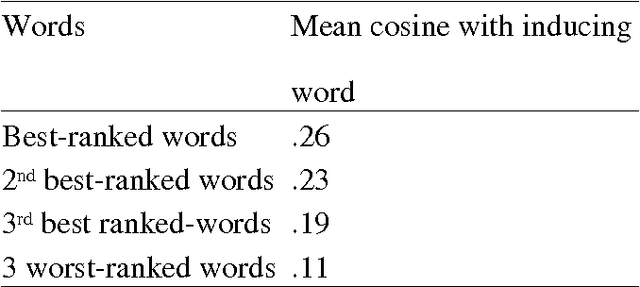
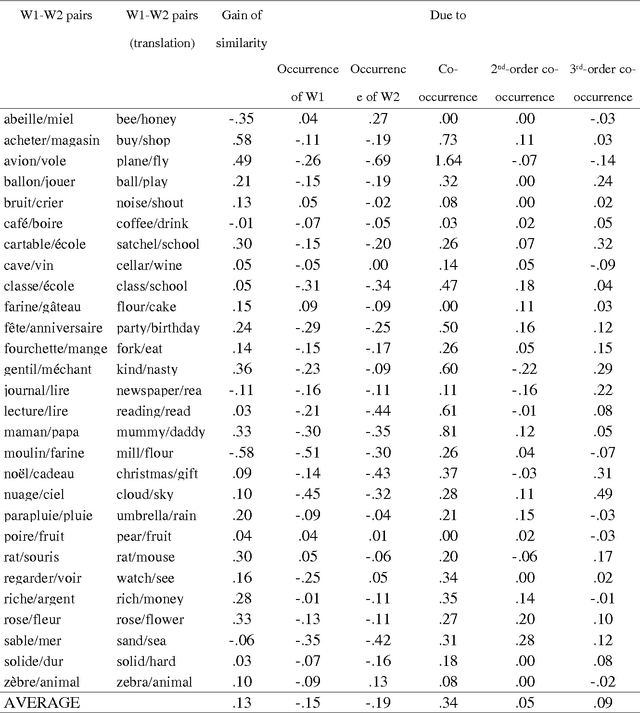
A computational model of the construction of word meaning through exposure to texts is built in order to simulate the effects of co-occurrence values on word semantic similarities, paragraph by paragraph. Semantic similarity is here viewed as association. It turns out that the similarity between two words W1 and W2 strongly increases with a co-occurrence, decreases with the occurrence of W1 without W2 or W2 without W1, and slightly increases with high-order co-occurrences. Therefore, operationalizing similarity as a frequency of co-occurrence probably introduces a bias: first, there are cases in which there is similarity without co-occurrence and, second, the frequency of co-occurrence overestimates similarity.