 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Distributed Nonconvex Learning with Error Feedback
Mar 18, 2025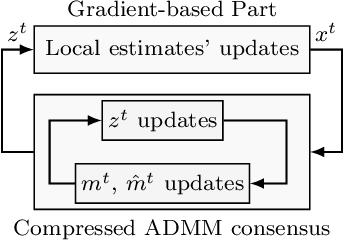
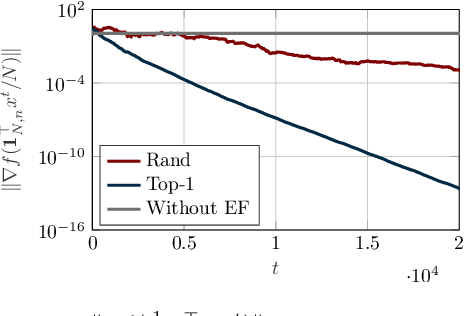
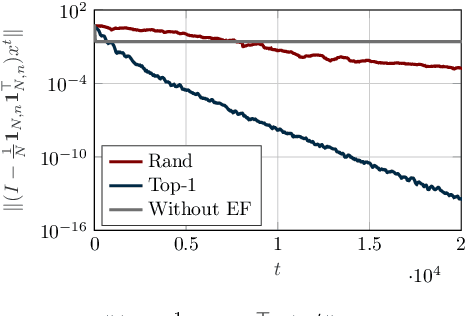
In this paper, we design a novel distributed learning algorithm using stochastic compressed communications. In detail, we pursue a modular approach, merging ADMM and a gradient-based approach, benefiting from the robustness of the former and the computational efficiency of the latter. Additionally, we integrate a stochastic integral action (error feedback) enabling almost sure rejection of the compression error. We analyze the resulting method in nonconvex scenarios and guarantee almost sure asymptotic convergence to the set of stationary points of the problem. This result is obtained using system-theoretic tools based on stochastic timescale separation. We corroborate our findings with numerical simulations in nonconvex classification.
Multi-Robot Target Monitoring and Encirclement via Triggered Distributed Feedback Optimization
Sep 30, 2024We design a distributed feedback optimization strategy, embedded into a modular ROS 2 control architecture, which allows a team of heterogeneous robots to cooperatively monitor and encircle a target while patrolling points of interest. Relying on the aggregative feedback optimization framework, we handle multi-robot dynamics while minimizing a global performance index depending on both microscopic (e.g., the location of single robots) and macroscopic variables (e.g., the spatial distribution of the team). The proposed distributed policy allows the robots to cooperatively address the global problem by employing only local measurements and neighboring data exchanges. These exchanges are performed through an asynchronous communication protocol ruled by locally-verifiable triggering conditions. We formally prove that our strategy steers the robots to a set of configurations representing stationary points of the considered optimization problem. The effectiveness and scalability of the overall strategy are tested via Monte Carlo campaigns of realistic Webots ROS 2 virtual experiments. Finally, the applicability of our solution is shown with real experiments on ground and aerial robots.
A Tutorial on Distributed Optimization for Cooperative Robotics: from Setups and Algorithms to Toolboxes and Research Directions
Sep 08, 2023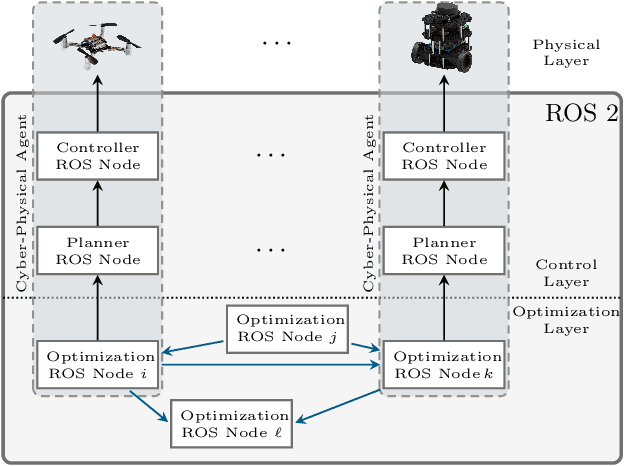
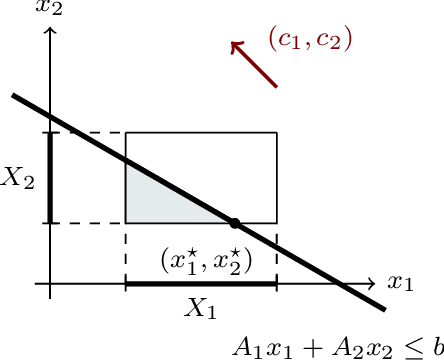
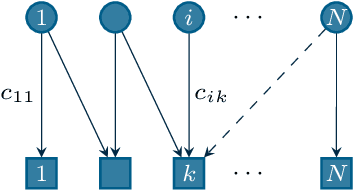
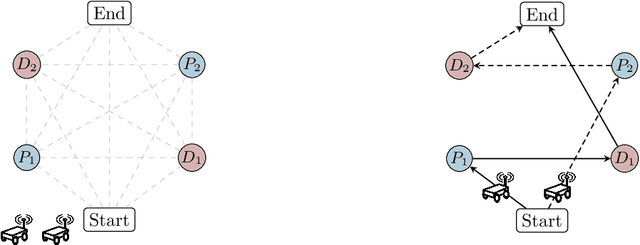
Several interesting problems in multi-robot systems can be cast in the framework of distributed optimization. Examples include multi-robot task allocation, vehicle routing, target protection and surveillance. While the theoretical analysis of distributed optimization algorithms has received significant attention, its application to cooperative robotics has not been investigated in detail. In this paper, we show how notable scenarios in cooperative robotics can be addressed by suitable distributed optimization setups. Specifically, after a brief introduction on the widely investigated consensus optimization (most suited for data analytics) and on the partition-based setup (matching the graph structure in the optimization), we focus on two distributed settings modeling several scenarios in cooperative robotics, i.e., the so-called constraint-coupled and aggregative optimization frameworks. For each one, we consider use-case applications, and we discuss tailored distributed algorithms with their convergence properties. Then, we revise state-of-the-art toolboxes allowing for the implementation of distributed schemes on real networks of robots without central coordinators. For each use case, we discuss their implementation in these toolboxes and provide simulations and real experiments on networks of heterogeneous robots.
