 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning quantitative sequence-function relationships from massively parallel experiments
Sep 22, 2015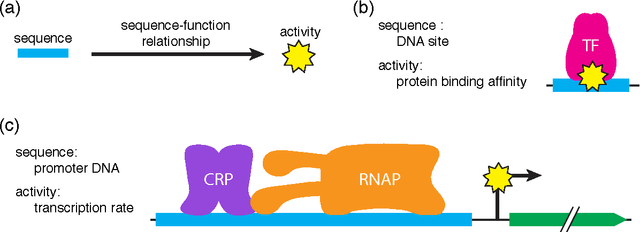
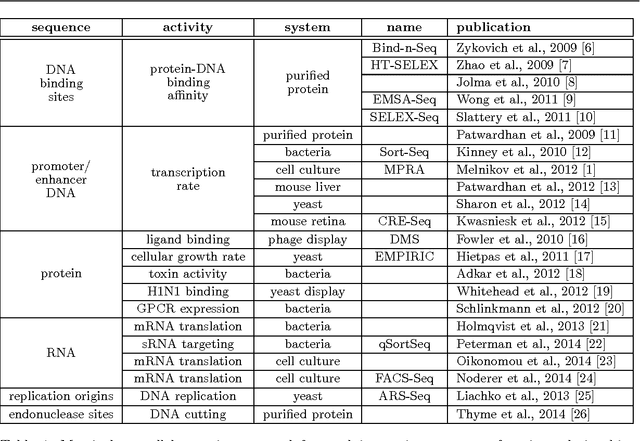
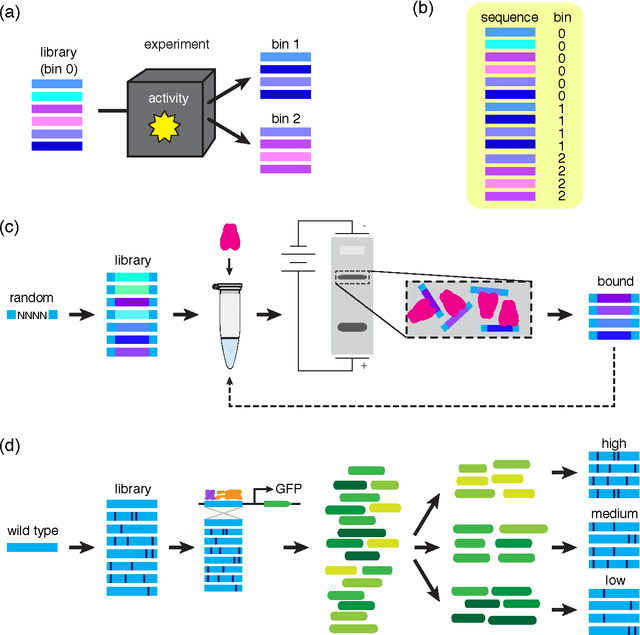
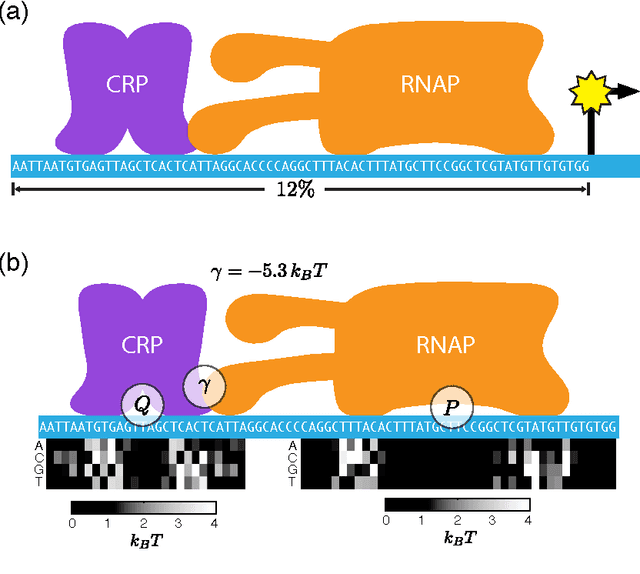
A fundamental aspect of biological information processing is the ubiquity of sequence-function relationships -- functions that map the sequence of DNA, RNA, or protein to a biochemically relevant activity. Most sequence-function relationships in biology are quantitative, but only recently have experimental techniques for effectively measuring these relationships been developed. The advent of such "massively parallel" experiments presents an exciting opportunity for the concepts and methods of statistical physics to inform the study of biological systems. After reviewing these recent experimental advances, we focus on the problem of how to infer parametric models of sequence-function relationships from the data produced by these experiments. Specifically, we retrace and extend recent theoretical work showing that inference based on mutual information, not the standard likelihood-based approach, is often necessary for accurately learning the parameters of these models. Closely connected with this result is the emergence of "diffeomorphic modes" -- directions in parameter space that are far less constrained by data than likelihood-based inference would suggest. Analogous to Goldstone modes in physics, diffeomorphic modes arise from an arbitrarily broken symmetry of the inference problem. An analytically tractable model of a massively parallel experiment is then described, providing an explicit demonstration of these fundamental aspects of statistical inference. This paper concludes with an outlook on the theoretical and computational challenges currently facing studies of quantitative sequence-function relationships.
