 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Structured Complex-Valued Hopfield Neural Networks
Mar 25, 2025In this paper, we explore the dynamics of structured complex-valued Hopfield neural networks (CvHNNs), which arise when the synaptic weight matrix possesses specific structural properties. We begin by analyzing CvHNNs with a Hermitian synaptic weight matrix and establish the existence of four-cycle dynamics in CvHNNs with skew-Hermitian weight matrices operating synchronously. Furthermore, we introduce two new classes of complex-valued matrices: braided Hermitian and braided skew-Hermitian matrices. We demonstrate that CvHNNs utilizing these matrix types exhibit cycles of length eight when operating in full parallel update mode. Finally, we conduct extensive computational experiments on synchronous CvHNNs, exploring other synaptic weight matrix structures. The findings provide a comprehensive overview of the dynamics of structured CvHNNs, offering insights that may contribute to developing improved associative memory models when integrated with suitable learning rules.
Universal Approximation Theorem for Vector- and Hypercomplex-Valued Neural Networks
Jan 04, 2024
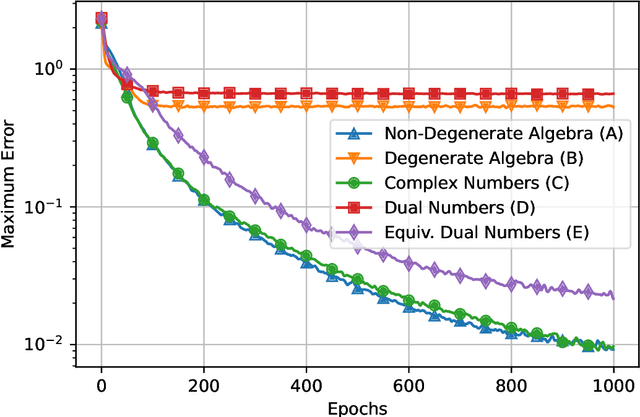

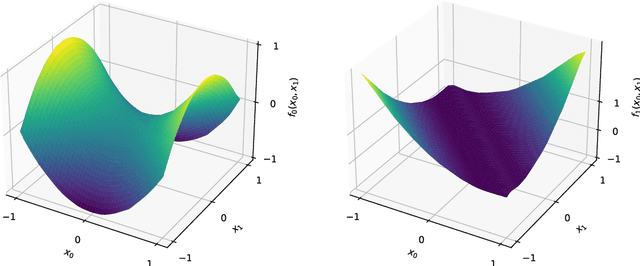
The universal approximation theorem states that a neural network with one hidden layer can approximate continuous functions on compact sets with any desired precision. This theorem supports using neural networks for various applications, including regression and classification tasks. Furthermore, it is valid for real-valued neural networks and some hypercomplex-valued neural networks such as complex-, quaternion-, tessarine-, and Clifford-valued neural networks. However, hypercomplex-valued neural networks are a type of vector-valued neural network defined on an algebra with additional algebraic or geometric properties. This paper extends the universal approximation theorem for a wide range of vector-valued neural networks, including hypercomplex-valued models as particular instances. Precisely, we introduce the concept of non-degenerate algebra and state the universal approximation theorem for neural networks defined on such algebras.
Dual Quaternion Rotational and Translational Equivariance in 3D Rigid Motion Modelling
Oct 11, 2023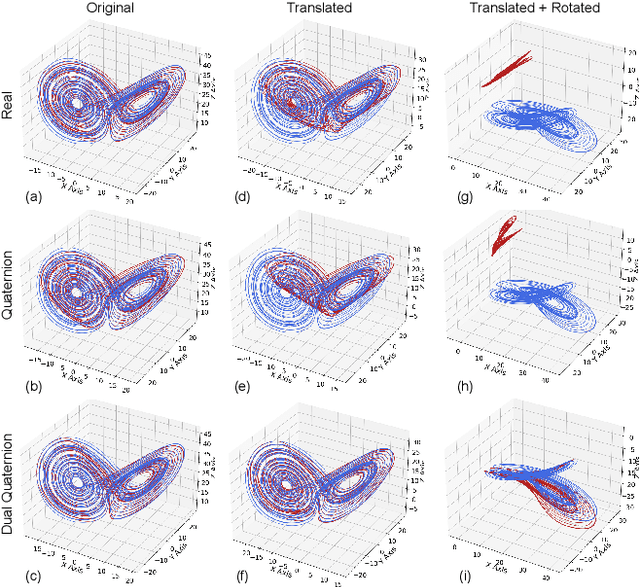

