 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHTNet: Anchor-free Temporal Action Localization with Hierarchical Transformers
Paper and Code
Jul 21, 2022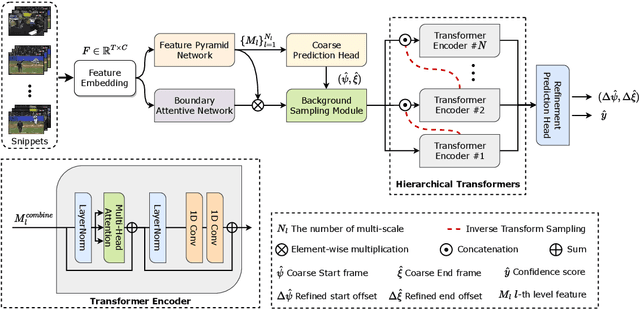
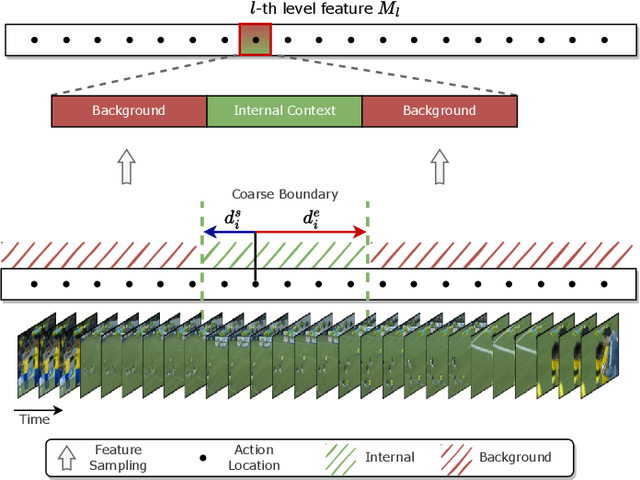
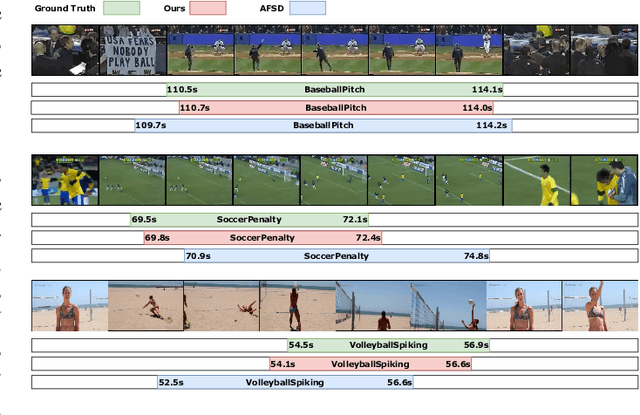
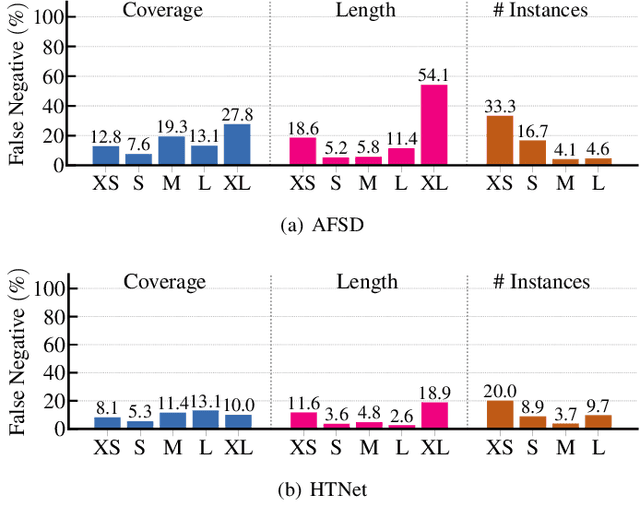
Temporal action localization (TAL) is a task of identifying a set of actions in a video, which involves localizing the start and end frames and classifying each action instance. Existing methods have addressed this task by using predefined anchor windows or heuristic bottom-up boundary-matching strategies, which are major bottlenecks in inference time. Additionally, the main challenge is the inability to capture long-range actions due to a lack of global contextual information. In this paper, we present a novel anchor-free framework, referred to as HTNet, which predicts a set of <start time, end time, class> triplets from a video based on a Transformer architecture. After the prediction of coarse boundaries, we refine it through a background feature sampling (BFS) module and hierarchical Transformers, which enables our model to aggregate global contextual information and effectively exploit the inherent semantic relationships in a video. We demonstrate how our method localizes accurate action instances and achieves state-of-the-art performance on two TAL benchmark datasets: THUMOS14 and ActivityNet 1.3.