Equitability, mutual information, and the maximal information coefficient
Jan 31, 2013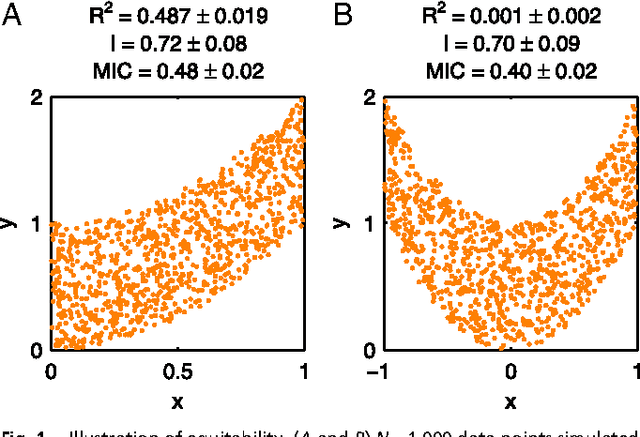
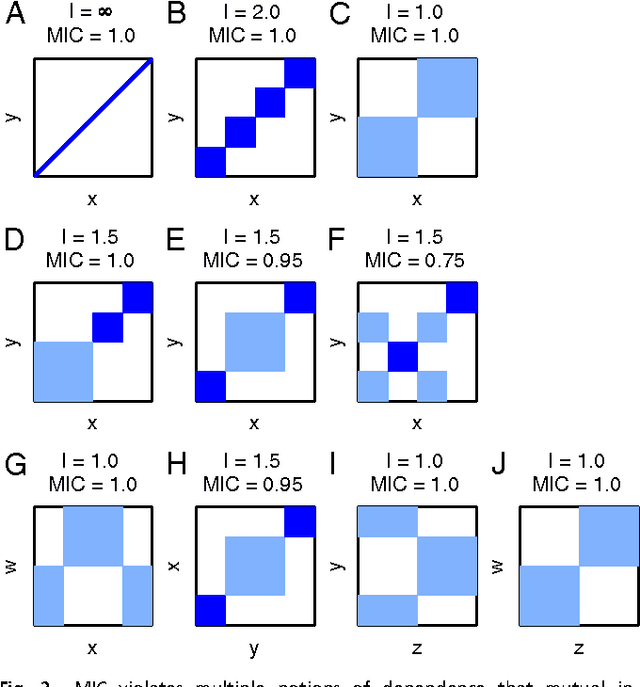
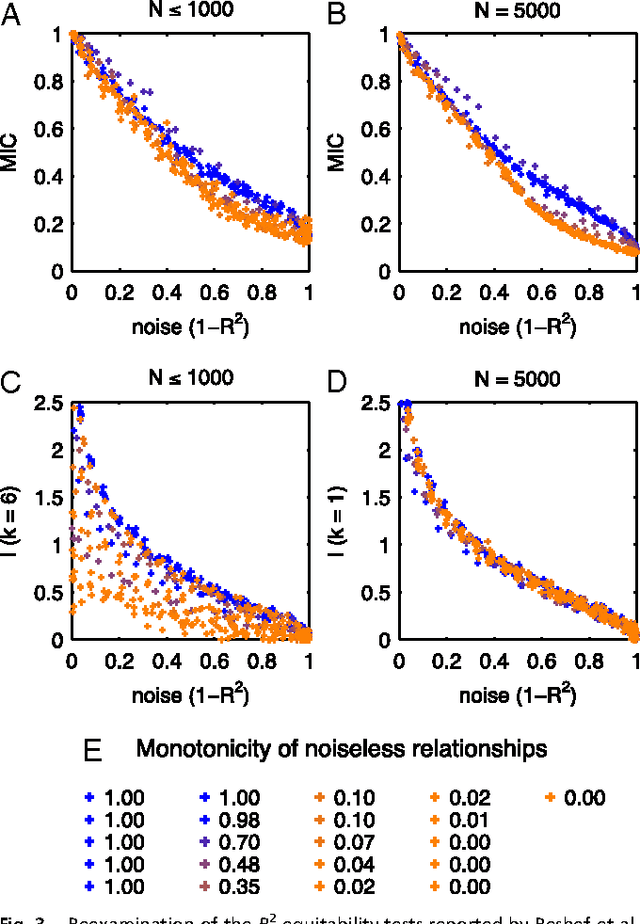
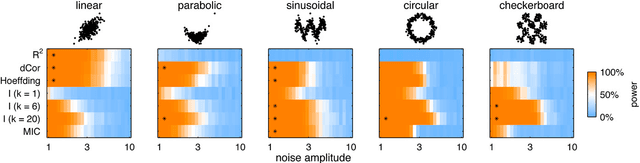
Reshef et al. recently proposed a new statistical measure, the "maximal information coefficient" (MIC), for quantifying arbitrary dependencies between pairs of stochastic quantities. MIC is based on mutual information, a fundamental quantity in information theory that is widely understood to serve this need. MIC, however, is not an estimate of mutual information. Indeed, it was claimed that MIC possesses a desirable mathematical property called "equitability" that mutual information lacks. This was not proven; instead it was argued solely through the analysis of simulated data. Here we show that this claim, in fact, is incorrect. First we offer mathematical proof that no (non-trivial) dependence measure satisfies the definition of equitability proposed by Reshef et al.. We then propose a self-consistent and more general definition of equitability that follows naturally from the Data Processing