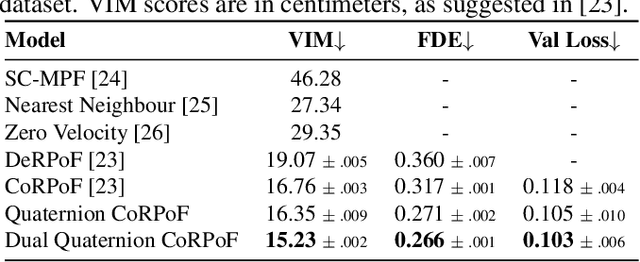
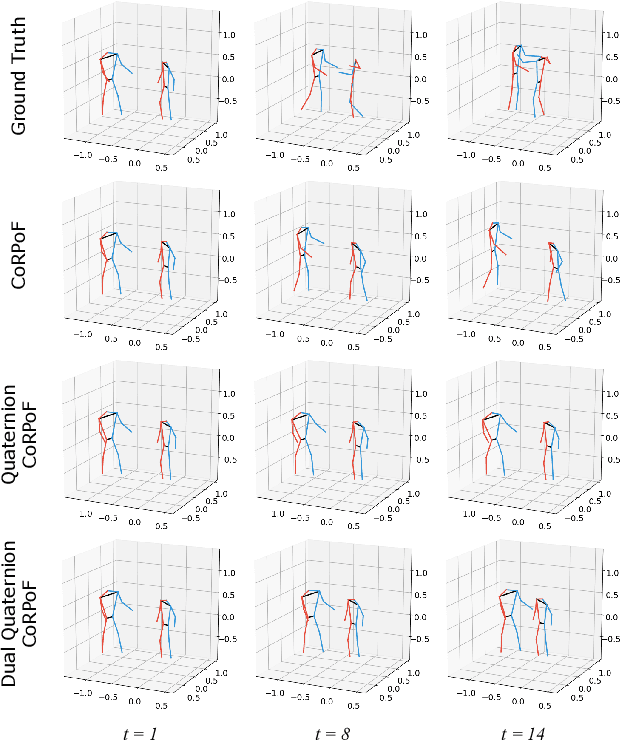
Objects' rigid motions in 3D space are described by rotations and translations of a highly-correlated set of points, each with associated $x,y,z$ coordinates that real-valued networks consider as separate entities, losing information. Previous works exploit quaternion algebra and their ability to model rotations in 3D space. However, these algebras do not properly encode translations, leading to sub-optimal performance in 3D learning tasks. To overcome these limitations, we employ a dual quaternion representation of rigid motions in the 3D space that jointly describes rotations and translations of point sets, processing each of the points as a single entity. Our approach is translation and rotation equivariant, so it does not suffer from shifts in the data and better learns object trajectories, as we validate in the experimental evaluations. Models endowed with this formulation outperform previous approaches in a human pose forecasting application, attesting to the effectiveness of the proposed dual quaternion formulation for rigid motions in 3D space.
Extending the Universal Approximation Theorem for a Broad Class of Hypercomplex-Valued Neural Networks
Sep 06, 2022The universal approximation theorem asserts that a single hidden layer neural network approximates continuous functions with any desired precision on compact sets. As an existential result, the universal approximation theorem supports the use of neural networks for various applications, including regression and classification tasks. The universal approximation theorem is not limited to real-valued neural networks but also holds for complex, quaternion, tessarines, and Clifford-valued neural networks. This paper extends the universal approximation theorem for a broad class of hypercomplex-valued neural networks. Precisely, we first introduce the concept of non-degenerate hypercomplex algebra. Complex numbers, quaternions, and tessarines are examples of non-degenerate hypercomplex algebras. Then, we state the universal approximation theorem for hypercomplex-valued neural networks defined on a non-degenerate algebra.
Acute Lymphoblastic Leukemia Detection Using Hypercomplex-Valued Convolutional Neural Networks
May 26, 2022



This paper features convolutional neural networks defined on hypercomplex algebras applied to classify lymphocytes in blood smear digital microscopic images. Such classification is helpful for the diagnosis of acute lymphoblast leukemia (ALL), a type of blood cancer. We perform the classification task using eight hypercomplex-valued convolutional neural networks (HvCNNs) along with real-valued convolutional networks. Our results show that HvCNNs perform better than the real-valued model, showcasing higher accuracy with a much smaller number of parameters. Moreover, we found that HvCNNs based on Clifford algebras processing HSV-encoded images attained the highest observed accuracies. Precisely, our HvCNN yielded an average accuracy rate of 96.6% using the ALL-IDB2 dataset with a 50% train-test split, a value extremely close to the state-of-the-art models but using a much simpler architecture with significantly fewer parameters.
A General Framework for Hypercomplex-valued Extreme Learning Machines
Jan 15, 2021



This paper aims to establish a framework for extreme learning machines (ELMs) on general hypercomplex algebras. Hypercomplex neural networks are machine learning models that feature higher-dimension numbers as parameters, inputs, and outputs. Firstly, we review broad hypercomplex algebras and show a framework to operate in these algebras through real-valued linear algebra operations in a robust manner. We proceed to explore a handful of well-known four-dimensional examples. Then, we propose the hypercomplex-valued ELMs and derive their learning using a hypercomplex-valued least-squares problem. Finally, we compare real and hypercomplex-valued ELM models' performance in an experiment on time-series prediction and another on color image auto-encoding. The computational experiments highlight the excellent performance of hypercomplex-valued ELMs to treat high-dimensional data, including models based on unusual hypercomplex algebras.