 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Public Information Precoding for MIMO Visible Light Communication System Based on Manifold Optimization
Sep 09, 2023



Visible light communication (VLC) is an attractive subset of optical communication that provides a high data rate in the access layer of the network. The combination of multiple inputmultiple output (MIMO) with a VLC system leads to a higher speed of data transmission named as MIMO-VLC system. In multi-user (MU) MIMO-VLC, a LED array transmits signals for users. These signals are categorized as signals of private information for each user and signals of public information for all users. The main idea of this paper is to design an omnidirectional precoding to transmit the signals of public information in the MUMIMO-VLC network. To this end, we propose to maximize the achievable rate which leads to maximizing the received mean power at the possible location of the users. Besides maximizing the achievable rate, we consider equal mean transmission power constraint in all LEDs to achieve higher power efficiency of the power amplifiers used in the LED array. Based on this we formulate an optimization problem in which the constraint is in the form of a manifold and utilize a gradient method projected on the manifold to solve the problem. Simulation results indicate that the proposed omnidirectional precoding can achieve superior received mean power and bit error rate with respect to the classical form without precoding utilization.
Multi-Agent Deep Reinforcement Learning for Cost- and Delay-Sensitive Virtual Network Function Placement and Routing
Jun 24, 2022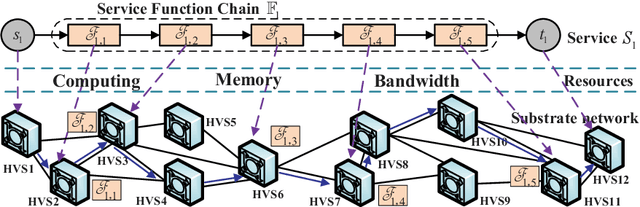
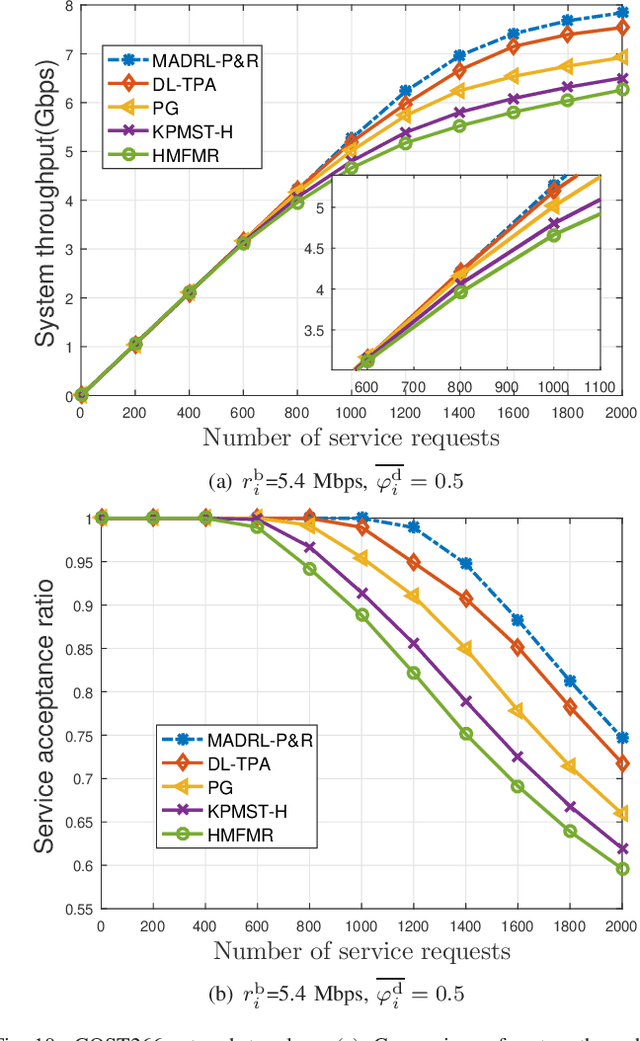
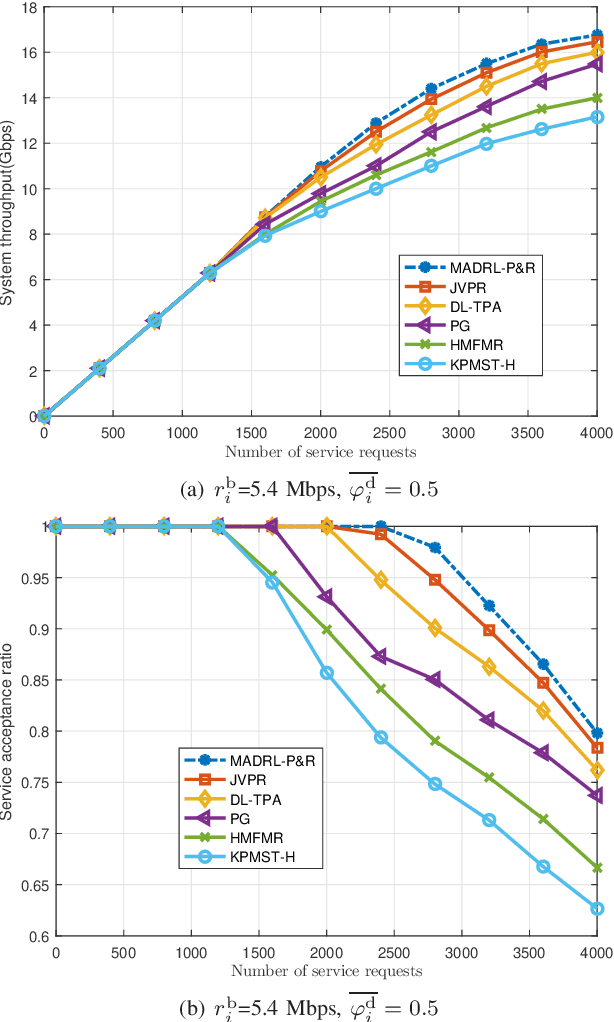
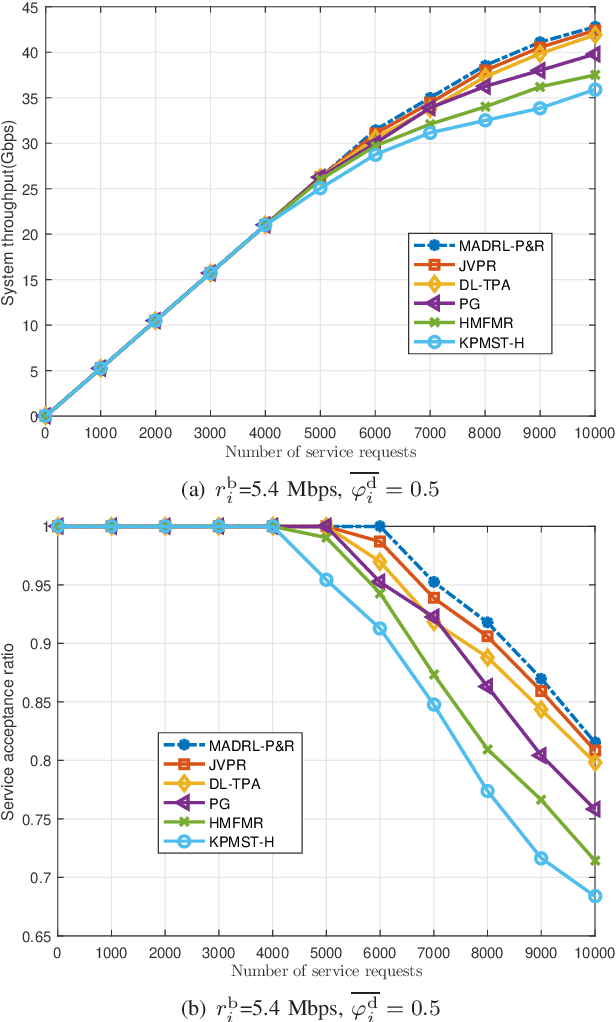
This paper proposes an effective and novel multiagent deep reinforcement learning (MADRL)-based method for solving the joint virtual network function (VNF) placement and routing (P&R), where multiple service requests with differentiated demands are delivered at the same time. The differentiated demands of the service requests are reflected by their delay- and cost-sensitive factors. We first construct a VNF P&R problem to jointly minimize a weighted sum of service delay and resource consumption cost, which is NP-complete. Then, the joint VNF P&R problem is decoupled into two iterative subtasks: placement subtask and routing subtask. Each subtask consists of multiple concurrent parallel sequential decision processes. By invoking the deep deterministic policy gradient method and multi-agent technique, an MADRL-P&R framework is designed to perform the two subtasks. The new joint reward and internal rewards mechanism is proposed to match the goals and constraints of the placement and routing subtasks. We also propose the parameter migration-based model-retraining method to deal with changing network topologies. Corroborated by experiments, the proposed MADRL-P&R framework is superior to its alternatives in terms of service cost and delay, and offers higher flexibility for personalized service demands. The parameter migration-based model-retraining method can efficiently accelerate convergence under moderate network topology changes.