Inequality. Mutual information satisfies this new definition of equitability while MIC does not. Finally, we show that the simulation evidence offered by Reshef et al. was artifactual. We conclude that estimating mutual information is not only practical for many real-world applications, but also provides a natural solution to the problem of quantifying associations in large data sets.
Estimating mutual information and multi--information in large networks
Feb 03, 2005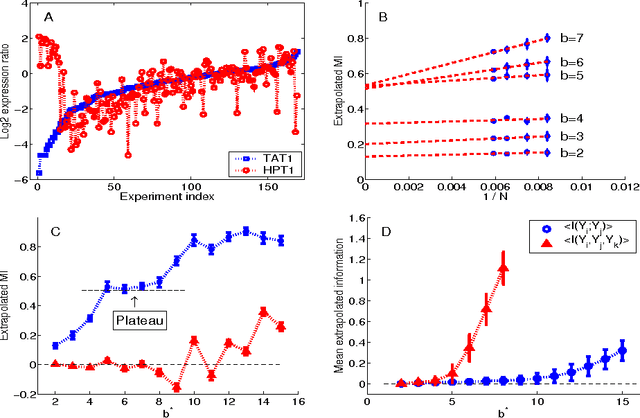


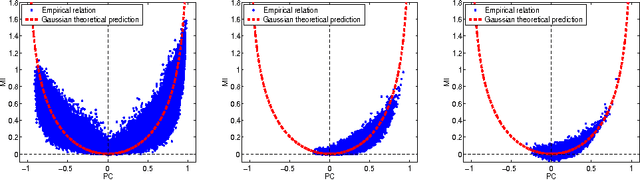
We address the practical problems of estimating the information relations that characterize large networks. Building on methods developed for analysis of the neural code, we show that reliable estimates of mutual information can be obtained with manageable computational effort. The same methods allow estimation of higher order, multi--information terms. These ideas are illustrated by analyses of gene expression, financial markets, and consumer preferences. In each case, information theoretic measures correlate with independent, intuitive measures of the underlying structures in the system.