 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Negatives in Contrastive Learning for Unpaired Image-to-Image Translation
Apr 23, 2022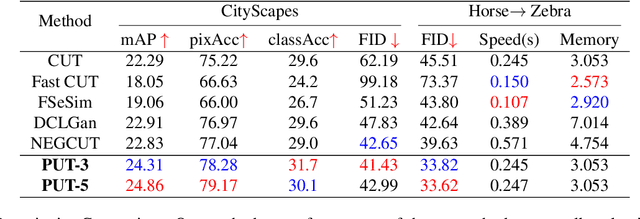



Unpaired image-to-image translation aims to find a mapping between the source domain and the target domain. To alleviate the problem of the lack of supervised labels for the source images, cycle-consistency based methods have been proposed for image structure preservation by assuming a reversible relationship between unpaired images. However, this assumption only uses limited correspondence between image pairs. Recently, contrastive learning (CL) has been used to further investigate the image correspondence in unpaired image translation by using patch-based positive/negative learning. Patch-based contrastive routines obtain the positives by self-similarity computation and recognize the rest patches as negatives. This flexible learning paradigm obtains auxiliary contextualized information at a low cost. As the negatives own an impressive sample number, with curiosity, we make an investigation based on a question: are all negatives necessary for feature contrastive learning? Unlike previous CL approaches that use negatives as much as possible, in this paper, we study the negatives from an information-theoretic perspective and introduce a new negative Pruning technology for Unpaired image-to-image Translation (PUT) by sparsifying and ranking the patches. The proposed algorithm is efficient, flexible and enables the model to learn essential information between corresponding patches stably. By putting quality over quantity, only a few negative patches are required to achieve better results. Lastly, we validate the superiority, stability, and versatility of our model through comparative experiments.
Exploring Semi-Automatic Map Labeling
Oct 17, 2019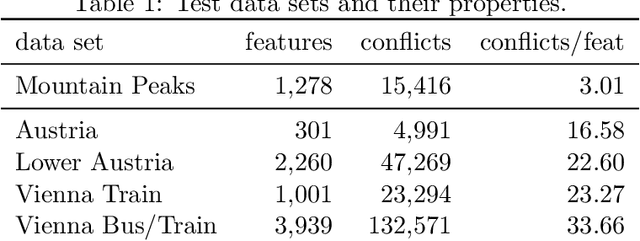
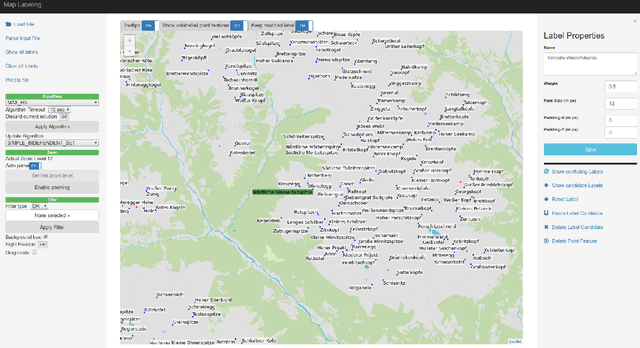

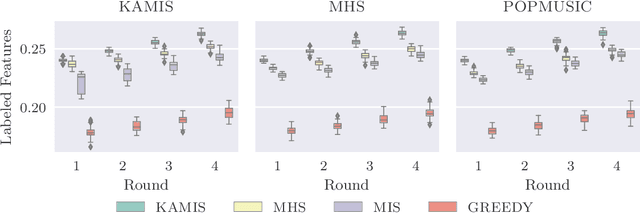
Label placement in maps is a very challenging task that is critical for the overall map quality. Most previous work focused on designing and implementing fully automatic solutions, but the resulting visual and aesthetic quality has not reached the same level of sophistication that skilled human cartographers achieve. We investigate a different strategy that combines the strengths of humans and algorithms. In our proposed method, first an initial labeling is computed that has many well-placed labels but is not claiming to be perfect. Instead it serves as a starting point for an expert user who can then interactively and locally modify the labeling where necessary. In an iterative human-in-the-loop process alternating between user modifications and local algorithmic updates and refinements the labeling can be tuned to the user's needs. We demonstrate our approach by performing different possible modification steps in a sample workflow with a prototypical interactive labeling editor. Further, we report computational performance results from a simulation experiment in QGIS, which investigates the differences between exact and heuristic algorithms for semi-automatic map labeling. To that end, we compare several alternatives for recomputing the labeling after local modifications and updates, as a major ingredient for an interactive labeling editor.