 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchievement and Fragility of Long-term Equitability
Jun 24, 2022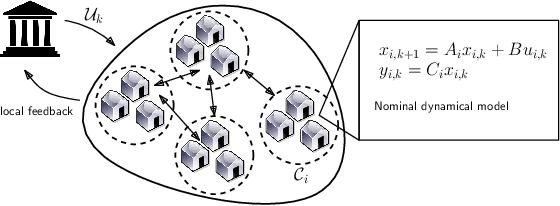
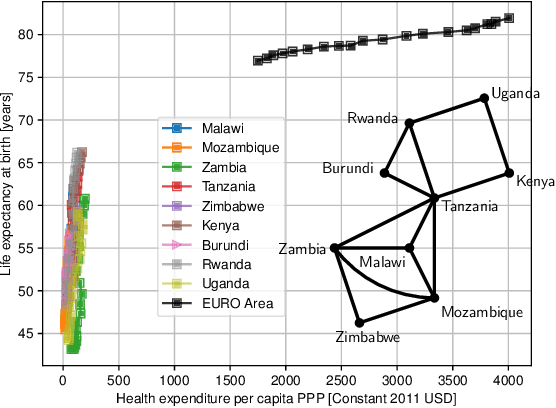
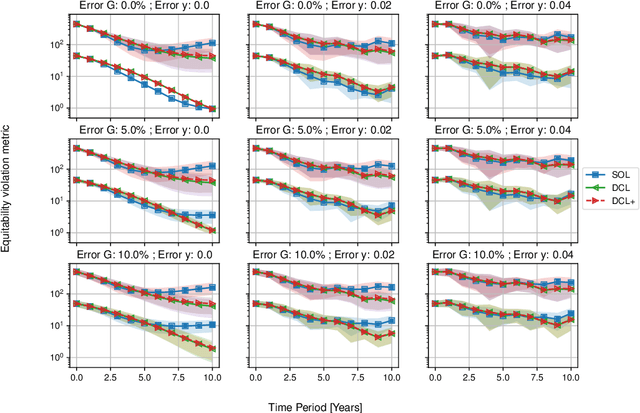
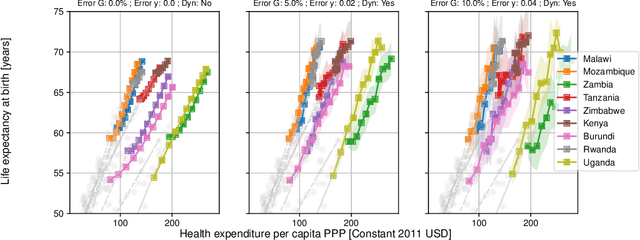
Equipping current decision-making tools with notions of fairness, equitability, or other ethically motivated outcomes, is one of the top priorities in recent research efforts in machine learning, AI, and optimization. In this paper, we investigate how to allocate limited resources to {locally interacting} communities in a way to maximize a pertinent notion of equitability. In particular, we look at the dynamic setting where the allocation is repeated across multiple periods (e.g., yearly), the local communities evolve in the meantime (driven by the provided allocation), and the allocations are modulated by feedback coming from the communities themselves. We employ recent mathematical tools stemming from data-driven feedback online optimization, by which communities can learn their (possibly unknown) evolution, satisfaction, as well as they can share information with the deciding bodies. We design dynamic policies that converge to an allocation that maximize equitability in the long term. We further demonstrate our model and methodology with realistic examples of healthcare and education subsidies design in Sub-Saharian countries. One of the key empirical takeaways from our setting is that long-term equitability is fragile, in the sense that it can be easily lost when deciding bodies weigh in other factors (e.g., equality in allocation) in the allocation strategy. Moreover, a naive compromise, while not providing significant advantage to the communities, can promote inequality in social outcomes.
