 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Modality-Aware Post-training and Learning Ecosystem
Feb 12, 2026Multimodal language models now integrate text, audio, and video for unified reasoning. Yet existing RL post-training pipelines treat all input signals as equally relevant, ignoring which modalities each task actually requires. This modality-blind training inflates policy-gradient variance, slows convergence, and degrades robustness to real-world distribution shifts where signals may be missing, added, or reweighted. We introduce MAPLE, a complete modality-aware post-training and learning ecosystem comprising: (1) MAPLE-bench, the first benchmark explicitly annotating minimal signal combinations required per task; (2) MAPO, a modality-aware policy optimization framework that stratifies batches by modality requirement to reduce gradient variance from heterogeneous group advantages; (3) Adaptive weighting and curriculum scheduling that balances and prioritizes harder signal combinations. Systematic analysis across loss aggregation, clipping, sampling, and curriculum design establishes MAPO's optimal training strategy. Adaptive weighting and curriculum focused learning further boost performance across signal combinations. MAPLE narrows uni/multi-modal accuracy gaps by 30.24%, converges 3.18x faster, and maintains stability across all modality combinations under realistic reduced signal access. MAPLE constitutes a complete recipe for deployment-ready multimodal RL post-training.
Kinematic-aware Hierarchical Attention Network for Human Pose Estimation in Videos
Nov 29, 2022



Previous video-based human pose estimation methods have shown promising results by leveraging aggregated features of consecutive frames. However, most approaches compromise accuracy to mitigate jitter or do not sufficiently comprehend the temporal aspects of human motion. Furthermore, occlusion increases uncertainty between consecutive frames, which results in unsmooth results. To address these issues, we design an architecture that exploits the keypoint kinematic features with the following components. First, we effectively capture the temporal features by leveraging individual keypoint's velocity and acceleration. Second, the proposed hierarchical transformer encoder aggregates spatio-temporal dependencies and refines the 2D or 3D input pose estimated from existing estimators. Finally, we provide an online cross-supervision between the refined input pose generated from the encoder and the final pose from our decoder to enable joint optimization. We demonstrate comprehensive results and validate the effectiveness of our model in various tasks: 2D pose estimation, 3D pose estimation, body mesh recovery, and sparsely annotated multi-human pose estimation. Our code is available at https://github.com/KyungMinJin/HANet.
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos
Jul 28, 2022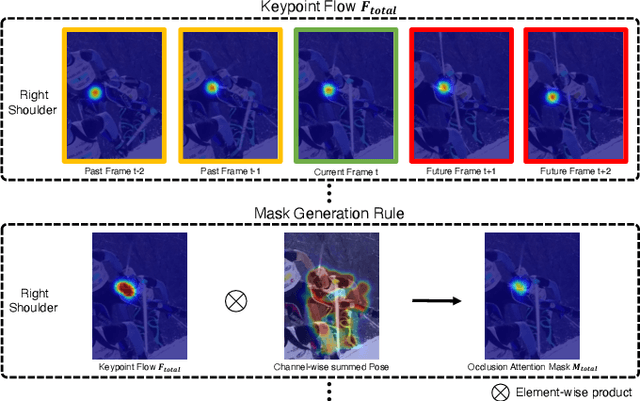
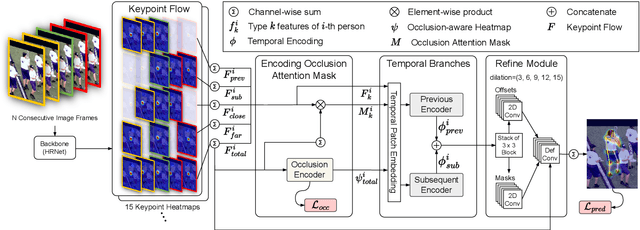
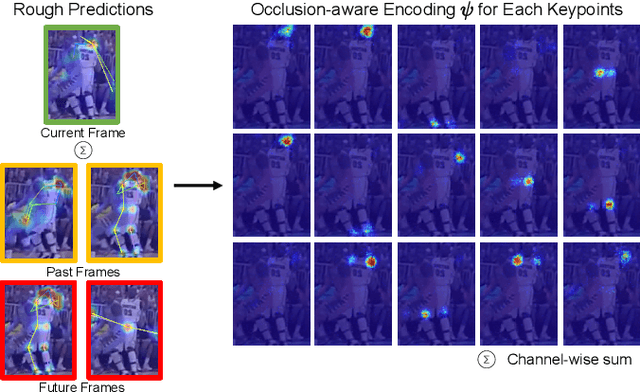
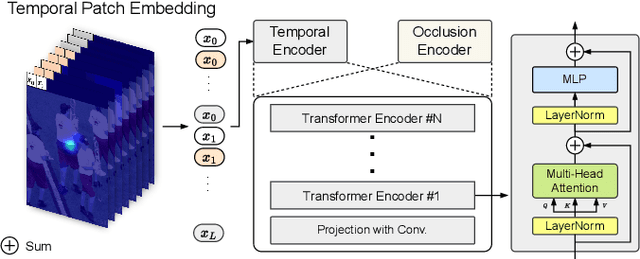
Although many approaches for multi-human pose estimation in videos have shown profound results, they require densely annotated data which entails excessive man labor. Furthermore, there exists occlusion and motion blur that inevitably lead to poor estimation performance. To address these problems, we propose a method that leverages an attention mask for occluded joints and encodes temporal dependency between frames using transformers. First, our framework composes different combinations of sparsely annotated frames that denote the track of the overall joint movement. We propose an occlusion attention mask from these combinations that enable encoding occlusion-aware heatmaps as a semi-supervised task. Second, the proposed temporal encoder employs transformer architecture to effectively aggregate the temporal relationship and keypoint-wise attention from each time step and accurately refines the target frame's final pose estimation. We achieve state-of-the-art pose estimation results for PoseTrack2017 and PoseTrack2018 datasets and demonstrate the robustness of our approach to occlusion and motion blur in sparsely annotated video data.