A Distributed Online Optimization Strategy for Cooperative Robotic Surveillance
Apr 27, 2023



In this paper, we propose a distributed algorithm to control a team of cooperating robots aiming to protect a target from a set of intruders. Specifically, we model the strategy of the defending team by means of an online optimization problem inspired by the emerging distributed aggregative framework. In particular, each defending robot determines its own position depending on (i) the relative position between an associated intruder and the target, (ii) its contribution to the barycenter of the team, and (iii) collisions to avoid with its teammates. We highlight that each agent is only aware of local, noisy measurements about the location of the associated intruder and the target. Thus, in each robot, our algorithm needs to (i) locally reconstruct global unavailable quantities and (ii) predict its current objective functions starting from the local measurements. The effectiveness of the proposed methodology is corroborated by simulations and experiments on a team of cooperating quadrotors.
Distributed Online Optimization via Gradient Tracking with Adaptive Momentum
Sep 03, 2020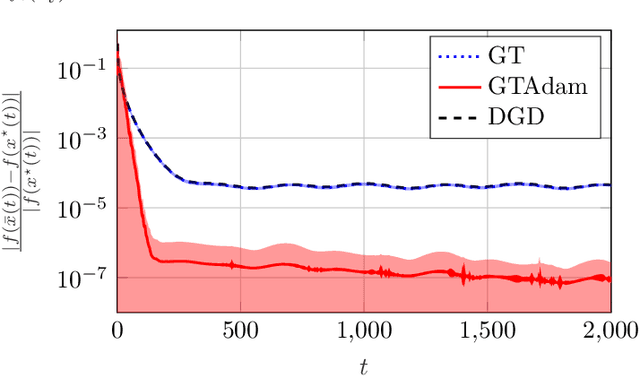
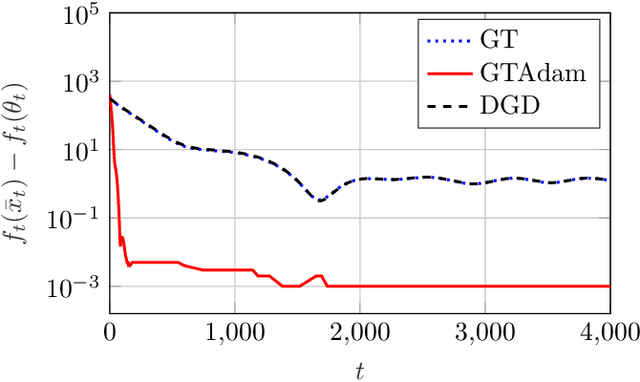
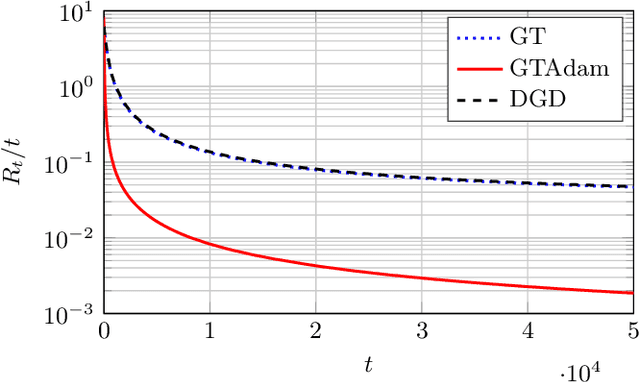
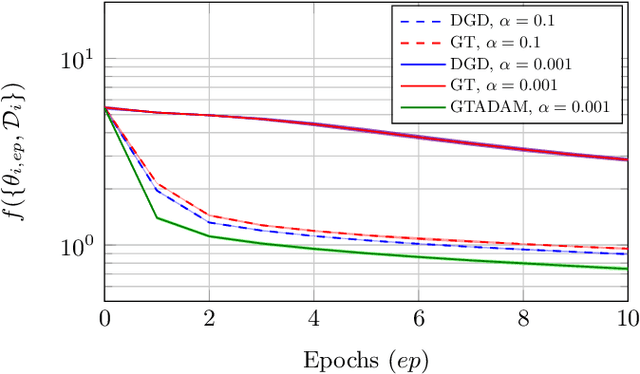
This paper deals with a network of computing agents aiming to solve an online optimization problem in a distributed fashion, i.e., by means of local computation and communication, without any central coordinator. We propose the gradient tracking with adaptive momentum estimation (GTAdam) distributed algorithm, which combines a gradient tracking mechanism with first and second order momentum estimates of the gradient. The algorithm is analyzed in the online setting for strongly convex and smooth cost functions. We prove that the average dynamic regret is bounded and that the convergence rate is linear. The algorithm is tested on a time-varying classification problem, on a (moving) target localization problem and in a stochastic optimization setup from image classification. In these numerical experiments from multi-agent learning, GTAdam outperforms state-of-the-art distributed optimization methods.