 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-Based Approach to Alert Contextualisation in Security Operations Centres
Sep 16, 2025



Interpreting the massive volume of security alerts is a significant challenge in Security Operations Centres (SOCs). Effective contextualisation is important, enabling quick distinction between genuine threats and benign activity to prioritise what needs further analysis.This paper proposes a graph-based approach to enhance alert contextualisation in a SOC by aggregating alerts into graph-based alert groups, where nodes represent alerts and edges denote relationships within defined time-windows. By grouping related alerts, we enable analysis at a higher abstraction level, capturing attack steps more effectively than individual alerts. Furthermore, to show that our format is well suited for downstream machine learning methods, we employ Graph Matching Networks (GMNs) to correlate incoming alert groups with historical incidents, providing analysts with additional insights.
LLM-Powered Intent-Based Categorization of Phishing Emails
Jun 17, 2025Phishing attacks remain a significant threat to modern cybersecurity, as they successfully deceive both humans and the defense mechanisms intended to protect them. Traditional detection systems primarily focus on email metadata that users cannot see in their inboxes. Additionally, these systems struggle with phishing emails, which experienced users can often identify empirically by the text alone. This paper investigates the practical potential of Large Language Models (LLMs) to detect these emails by focusing on their intent. In addition to the binary classification of phishing emails, the paper introduces an intent-type taxonomy, which is operationalized by the LLMs to classify emails into distinct categories and, therefore, generate actionable threat information. To facilitate our work, we have curated publicly available datasets into a custom dataset containing a mix of legitimate and phishing emails. Our results demonstrate that existing LLMs are capable of detecting and categorizing phishing emails, underscoring their potential in this domain.
Exploring reinforcement learning for incident response in autonomous military vehicles
Oct 28, 2024



Unmanned vehicles able to conduct advanced operations without human intervention are being developed at a fast pace for many purposes. Not surprisingly, they are also expected to significantly change how military operations can be conducted. To leverage the potential of this new technology in a physically and logically contested environment, security risks are to be assessed and managed accordingly. Research on this topic points to autonomous cyber defence as one of the capabilities that may be needed to accelerate the adoption of these vehicles for military purposes. Here, we pursue this line of investigation by exploring reinforcement learning to train an agent that can autonomously respond to cyber attacks on unmanned vehicles in the context of a military operation. We first developed a simple simulation environment to quickly prototype and test some proof-of-concept agents for an initial evaluation. This agent was then applied to a more realistic simulation environment and finally deployed on an actual unmanned ground vehicle for even more realism. A key contribution of our work is demonstrating that reinforcement learning is a viable approach to train an agent that can be used for autonomous cyber defence on a real unmanned ground vehicle, even when trained in a simple simulation environment.
On the use of neurosymbolic AI for defending against cyber attacks
Aug 09, 2024It is generally accepted that all cyber attacks cannot be prevented, creating a need for the ability to detect and respond to cyber attacks. Both connectionist and symbolic AI are currently being used to support such detection and response. In this paper, we make the case for combining them using neurosymbolic AI. We identify a set of challenges when using AI today and propose a set of neurosymbolic use cases we believe are both interesting research directions for the neurosymbolic AI community and can have an impact on the cyber security field. We demonstrate feasibility through two proof-of-concept experiments.
Automating change of representation for proofs in discrete mathematics
May 10, 2015
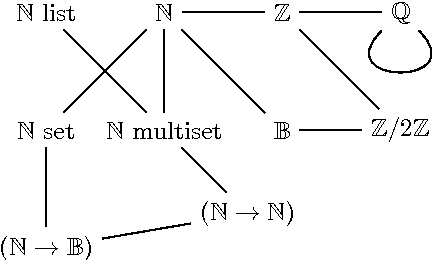

Representation determines how we can reason about a specific problem. Sometimes one representation helps us find a proof more easily than others. Most current automated reasoning tools focus on reasoning within one representation. There is, therefore, a need for the development of better tools to mechanise and automate formal and logically sound changes of representation. In this paper we look at examples of representational transformations in discrete mathematics, and show how we have used Isabelle's Transfer tool to automate the use of these transformations in proofs. We give a brief overview of a general theory of transformations that we consider appropriate for thinking about the matter, and we explain how it relates to the Transfer package. We show our progress towards developing a general tactic that incorporates the automatic search for representation within the proving process.
Machine Learning in Proof General: Interfacing Interfaces
Jul 08, 2013



We present ML4PG - a machine learning extension for Proof General. It allows users to gather proof statistics related to shapes of goals, sequences of applied tactics, and proof tree structures from the libraries of interactive higher-order proofs written in Coq and SSReflect. The gathered data is clustered using the state-of-the-art machine learning algorithms available in MATLAB and Weka. ML4PG provides automated interfacing between Proof General and MATLAB/Weka. The results of clustering are used by ML4PG to provide proof hints in the process of interactive proof development.
* In Proceedings UITP 2012, arXiv:1307.1528
Towards Automated Proof Strategy Generalisation
Jun 09, 2013



The ability to automatically generalise (interactive) proofs and use such generalisations to discharge related conjectures is a very hard problem which remains unsolved. Here, we develop a notion of goal types to capture key properties of goals, which enables abstractions over the specific order and number of sub-goals arising when composing tactics. We show that the goal types form a lattice, and utilise this property in the techniques we develop to automatically generalise proof strategies in order to reuse it for proofs of related conjectures. We illustrate our approach with an example.