 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA semantic space for modeling children's semantic memory
May 28, 2008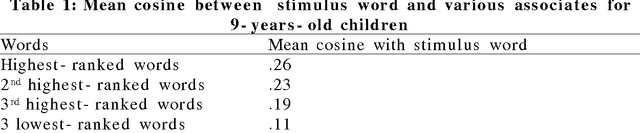
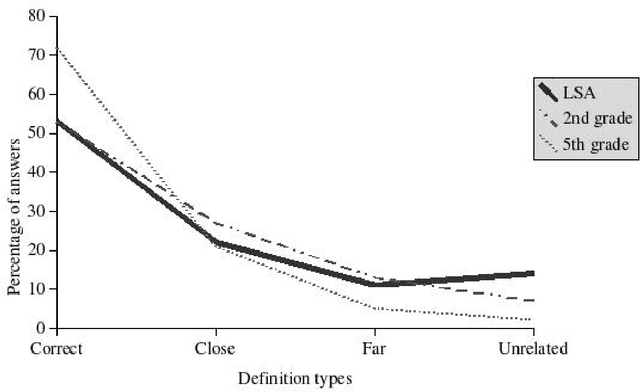
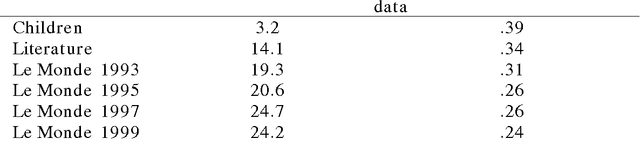
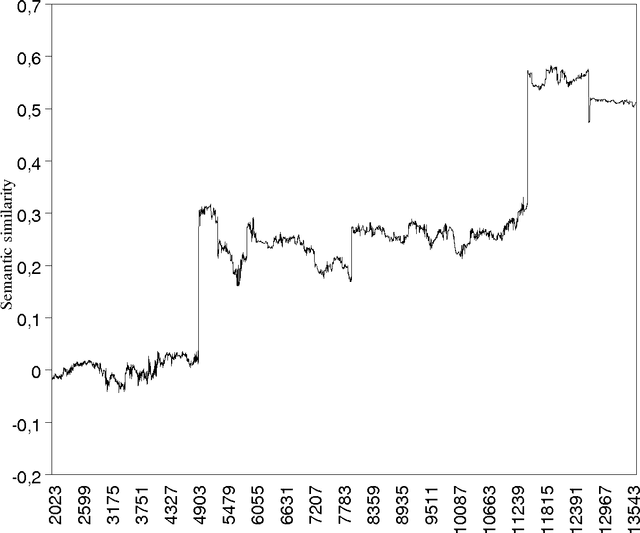
The goal of this paper is to present a model of children's semantic memory, which is based on a corpus reproducing the kinds of texts children are exposed to. After presenting the literature in the development of the semantic memory, a preliminary French corpus of 3.2 million words is described. Similarities in the resulting semantic space are compared to human data on four tests: association norms, vocabulary test, semantic judgments and memory tasks. A second corpus is described, which is composed of subcorpora corresponding to various ages. This stratified corpus is intended as a basis for developmental studies. Finally, two applications of these models of semantic memory are presented: the first one aims at tracing the development of semantic similarities paragraph by paragraph; the second one describes an implementation of a model of text comprehension derived from the Construction-integration model (Kintsch, 1988, 1998) and based on such models of semantic memory.