 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinematic-aware Hierarchical Attention Network for Human Pose Estimation in Videos
Nov 29, 2022



Previous video-based human pose estimation methods have shown promising results by leveraging aggregated features of consecutive frames. However, most approaches compromise accuracy to mitigate jitter or do not sufficiently comprehend the temporal aspects of human motion. Furthermore, occlusion increases uncertainty between consecutive frames, which results in unsmooth results. To address these issues, we design an architecture that exploits the keypoint kinematic features with the following components. First, we effectively capture the temporal features by leveraging individual keypoint's velocity and acceleration. Second, the proposed hierarchical transformer encoder aggregates spatio-temporal dependencies and refines the 2D or 3D input pose estimated from existing estimators. Finally, we provide an online cross-supervision between the refined input pose generated from the encoder and the final pose from our decoder to enable joint optimization. We demonstrate comprehensive results and validate the effectiveness of our model in various tasks: 2D pose estimation, 3D pose estimation, body mesh recovery, and sparsely annotated multi-human pose estimation. Our code is available at https://github.com/KyungMinJin/HANet.
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos
Jul 28, 2022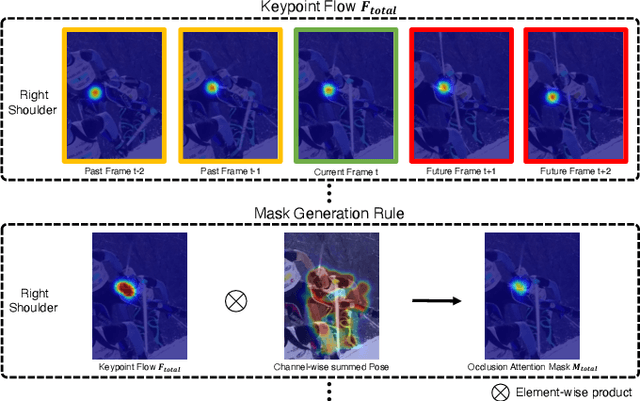
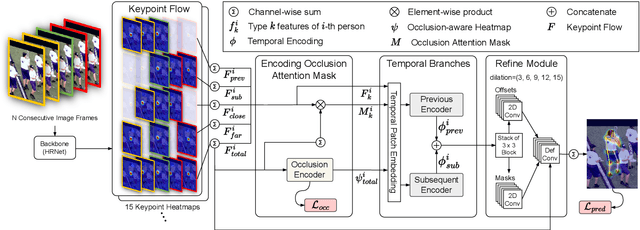
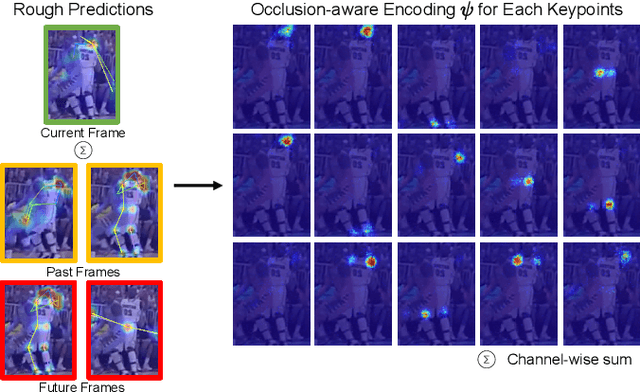
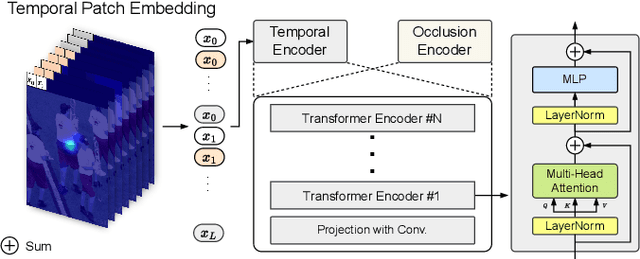
Although many approaches for multi-human pose estimation in videos have shown profound results, they require densely annotated data which entails excessive man labor. Furthermore, there exists occlusion and motion blur that inevitably lead to poor estimation performance. To address these problems, we propose a method that leverages an attention mask for occluded joints and encodes temporal dependency between frames using transformers. First, our framework composes different combinations of sparsely annotated frames that denote the track of the overall joint movement. We propose an occlusion attention mask from these combinations that enable encoding occlusion-aware heatmaps as a semi-supervised task. Second, the proposed temporal encoder employs transformer architecture to effectively aggregate the temporal relationship and keypoint-wise attention from each time step and accurately refines the target frame's final pose estimation. We achieve state-of-the-art pose estimation results for PoseTrack2017 and PoseTrack2018 datasets and demonstrate the robustness of our approach to occlusion and motion blur in sparsely annotated video data.