* 12 pages, 7 figures
Distributed Online Optimization via Gradient Tracking with Adaptive Momentum
Sep 03, 2020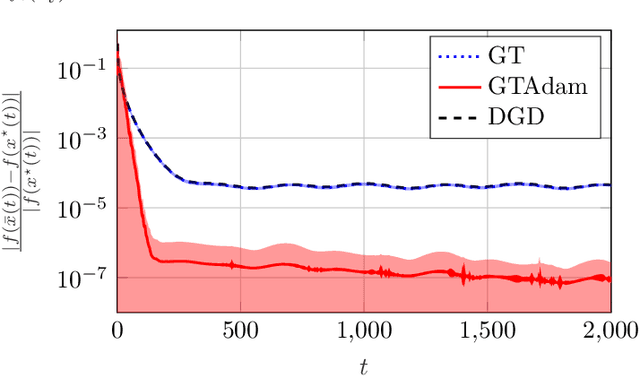
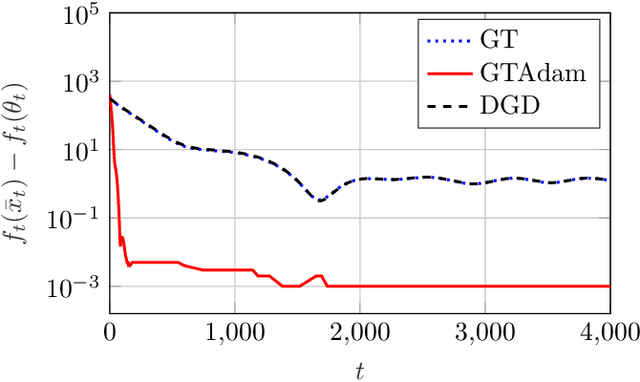
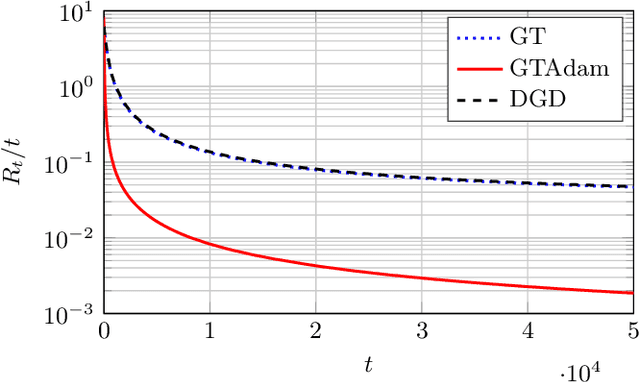
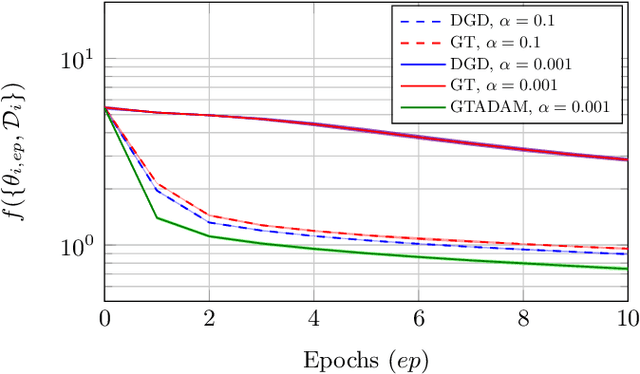
This paper deals with a network of computing agents aiming to solve an online optimization problem in a distributed fashion, i.e., by means of local computation and communication, without any central coordinator. We propose the gradient tracking with adaptive momentum estimation (GTAdam) distributed algorithm, which combines a gradient tracking mechanism with first and second order momentum estimates of the gradient. The algorithm is analyzed in the online setting for strongly convex and smooth cost functions. We prove that the average dynamic regret is bounded and that the convergence rate is linear. The algorithm is tested on a time-varying classification problem, on a (moving) target localization problem and in a stochastic optimization setup from image classification. In these numerical experiments from multi-agent learning, GTAdam outperforms state-of-the-art distributed optimization methods.