HTNet: Anchor-free Temporal Action Localization with Hierarchical Transformers
Jul 21, 2022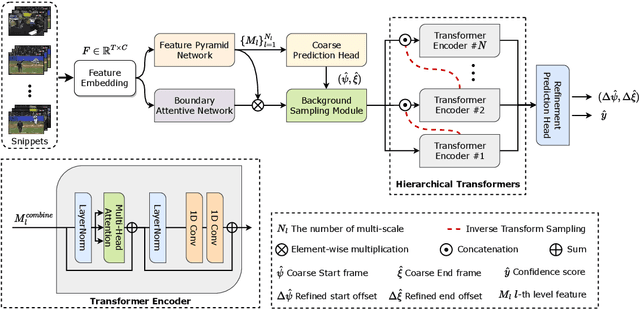
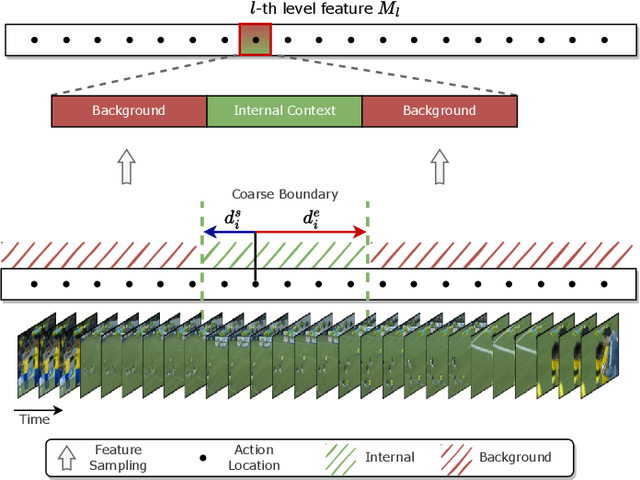
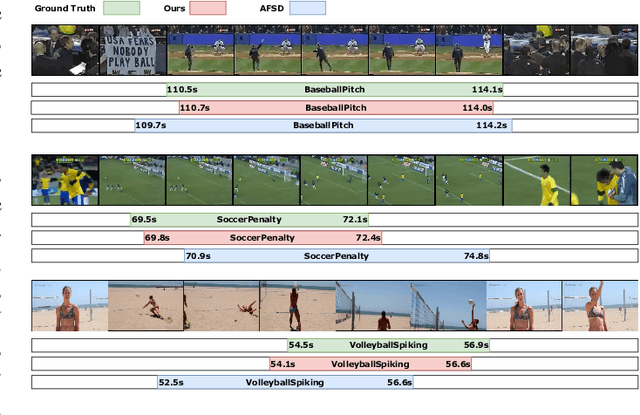
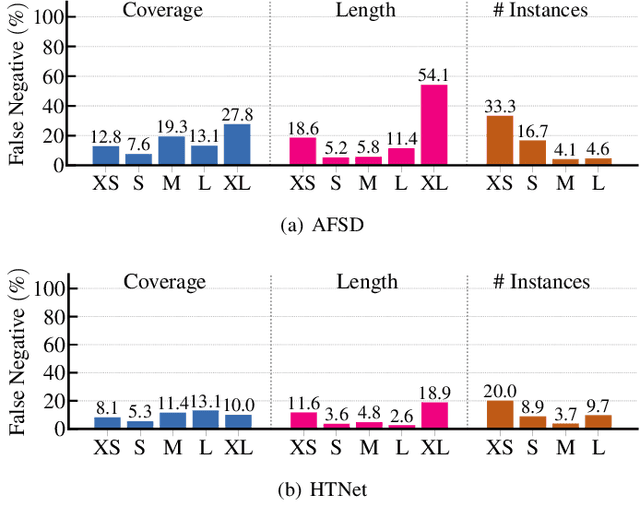
Temporal action localization (TAL) is a task of identifying a set of actions in a video, which involves localizing the start and end frames and classifying each action instance. Existing methods have addressed this task by using predefined anchor windows or heuristic bottom-up boundary-matching strategies, which are major bottlenecks in inference time. Additionally, the main challenge is the inability to capture long-range actions due to a lack of global contextual information. In this paper, we present a novel anchor-free framework, referred to as HTNet, which predicts a set of <start time, end time, class> triplets from a video based on a Transformer architecture. After the prediction of coarse boundaries, we refine it through a background feature sampling (BFS) module and hierarchical Transformers, which enables our model to aggregate global contextual information and effectively exploit the inherent semantic relationships in a video. We demonstrate how our method localizes accurate action instances and achieves state-of-the-art performance on two TAL benchmark datasets: THUMOS14 and ActivityNet 1.3.
Joint Dermatological Lesion Classification and Confidence Modeling with Uncertainty Estimation
Jul 19, 2021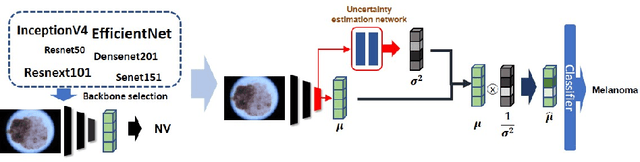
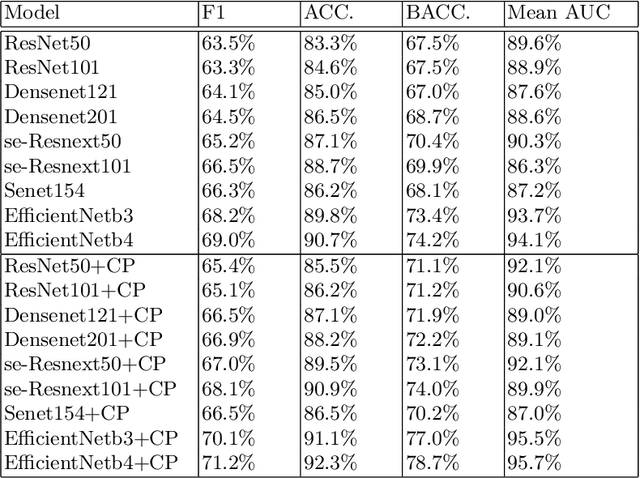
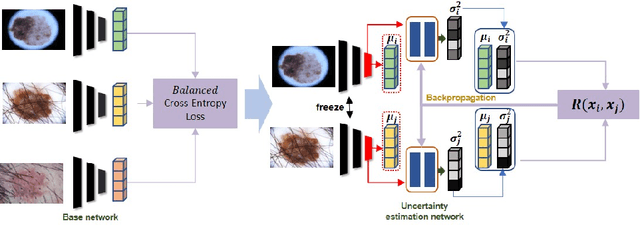
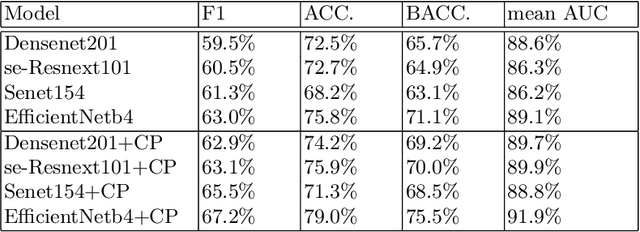
Deep learning has played a major role in the interpretation of dermoscopic images for detecting skin defects and abnormalities. However, current deep learning solutions for dermatological lesion analysis are typically limited in providing probabilistic predictions which highlights the importance of concerning uncertainties. This concept of uncertainty can provide a confidence level for each feature which prevents overconfident predictions with poor generalization on unseen data. In this paper, we propose an overall framework that jointly considers dermatological classification and uncertainty estimation together. The estimated confidence of each feature to avoid uncertain feature and undesirable shift, which are caused by environmental difference of input image, in the latent space is pooled from confidence network. Our qualitative results show that modeling uncertainties not only helps to quantify model confidence for each prediction but also helps classification layers to focus on confident features, therefore, improving the accuracy for dermatological lesion classification. We demonstrate the potential of the proposed approach in two state-of-the-art dermoscopic datasets (ISIC 2018 and ISIC 2019).
ACNet: Mask-Aware Attention with Dynamic Context Enhancement for Robust Acne Detection
May 31, 2021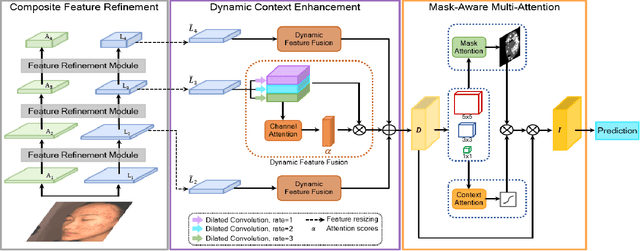
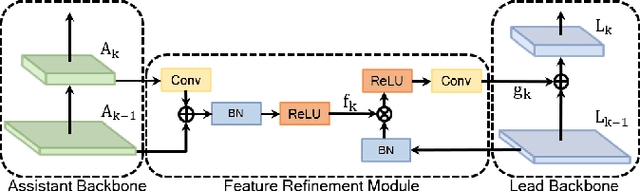
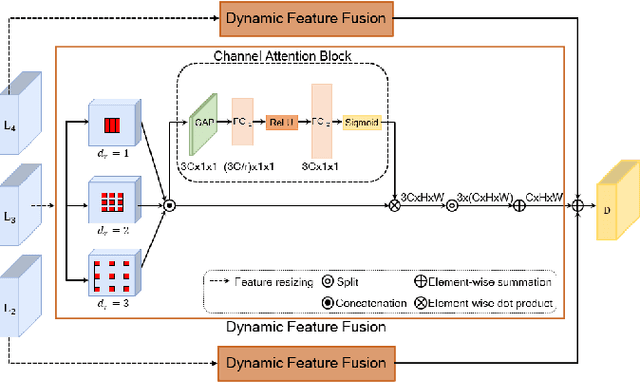
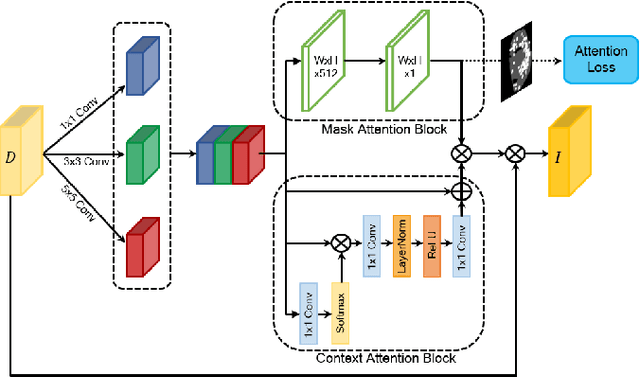
Computer-aided diagnosis has recently received attention for its advantage of low cost and time efficiency. Although deep learning played a major role in the recent success of acne detection, there are still several challenges such as color shift by inconsistent illumination, variation in scales, and high density distribution. To address these problems, we propose an acne detection network which consists of three components, specifically: Composite Feature Refinement, Dynamic Context Enhancement, and Mask-Aware Multi-Attention. First, Composite Feature Refinement integrates semantic information and fine details to enrich feature representation, which mitigates the adverse impact of imbalanced illumination. Then, Dynamic Context Enhancement controls different receptive fields of multi-scale features for context enhancement to handle scale variation. Finally, Mask-Aware Multi-Attention detects densely arranged and small acne by suppressing uninformative regions and highlighting probable acne regions. Experiments are performed on acne image dataset ACNE04 and natural image dataset PASCAL VOC 2007. We demonstrate how our method achieves the state-of-the-art result on ACNE04 and competitive performance with previous state-of-the-art methods on the PASCAL VOC 2007.